Updated April 4, 2023

Introduction to PyTorch Parameter
The PyTorch parameter is a layer made up of nn or a module. A parameter that is assigned as an attribute inside a custom model is registered as a model parameter and is thus returned by the caller model.parameters(). We can say that a Parameter is a wrapper over Variables that are formed.
What is the PyTorch parameter?
When used with Modules, parameters are Tensor subclasses with a unique property: when given as Module attributes, they are immediately put on the list of a component’s parameters. A PyTorch Tensor is fundamentally similar to a NumPy array: a Tensor is an n-dimensional array, and PyTorch includes several methods for working with them.
How to Use the PyTorch parameter?
Every time we build a model, we include some layers as elements that change our data. As a result, we could see the model’s setup when we generated the overview of our model. However, there are situations when we need a tensor as a parameter in a module. For instance, learnable initial states for RNNs, the input image tensor when doing neural style transfer, and now even the connection weights of a layer, to name a few examples. This is impossible to perform with either Tensor (because of the lack of gradient) or Variable (as they are not module parameters). The parameter keyword is used to accomplish this.
I am using the below Statement for module parameters.
class Parameter(torch.Tensor):The parameters are as follows: class:`~torch. Subclasses of Tensor that have a unique characteristic when combined with Once they’re assigned as Component attributes, they’re immediately included in the list of the module’s parameters.
When designing neural networks, we typically consider layering the computation, with some levels having learnable parameters that will be tuned during the learning process. The nn package in PyTorch does the same thing. The nn package specifies the number of Modules that are pretty similar to the tiers of a neural network.
weight = torch.nn.Parameter(torch.FloatTensor(3,3))The preceding statement demonstrates how to construct a module parameter with nn.Parameter(). We can see that weight is formed with a specified tensor, implying that the weight’s initialized value should be the same as the tensor torch. FloatTensor(3,3).
Parameter In PyTorch Functions
__init__ and forward are two main functions that must be used while creating a model. All of our parametric layers are instantiated at __init__.
PyTorch has several typical loss functions that you can use in the torch. Module nn.
loss_fn = nn.CrossEntropyLoss()
ls = loss_fn(out, target)The model parameters that need to be modified for each iteration are passed here. More complicated approaches, such as per-layer or even per-parameter training rates, can also be specified. Calling optimizer.step() after computing gradients with loss.backward() modifies the values as stated by the optimization algorithm.
For an SGD optimizer
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)For an ADAM
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0001Let’s take apply(fn)
Iteratively implements fn to all submodules (as returned by. children()) and self.
@torch.no_grad()
def init_weights(k):
print(k)
if type(k) == nn.Linear:
k.weight.fill_(1.2)
print(k.weight)
net = nn.Sequential(nn.Linear(3, 3), nn.Linear(3, 3))
net.apply(init_weights)
Linear(in_features=3, out_features=3, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Linear(in_features=3, out_features=3, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Sequential(
(0): Linear(in_features=3, out_features=3, bias=True)
(1): Linear(in_features=3, out_features=3, bias=True)
)
Sequential(
(0): Linear(in_features=3, out_features=3, bias=True)
(1): Linear(in_features=3, out_features=3, bias=True)
)Sample code:
def __set_readout(self, readout_def, args):
self.r_definition = readout_def.lower()
self.r_function = {
'duvenaud': self.r_duvenaud,
'ggnn': self.r_ggnn,
'intnet': self.r_intnet,
'mpnn': self.r_mpnn
}.get(self.r_definition, None)
if self.r_function is None:
print('Alert : Read function is not done correctly\n\tIncorrect definition ' + readout_def)
quit()
init_parameters = {
'duvenaud': self.init_duvenaud,
'ggnn': self.init_ggnn,
'intnet': self.init_intnet,
'mpnn': self.init_mpnn
}.get(self.r_definition, lambda x: (nn.ParameterList([]), nn.ModuleList([]), {}))
self.learn_args, self.learn_modules, self.args = init_parameters(args)PyTorch parameter Model
The model. parameters() is used to iteratively retrieve all of the arguments and may thus be passed to an optimizer. Although PyTorch does not have a function to determine the parameters, the number of items for each parameter category can be added.
Pytorch_total_params=sum(p.nume1) for p in model.parameters())model. named parameters() provide an iterator that includes both the parameter label and the parameter.
Let’s see a sample code here with the parameters
from prettytable import PrettyTable
def count_parameters(model):
table = PrettyTable(["Mod name", "Parameters Listed"])
t_params = 0
for name, parameter in model.named_parameters():
if not parameter.requires_grad: continue
param = parameter.numel()
table.add_row([name, param])
t_params+=param
print(table)
print(f"Sum of trained paramters: {t_params}")
return t_params
count_parameters(net)The Output would be like this:
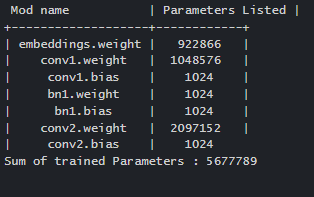
To summarise, nn.Parameter() accepts the tensor that is supplied to it and does not perform any preliminary process, including uniformization. That implies the argument will be empty or uninitialized if the tensor handed in is blank or uninitialized.
class net(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Linear(11,4)
def forward(self, y):
return self.linear(y)
myNet = net()
print(list(myNet.parameters()))Example #2
The nn package is used to create our two-layer network in this illustration:
Here Every Linear Module uses a linear function to generate outcomes from input and keeps internal Factors for connection weights. Since each Module’s parameters are kept in a Variable factor with requires grad=True, this call will generate gradients with all trainable model parameters.
import torch
from torch.autograd import Variable
N, D_in, H, D_out = 64, 1000, 100, 10
a = Variable(torch.randn(N, D_in))
b = Variable(torch.randn(N, D_out), requires_grad=False)
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
loss_fn = torch.nn.MSELoss(size_average=False)
learning_rate = 1e-4
for te in range(500):
b_pred = model(a)
loss = loss_fn(b_pred, b)
print(te, loss.data[0])
model.zero_grad()
loss.backward()
for param in model.parameters():
param.data -= learning_rate * param.grad.dataAdvanced
We can create several types of graphs without having to change our Module class specification; as a result, we may pass the number of levels as an input. We can make a module list and afterward wrap it along with the torch. We can use nn.ModuleList or write a list of arguments and wrap it in the torch. nn. Parameter list.
The below code gives two different optimizers using a parameter list.
opt1 = torch.optim.SGD([param for param in model.parameters() if param.requires_grad], lr=0.01, momentum=0.9)
optim2 = torch.optim.SGD([
{'params': model.col2.parameters(), 'lr': 0.0001, 'momentum': 0},
{'params': model.lin1.parameters()},
{'params': model.lin2.parameters()}
], lr=0.01, momentum=0.9)Conclusion
Therefore this concludes with the PyTorch Parameters concept. While the majority of users will use Pytorch to develop neural networks, the framework’s flexibility makes it incredibly adaptable.
Recommended Articles
We hope that this EDUCBA information on “PyTorch Parameter” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
