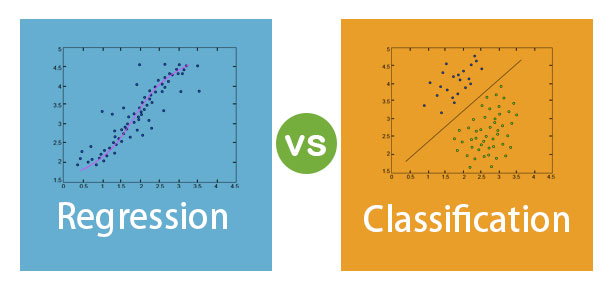
Difference Between Regression and Classification
In this article, Regression vs Classification, let us discuss the key differences between Regression and Classification. Machine Learning is broadly divided into two types they are Supervised machine learning and Unsupervised machine learning. In supervised machine learning, we have a known output value in the data set, and we train the model based on these and use it for prediction, whereas in unsupervised machine learning, we don’t have a known set of output values. In advance, to differentiate between Classification and Regression, let us understand what does this terminology means in Machine Learning. Regression is an algorithm in supervised machine learning that can be trained to predict real number outputs. Classification is an algorithm in supervised machine learning that is trained to identify categories and predict in which category they fall for new values.
Head to Head Comparison between Regression and Classification (Infographics)
Below is the Top 5 Comparison between Regression vs Classification:
Key differences between Regression and Classification
Let us discuss some key differences between Regression vs Classification in the following points:
- Classification is all about predicting a label or category. Classification algorithm classifies the required data set into one or more labels; an algorithm that deals with two classes or categories is known as a binary classifier. If there are more than two classes, then it can be called a multi-class classification algorithm.
- Regression is about finding an optimal function for identifying the data of continuous real values and make predictions of that quantity. Regression with multiple variables as input or features to train the algorithm is known as a multivariate regression problem. If in the regression problem, input values are dependent or ordered by time then it is known as time series forecasting problem.
- However, the Classification model will also predict a continuous value that is the probability of happening the event belonging to that respective output class. Here the probability of event represents the likeliness of a given example belonging to a specific class. The predicted probability value can be converted into a class value by selecting the class label that has the highest probability.
- Let us understand this better by seeing an example, assume we are training the model to predict if a person is having cancer or not based on some features. If we get the probability of a person having cancer as 0.8 and not having cancer as 0.2, we may convert the 0.8 probability to a class label having cancer as it is having the highest probability.
- As mentioned above in classification to see how good the classification model is performing we calculate accuracy. Let us see how the calculation is performed, accuracy in classification can be performed by taking the ratio of correct predictions to total predictions multiplied by 100. If there are 50 predictions done and 10 of them are correct and 40 are incorrect then accuracy will be 20%.
Accuracy = (Number of correct predictions / Total number of predictions) * (100)
- Accuracy = (10/50) * (100)
- Accuracy = 20%
- As mentioned above in regression, to see how good the regression model is performing the most popular way is to calculate root mean square error (RMSE). Let us see how the calculation will be performed.
The regression model predicted value is 4.9 whereas the actual value is 5.3.
The regression model predicted value is 2.3 whereas the actual value is 2.1.
The regression model predicted value is 3.4 whereas the actual value is 2.9.
Now, Root means square error can be calculated by using the formula.
Error squared is (5.3-4.9)^2 = 0.16, (2.1-2.3)^2 = 0.04, (2.9-3.4)^2 = 0.25
Mean of the Error Squared = 0.45/3 = 0.15
Root mean square error = square root of 0.15 = 0.38
That is RMSE = 0.38. There are many other methods to calculate the efficiency of the model but RMSE is the most used because RMSE offers the error score in the same units as the predicted value.
Examples:
Most data scientist engineers find it difficult to choose one between regression and classification in the starting stage of their careers. To make it easy let us see how the classification problems look like and how the regression problems look like,
Classification
- Predicting whether it will rain or not tomorrow.
- Predicting a person should buy that good or not to make a profit.
- Predicting if a person has a disease or not.
If you notice for each situation here there can be either a Yes or No as an output predicted value.
Regression
- Predicting the price of land.
- Predicting the price of stock.
If you notice for each situation here most of them have numerical value as predicted output.
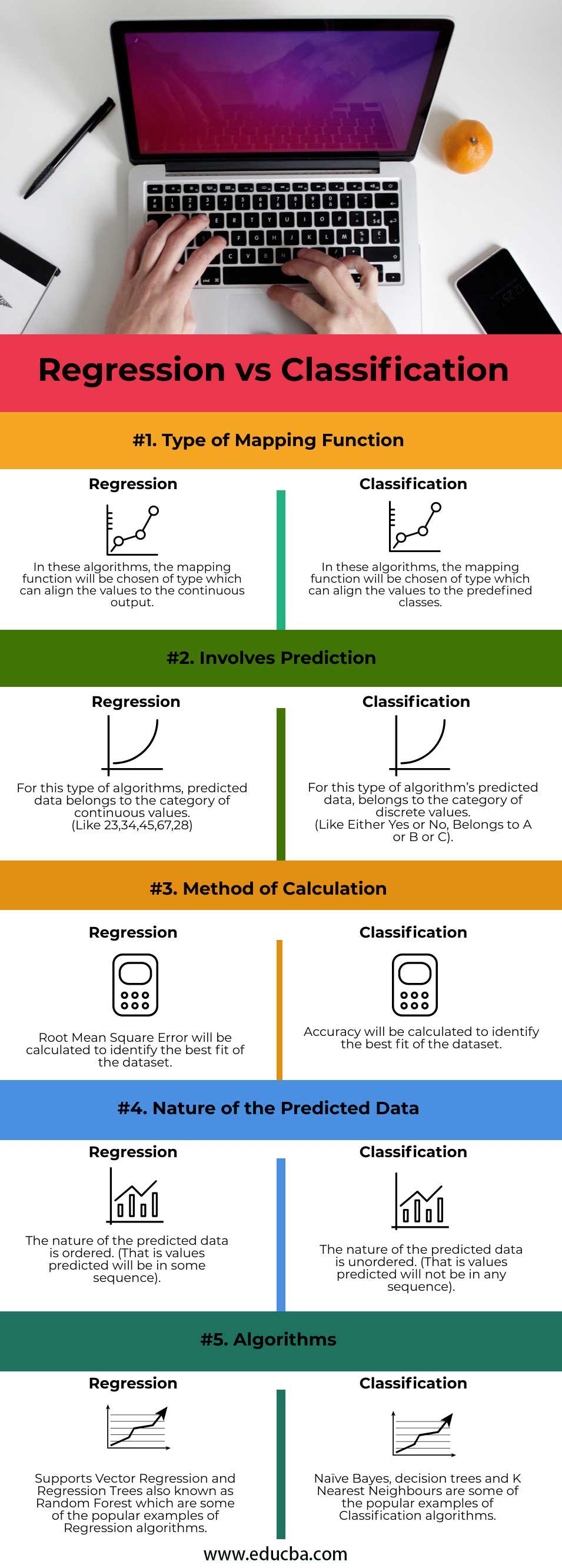
Comparison Table of Regression vs Classification
The table below summarizes the comparisons between Regression vs Classification:
| Parameter | Regression |
Classification |
| Type of Mapping Function | In these algorithms, the mapping function will be chosen of type which can align the values to the continuous output. | In these algorithms, the mapping function will be chosen of type which can align the values to the predefined classes. |
| Involves Prediction | For this type of algorithms, predicted data belongs to the category of continuous values.
(Like 23,34,45,67,28) |
For this type of algorithm’s predicted data, belongs to the category of discrete values.
(Like Either Yes or No, Belongs to A or B or C). |
| Method of Calculation | Root Mean Square Error will be calculated to identify the best fit of the dataset. | Accuracy will be calculated to identify the best fit of the dataset. |
| Nature of the Predicted Data | The nature of the predicted data is ordered. (That is values predicted will be in some sequence). | The nature of the predicted data is unordered. (That is values predicted will not be in any sequence). |
| Algorithms | Supports Vector Regression and Regression Trees are also known as Random Forest which are some of the popular examples of Regression algorithms. | Naive Bayes, decision trees and K Nearest Neighbours are some of the popular examples of Classification algorithms. |
Conclusion
These are some of the key differences between classification and regression. In some cases, the continuous output values predicted in regression can be grouped into labels and change into classification models. So, we have to understand clearly which one to choose based on the situation and what we want the predicted output to be.
Recommended Articles
This is a guide to the top difference between Regression vs Classification. Here we also discuss the key differences with infographics, and comparison table. You may also have a look at the following articles to learn more –
