Updated March 4, 2023

Introduction to Primary Index in Teradata
The primary index or PI is the most powerful feature available in Teradata. Having the primary key in a table means that we must have at least one column in the Teradata table as the primary index, which uniquely identifies a row. It is usually defined at the time of creating the tables. If in case you want to make any modifications to the primary index of the table, then all you need to do is drop that table and recreate it with the updated primary index. In a nutshell, we cannot apply alter statements to modify a primary index in Teradata.
What is the Primary Index in Teradata?
The primary index is the most preferred index in Teradata due to many reasons, and some of them are:
- It improves the performance of joins.
- It serves as the index for even data distribution over multiple AMP’s.
- Known access path.
There are generally two types of primary indexes:
- Unique Primary Index
- Non-Unique Primary Index
Given below are the two types of primary indexes:
1. Unique Primary Index
It allows only the unique values in the column that is set to a Unique primary index. That is, duplicates aren’t allowed in that column at all; that’s why it’s called a Unique Primary Index. Data distribution is even in the case of a unique primary index, and it is a one AMP specific operation.
Syntax:
The syntax of defining the unique primary index during the creation of the table is given below:
CREATE TABLE Tab_name
(col_1 INT,
col_2 VARCHAR(20),
col_3 CHAR(4)
col_4 CHAR(4)
)
UNIQUE PRIMARY INDEX (col_1);- At the end of the create SQL, we define the Unique Primary Index with column name to be set as UPI in the parenthesis.
- Here col_1 will serve as the Unique Primary Index for the table – Tab_name.
- In the table Tab_name, this column will not allow any duplicate entries, ensuring all values entered in this table via an insert statement is unique regarding the column – col_1.
How is data distributed using Unique Primary Index?
Let’s consider a table in which EMP_NO is the unique primary index. How to insert a statement by entering values with respect to this case scenario?
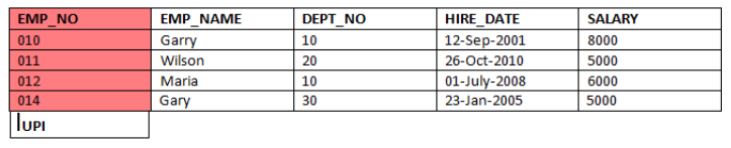
How does this work?
Suppose the user runs the below insert query:
INSERT INTO DBNAME.EMPLOYEE VALUES (011,'Wilson',20,'2010-10-26',5000);- A 32-bit row hash value is created for the primary index using the row-hashing algo.
- Out of these 32 bits, the first 20 bits defines the AMP at which the row having this index will reside. Hash map decides this, which contains one million hash buckets.
- This is how a hash map looks like :

- A unique value is configured for each row. As EMP_NO in this table is unique, then it can serve as the unique index.
- This is how the row is distributed to the AMP, and the same is the process for the retrieval.
2. Non-Unique Primary Index
A non-unique primary index, as the name suggests, allows duplicate values; that is, it can have a ‘n’ number of null values in the column defined as a non-unique primary index.
Syntax:
The syntax for the Non-Unique Primary Index is given below:
CREATE TABLE Tab_name
(col_1 INT,
col_2 VARCHAR(20),
col_3 CHAR(4)
col_4 CHAR(4)
)
PRIMARY INDEX (col_1);- If we compare it with the Unique primary index, then the change over here is the absence of the “Unique” keyword.
- Due to this, now col_1 can have multiple non-unique or duplicate values as well.
How does this work?
Let’s take an example for understanding the concept of Non- Unique primary index as well:

- Here EMP_NAME is the non-unique primary index; therefore, it can contain duplicate records as well.
- Now let’s see what happens if we have duplicate values in our table.
- Let’s say if Garry appeared twice in the EMP_NAME column.
- What will happen at the parsing engine (PE) in this case when it receives the duplicate values?
- Here as well, Similar to the same of Unique primary index, a hash value will be generated.
- A unique value will be added to the generated hash value to mark a difference between the duplicate values.
- This can be something like below:

- This is how the uniqueness value marks the duplicate row as a unique one and differentiates it from the duplicates.
- If in case, say we have had one more record with EMP_NAME as Gary, then the uniqueness value for it would have been 3.
- Now, coming to the AMP in which these values will be stored.
What do you think?
- Yes, as the AMP is selected based on the hash value, all of the duplicates will go to the same AMP.
- That is, All the records having the same value under EMP_NAME will have a similar hash code and will eventually fall under the same AMP.
What happens due to this?
- Due to the presence of Non- Unique Primary Index, duplicates will be allowed within that field.
- Due to this, we will have more records under some AMP compared to the others for the same table. The reason being the same hash value for the duplicates.
- Thus, all this results in uneven data distribution throughout the AMP’s and, thus, downgraded performance for that table.

Example of Primary Index
Given below is the example:
Code:
CREATE TABLE employee (
emp_no SMALLINT FORMAT '9(5)'
CHECK (emp_no>= 10001 AND emp_no<= 32001) NOT NULL,
name VARCHAR(12) NOT NULL,
dept_no SMALLINT FORMAT '999'
CHECK (deptno>= 100 AND dept_no<= 900),
job_title VARCHAR(12),
salary DECIMAL(8,2) FORMAT 'ZZZ,ZZ9.99'
CHECK (salary >= 1.00 AND salary <= 999000.00),
yrs_exp BYTEINT FORMAT 'Z9'
CHECK(yrs_exp>= -99 AND yrs_exp<=99),
dob DATE FORMAT 'MMMbDDbYYYY' NOT NULL,
sex CHARACTER UPPERCASE NOT NULL
CHECK (sex IN ('M','F')),
race CHARACTER UPPERCASE,
m_stat CHARACTER UPPERCASE
CHECK (m_stat IN ('S','M','D','U')),
edlev BYTEINT FORMAT 'Z9'
CHECK (ed_lev>=0 AND ed_lev<=22) NOT NULL,
h_cap BYTEINT FORMAT 'Z9'
CHECK (h_cap>= -99 AND h_cap<= 99)
UNIQUE PRIMARY INDEX (emp_no),
UNIQUE INDEX (name);- Here at the end, we have created a unique primary Index.
Conclusion
A Primary index serves as a unique key if in case we have defined a unique primary index, else not if it’s a non-unique primary index. A hash value is generated to distribute each row into an AMP. UPI has even distributions. NUPI has uneven distributions sue to the presence of duplicates
Recommended Articles
We hope that this EDUCBA information on “Primary Index in Teradata” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
