Updated April 12, 2023

Introduction to PySpark parallelize
PYSPARK parallelize is a spark function in the spark Context that is a method of creation of an RDD in a Spark ecosystem. In the Spark ecosystem, RDD is the basic data structure that is used in PySpark, it is an immutable collection of objects that is the basic point for a Spark Application. The Data is computed on different nodes of a Spark cluster which makes the parallel processing happen.
Parallelizing is a function in the Spark context of PySpark that is used to create an RDD from a list of collections. Parallelizing the spark application distributes the data across the multiple nodes and is used to process the data in the Spark ecosystem.
Parallelizing a task means running concurrent tasks on the driver node or worker node. Parallelize is a method in Spark used to parallelize the data by making it in RDD.
The syntax for PySpark parallelize
The syntax for the PYSPARK PARALLELIZE function is:-
sc.parallelize()ScreenShot:-
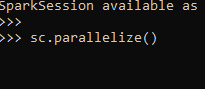
explanation
Sc:- SparkContext for a Spark application
Parallelize method to be used for parallelizing the Data.
Working of PySpark parallelize
Let us see somehow the PARALLELIZE function works in PySpark:-
Parallelize method is the spark context method used to create an RDD in a PySpark application. It is used to create the basic data structure of the spark framework after which the spark processing model comes into the picture. Once parallelizing the data is distributed to all the nodes of the cluster that helps in parallel processing of the data.
This is the working model of a Spark Application that makes spark low cost and a fast processing engine. For this to achieve spark comes up with the basic data structure RDD that is achieved by parallelizing with the spark context. The spark context is generally the entry point for any Spark application and the Parallelize method is used to achieve this model with the given data.
The parallelize method is used to create a parallelized collection that helps spark to distribute the jobs in the cluster and perform parallel processing over the data model.
When we are parallelizing a method we are trying to do the concurrent task together with the help of worker nodes that are needed for running a spark application. The distribution of data across the cluster depends on the various mechanism that is handled by the spark internal architecture.
The is how the use of Parallelize in PySpark.
Example
Let Us See Some Example of How the Pyspark Parallelize Function Works:-
Create a spark context by launching the PySpark in the terminal/ console.
Create the RDD using the sc.parallelize method from the PySpark Context.
sc.parallelize([1,2,3,4,5,6,7])ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:195
The output can be checked by
a=sc.parallelize([1,2,3,4,5,6,7,8,9])
a.collect()Screenshot:-
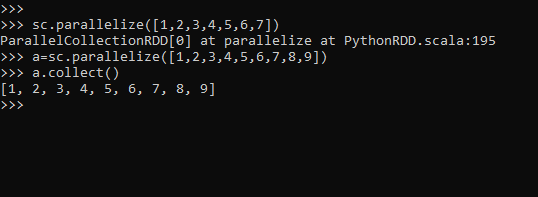
This will create an RDD of type integer post that we can do our Spark Operation over the data.
We can call an action or transformation operation post making the RDD. This RDD can also be changed to Data Frame which can be used in optimizing the Query in a PySpark.
We can do a certain operation like checking the num partitions that can be also used as a parameter while using the parallelize method.
a.getNumPartitions()This will give us the default partitions used while creating the RDD the same can be changed while passing the partition while making partition.
a=sc.parallelize([1,2,3,4,5,6,7,8,9],4)
a.getNumPartitions()This will define the partition as 4.
Screenshot:-

These partitions are basically the unit of parallelism in Spark.
We can also create an Empty RDD in a PySpark application. An Empty RDD is something that doesn’t have any data with it.
This can be achieved by using the method in spark context.
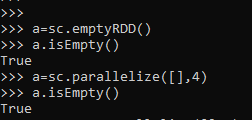
a=sc.emptyRDD()
a.isEmpty()The same can be achieved by parallelizing the PySpark method.
a=sc.parallelize([],4)
a.isEmpty()The same empty RDD is created.
Screenshot:-
Post creation of an RDD we can perform certain action operations over the data and work with the data in parallel.
Let make an RDD with the parallelize method and apply some spark action over the same.
ab = sc.parallelize( [('Monkey', 12), ('Aug', 13), ('Rafif',45), ('Bob', 10), ('Scott', 47)])
ab.first()This will check for the first element of an RDD.
ab.collect()This will collect all the elements of an RDD.
ab.count()This will count the number of elements in PySpark.
These are some of the Spark Action that can be applied post creation of RDD using the Parallelize method in PySpark.
Screenshot:-

From the above example, we saw the use of Parallelize function with PySpark
Conclusion
From the above article, we saw the use of PARALLELIZE in PySpark. From various examples and classification, we tried to understand how the PARALLELIZE method works in PySpark and what are is used at the programming level. The working model made us understood properly the insights of the function and helped us gain more knowledge about the same. The syntax helped out to check the exact parameters used and the functional knowledge of the function.
We also saw the internal working and the advantages of having PARALLELIZE in PySpark in Spark Data Frame and its usage for various programming purpose. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
We hope that this EDUCBA information on “PySpark parallelize” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

