Updated May 3, 2023
Difference Between Random forest vs Gradient boosting
Random forest vs gradient boosting is defined as the random forest is an ensemble learning method that is used to solve classification and regression problems; it has two steps; its first step involves the bootstrapping technique for training and testing, and the second step requires decision trees for prediction purpose, whereas, Gradient boosting is defined as the machine learning technique which is also used to solve regression and classification problems, it creates a model in a stepwise manner, it is derived by optimizing an objective function we can combine a group of a weak learning model with building a single strong learner.
Head-to-Head Comparison Between Random Forest vs Gradient Boosting (Infographics)
Below are the top differences between Random forest vs Gradient boosting:
Key Differences
- Performance:
There are two differences in the performance between random forest and Gradient boosting: the random forest can build each tree independently. On the other hand, Gradient boosting can make one tree at a time so that the performance of the random forest is less compared to the Gradient boosting; another difference is random forest combines its result at the end of the process while Gradient combines the result along the way of it.
- Bagging vs boosting:
The combining of decision trees is the main difference between random forest and Gradient boosting; the random forest has been built by using the bagging method, the bagging method is the method in which each decision tree is used in parallel, and each decision tree in it can fit subsample which has been taken from the entire dataset, in case of classification result is determined by taking all the result of decision trees and for regression tasks, the overall result is calculated by taking the mean of all predictions, on the other hand, Gradient boosting uses the boosting technique to build an ensemble model, to build a new strong tree the decision trees are connected in series in which decision tree is not fit into the entire dataset.
- Overfitting:
Overfitting is a critical issue in machine learning techniques; as we know, in machine learning, we use algorithms so that there is a risk of overfitting, and that can be considered a bottleneck in machine learning when any model fits the training data well than there may occur overfitting due to that our model can take some unnecessary details under the training data. So it fails to generalize to the entire data.
As we have seen above, the random forest and Gradient boosting are both ensemble learning models; the random forest uses several decision trees that are not critical or do not cause overfitting; if we add more trees to it, then the accuracy of the model will decrease so we do not want to add more trees; hence there may occur computational reason, but in the random forest, there is no risk of overfitting, whereas, in Gradient boosting due to the number of trees may appear overfitting, in Gradient the new tree has been added from remaining to the previous one so each addition may occur noise in training data so adding of many trees in Gradient boosting will cause the overfitting.
- Bootstrapping:
Bootstrapping is the technique that is used in statistics; it uses a sample of data to make predictive data; each sample of data is called the bootstrap sample; in the random forest, if we do not use the bootstrapping technique, then each decision tree fits into the dataset due to that many algorithms will be applied to the same dataset it does well in manner, as we are doing it repeatedly; as a result, it gives better performance, if we use same or different decision trees then the result we get will not significantly different as compared to the result we get by single decision tree hence bootstrapping plays an essential role in creating different decision trees, whereas, Gradient boosting does not use the bootstrapping technique each decision tree in it fits into the remaining to the previous one, so it does not work well with which has different trees.
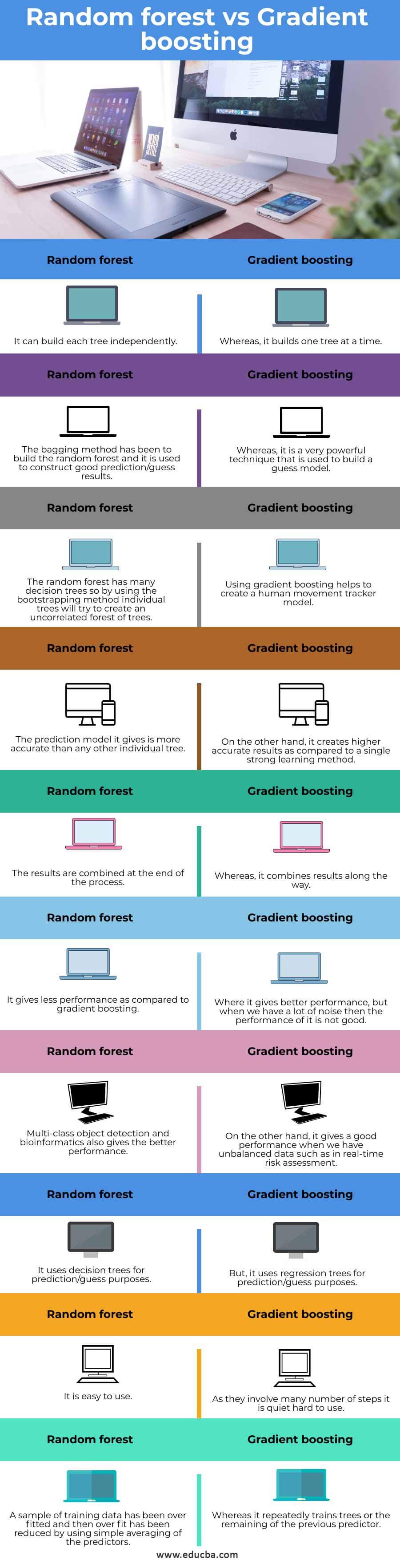
Comparison Table of Random Forest vs Gradient Boosting
| Sr.no | Random forest | Gradient boosting |
| 1. | It can build each tree independently. | Whereas it builds one tree at a time. |
| 2. | The bagging method has been used to build the random forest and to construct good prediction/guess results. | Whereas it is a powerful technique used to build a guess model. |
| 3. | The random forest has many decision trees, so using the bootstrapping method, individual trees will try to create an uncorrelated forest of trees. | Using gradient boosting helps to create a human movement tracker model. |
| 4. | The prediction model it gives is more accurate than any other individual tree. | On the other hand, it creates higher accurate results than a single robust learning method. |
| 5. | At the end of the process, we combine the results. | Whereas it combines results along the way. |
| 6. | It gives less performance as compared to gradient boosting. | Where it gives better performance, but when we have a lot of noise, then the performance of it is not good. |
| 7. | Multi-class object detection and bioinformatics also give better performance. | On the other hand, it performs well when we have unbalanced data, such as in real-time risk assessment. |
| 8. | It uses decision trees for prediction/guess purposes. | But, it uses regression trees for prediction/guess purposes. |
| 9. | It is easy to use. | As they involve many steps, it is pretty hard to use. |
| 10. | We reduced overfitting in a sample of training data by simply averaging the predictors. | Whereas it repeatedly trains trees or the remaining of the previous predictor. |
Conclusion
In this article, we conclude that random forest and Gradient boosting both have very efficient algorithms that use regression and classification to solve problems. Also, overfitting does not occur in the random forest but in Gradient boosting algorithms due to adding several new trees.
Recommended Articles
This is a guide to Random forest vs Gradient boosting. Here we discuss the Random forest vs Gradient boosting key differences with infographics and a comparison table. You may also have a look at the following articles to learn more –
