Updated April 12, 2023

Introduction to PySpark Histogram
PySpark Histogram is a way in PySpark to represent the data frames into numerical data by binding the data with possible aggregation functions. It is a visualization technique that is used to visualize the distribution of variable . PySpark histogram are easy to use and the visualization is quite clear with data points over needed one.
This visualization of data with histogram helps to compare data with data frames and analyze the report at once based on that data. Bar charting can be used to create the visualization pattern with the spark data frame and by plotting them gives us clear picture about the data and its information about the data. So by having PySpark histogram we can find out a way to work and analyze the data frames, RDD in PySpark.
Syntax of PySpark Histogram
The syntax for PySpark Histogram function is:
rdd.histogram(("a", "b", "c"))Output:
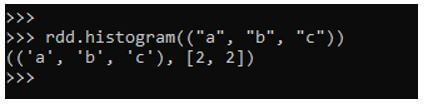
Explanation:
- rdd: The PySpark RDD.
- histogram: The visualization function.
Working of Histogram in PySpark
Let us see how the Histogram works in PySpark:
1. Histogram is a computation of an RDD in PySpark using the buckets provided. The buckets here refers to the range to which we need to compute the histogram value.
2. The buckets are generally all open to the right except the last one which is closed.
3. For Example any RDD for which we need to compute RDD will create bucket for which the right opens are opened except the last one.
4. [11,20,34,67] will represent the bucket as [11,20) opened , [20,34) opened ,[34,67] as closed.
5. The open bucket means the data cannot be equal to that, it will be always less than the open value.
That means that the value for the above bucket will lie somewhere like:
- 11 <=y<20 ;
- 20<=y<34;
- 34<=y<=67
6. There should be sorted buckets and doesn’t contain any duplicate values.
7. The bucket must be at least 1. If the buckets are number that is evenly spaced then the resulting value will also be spread evenly in a histogram.
8. If an RDD range is infinity then NAN is returned as the result.
9. If we will try to see the definition of histogram it is some what stated in documentation as:
Method Definition:
def histogram(bucketount: Int): (Array[Double], Array[Long])
10. It is used to compute the histogram of the data using the bucketcount of the buckets that are between the maximum and minimum of the RDD in a PySpark.
11. We can also define the buckets of our own.
Examples of PySpark Histogram
Let us see some examples how to compute Histogram.
Example #1
Lets create an PySpark RDD.
Code:
rdd = sc.parallelize(["ab", "ac", "b", "bd", "ef"])
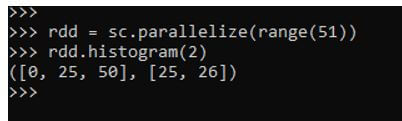
rdd = sc.parallelize(range(51))Lets plot the histogram for the made RDD.
rdd.histogram(2)This will create an histogram with bucket 2. The result will create the histogram.
Output:
Example #2
Lets try to create an PySpark RDD and try to compute Histogram with evenly space buckets .
Code:
rdd.histogram([0, 15, 30, 45, 60])This will create an RDD with evenly spaced buckets.
Output:

Example #3
Lets try to plot histogram with an RDD as an String Data Type.
Code:
rdd = sc.parallelize(["acb", "afc", "ab", "bdd", "efd"])This will create an RDD with type as String.
rdd.histogram(("a", "b", "c"))Create an Histogram with the RDD. This will compute histogram for the given RDD.
(('a', 'b', 'c'), [3, 1])Its necessary to be the bucket as the sorted on. An unsorted bucket will give an Error while Plotting an Histogram.
Example #4
Lets try to pass an unsorted bucket and plot the histogram.
While creating a Histogram with unsorted bucket we get the following error:
ValueError: buckets should be sortedue communicating with driver in heartbeater
rdd.histogram((“da”,”df”,”sd”,”dd”))
Here we are trying to create an bucket that is an unsorted one. While plotting the histogram we get the error to sort the buckets while communicating with driver.
Output:

The same can be created successfully if we just pass an sorted bucket over the RDD.
Code:
rdd.histogram(("da","df","dy","dz"))The same will plot the histogram for given RDD.
Output:

We can also plot the data from histogram using the Python library which can imported and is used to compute and visualize the Data needed.
Statistical charts for analytics and data visualization can be plotted with the Data Frames in PySpark.
Conclusion
From the above article we saw the use of Histogram Operation in PySpark. From various example and classification we tried to know how the Histogram method works in PySpark and what are is use in the programming level. We also saw the internal working and the advantages of having Histogram in Spark Data Frame and its usage in various programming purpose. Also the syntax and examples helped us to understand much precisely over the function.
Recommended Articles
We hope that this EDUCBA information on “PySpark Histogram” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

