Introduction to PySpark Join
PySpark, the Python interface for Apache Spark, equips users with potent utilities to handle vast datasets efficiently. Within its array of features, PySpark boasts robust functionalities for merging datasets, a pivotal task in data analysis and integration.
Table of Contents:
What is a Join?
In PySpark, a join refers to merging data from two or more DataFrames based on a shared key or condition. This operation closely resembles the JOIN operation in SQL and is essential in data processing tasks that involve integrating data from various sources for analysis.
Why Use Joins in PySpark?
Reasons for the use of joins in PySpark are:
- Joins facilitate the integration of data from different sources, allowing for comprehensive analysis.
- By merging datasets, joins aid in identifying connections between distinct entities within the data, thereby facilitating relational analysis.
- Joins enable the enrichment of datasets with supplementary attributes or information, thereby increasing their value for analysis.
PySpark Syntax
The PySpark syntax entails utilizing the PySpark API to execute various operations on distributed datasets (RDDs or DataFrames) within Spark’s distributed computing framework.
Some of the vital syntax used in PySpark are:
1. Importing PySpark
from pyspark.sql import SparkSession2. Creating a Spark Session
spark = SparkSession.builder \
.appName("AppName") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()3. Loading Data
# Load data from a CSV file into a DataFrame
df = spark.read.csv("path/to/file.csv", header=True, inferSchema=True)4. Writing Data
# Write DataFrame to a CSV file
df.write.csv("path/to/output.csv", mode="overwrite", header=True)5. Stopping the Spark Session
spark.stop()Types of Joins in PySpark
In PySpark, you can conduct different types of joins, enabling combining data from multiple DataFrames based on a shared key or condition.
Basic Example:
Code:
from pyspark.sql import SparkSession
# Create SparkSession
spark = SparkSession.builder \
.appName("SimpleJoinExample") \
.getOrCreate()
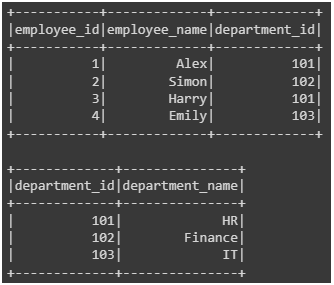
# Sample data
employee_data = [(1, "Alex", 101), (2, "Simon", 102), (3, "Harry", 101), (4, "Emily", 103)]
department_data = [(101, "HR"), (102, "Finance"), (103, "IT")]
# Create RDDs
employee_rdd = spark.sparkContext.parallelize(employee_data)
department_rdd = spark.sparkContext.parallelize(department_data)
# Convert RDDs to DataFrames directly
employee_df = employee_rdd.toDF(["employee_id", "employee_name", "department_id"])
department_df = department_rdd.toDF(["department_id", "department_name"])
# Show the DataFrames
employee_df.show()
department_df.show()
# Stop SparkSession
spark.stop()Output:
Let’s see the join operation and its usage:
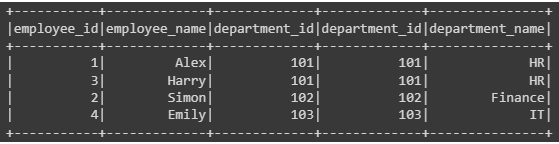
1. Inner Join
In PySpark, an inner join merges rows from two DataFrames based on a common key, including only those rows where the specified keys match in both DataFrames.
Code:
# Perform inner join
joined_df = employee_df.join(department_df, employee_df["department_id"] == department_df["department_id"], "inner")
# Show the joined DataFrame
joined_df.show()Output:
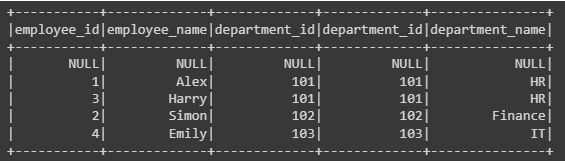
2. Outer Join
An outer or full join merges rows from two tables in a relational database or PySpark DataFrame. Unlike inner joins, it incorporates all rows from both tables in the resulting set, filling in null values for unmatched entries in the specified columns.
Code:
# Add a null row to department_data to demonstrate outer join
department_data.append((None, None))
# Perform outer join
outer_joined_df = employee_df.join(department_df, employee_df["department_id"] == department_df["department_id"], "outer")
outer_joined_df.show()Output:
3. Left Join
The result set of a left join, also known as a left outer join, includes all rows from the left table (or DataFrame), along with matching rows from the right table. If a row in the left table has no corresponding row in the right table, null values fill the missing columns from the right table.
Code:
# Perform left join
left_joined_df = employee_df.join(department_df, employee_df["department_id"] == department_df["department_id"], "left")
# Show the joined DataFrame
left_joined_df.show()Output:
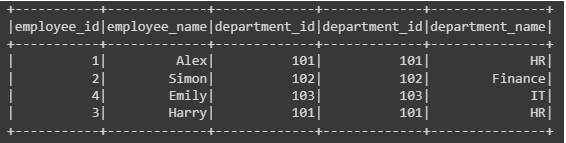
4. Right Join
In a right join, also called a right outer join, all rows from the right table (or DataFrame) are incorporated in the result set, accompanied by matching rows from the left table. When a row in the right table lacks a corresponding row in the left table, null values are employed to complete the missing columns from the left table.
Code:
# Perform right join
right_joined_df = employee_df.join(department_df, employee_df["department_id"] == department_df["department_id"], "right")
# Show the joined DataFrame
right_joined_df.show()Output:
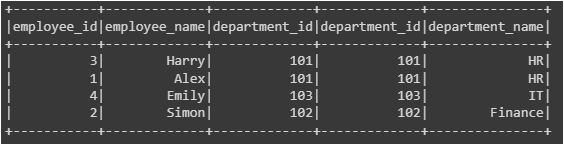
5. Left Semi Join
The result set of a left semi join consists solely of the rows from the left table (or DataFrame) with corresponding rows in the right table. This operation excludes any columns from the right table in the output.
Code:
# Perform left semi join
left_semi_joined_df = employee_df.join(department_df, employee_df["department_id"] == department_df["department_id"], "left_semi")
# Show the joined DataFrame
left_semi_joined_df.show()Output:
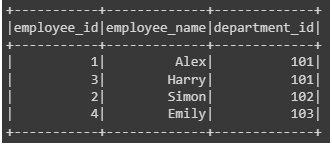
6. Left Anti Join
In a left anti join, only the rows from the left table (or DataFrame) that do not have matching rows in the right table are included in the result set, while it excludes rows where there is a match in the right table.
Code:
# Perform left anti join
left_anti_joined_df = employee_df.join(department_df, employee_df["department_id"] == department_df["department_id"], "left_anti")
# Show the joined DataFrame
left_anti_joined_df.show()Output:
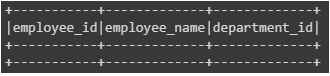
(Since there are no unmatched rows, Hence we got empty values in Dataframe)
7. PySpark Self Join
In PySpark, a self-join is when a DataFrame merges with itself. This join often compares or merges rows within the same DataFrame based on specific conditions.
Code:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# Create SparkSession
spark = SparkSession.builder \
.appName("SelfJoinExample") \
.getOrCreate()
# Sample data
data = [("Alex", "Bruno", 5000),
("Bruno", "Charlie", 6000),
("Charlie", "Diana", 7000),
("David", "Alex", 5000),
("Eva", "Alex", 5000)]
columns = ["employee", "manager", "salary"]
# Create DataFrame
df = spark.createDataFrame(data, columns)
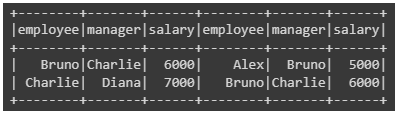
# Perform self join
self_joined_df = df.alias("e1").join(df.alias("e2"), col("e1.employee") == col("e2.manager"), "inner") \
.where(col("e1.salary") != col("e2.salary"))
# Show the self joined DataFrame
self_joined_df.show()
# Stop SparkSession
spark.stop()Output:
8. Cross Join
A cross join, also known as a Cartesian join, is a join operation that produces the Cartesian product of two DataFrames in PySpark. It pairs each row from the first DataFrame with every row from the second DataFrame, generating a DataFrame with a total number of rows equal to the product of the row counts of both DataFrames.
Code:
from pyspark.sql import SparkSession
# Create SparkSession
spark = SparkSession.builder \
.appName("CrossJoinExample") \
.getOrCreate()
# Sample data
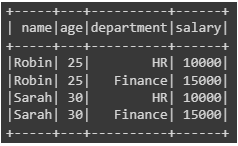
data1 = [("Robin", 25), ("Sarah", 30)]
data2 = [("HR", 10000), ("Finance", 15000)]
# Create DataFrames
df1 = spark.createDataFrame(data1, ["name", "age"])
df2 = spark.createDataFrame(data2, ["department", "salary"])
# Perform cross join
cross_joined_df = df1.crossJoin(df2)
# Show the cross joined DataFrame
cross_joined_df.show()
# Stop SparkSession
spark.stop()Output:
Best Practices for PySpark Joins
- Data Understanding: Before executing joins, it’s crucial to thoroughly grasp the data’s structure and contents. Identify the columns for joining and their corresponding data types. This insight will assist in selecting the appropriate join type and optimizing performance.
- Choosing the Right join type: Choose the suitable join type (inner, outer, etc.) according to your specific use case and data needs. Opt for inner joins when you require matching records from both DataFrames and employ outer joins when you need to include unmatched records.
- Optimize Data Size: Whenever feasible, reduce the size of your DataFrames before executing joins. Reduce data volume by removing unnecessary columns/rows and applying relevant aggregations/transformations.
- Monitor and Tune Performance: Monitor the performance of your join operations using Spark UI or other monitoring tools. Adjust configurations such as executor memory, cores, and parallelism based on your cluster resources and workload to optimize performance.
- Test and Validate Results: Always test the join operations with sample data and verify the results to guarantee accuracy. Compare the output of joins with expected results, mainly when dealing with intricate join conditions or sizable datasets.
Conclusion
PySpark, the Python interface for Apache Spark, offers powerful tools for merging datasets, which is vital for integrating and analyzing various data sources. Join operations in PySpark combine DataFrames using shared keys or conditions, similar to SQL JOIN. Join types include inner, outer, left, right, semi, anti, self, and cross joins, each catering to specific data integration requirements. Best practices entail comprehending data structures, selecting suitable join types, optimizing data size, monitoring performance, and validating results for precise analysis. These practices ensure the effective management of large datasets within Spark’s distributed computing framework.
FAQs
1. What is the difference between inner and outer join in PySpark?
Answer: In PySpark, an inner join incorporates only the rows where the specified keys match in both DataFrames, whereas an outer (full) join includes all rows from both DataFrames, utilizing null values for unmatched entries.
2. Are there any limitations or considerations when performing joins in PySpark?
Answer: Considerations involve comprehending memory and computational resources, selecting suitable join types based on data requirements, and validating join results to ensure data integrity and accuracy. Additionally, complex join conditions or the merging of large datasets may impact performance and necessitate optimization strategies.
3. Is it possible to perform complex join operations like multi-key or non-equi in PySpark?
Answer: Indeed, PySpark facilitates complex join operations such as multi-key joins (joining on multiple columns), and non-equi joins (utilizing non-equality conditions like <, >, <=, >=, !=) by specifying the relevant join conditions within the join() function.
4. How do we handle duplicate keys during PySpark joins?
Answer: PySpark addresses duplicate keys during joins by generating a Cartesian product of matching keys, which can lead to multiple rows in the output DataFrame. To manage duplicates, you can conduct additional aggregation or filtering operations following the join to maintain data consistency.
Recommended Articles
We hope that this EDUCBA information on “PySpark Join” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

