Updated May 4, 2023

Difference Between Pig vs Spark
Pig vs Spark is the comparison between the technology frameworks that are used for high-volume data processing for analytics purposes. Pig is an open-source tool that works on the Hadoop framework using pig scripting, which converts to map-reduce jobs implicitly for big data processing. At the same time, Spark is an open-source framework that uses resilient distributed datasets(RDD) and Spark SQL for processing big data. The Spark framework is more efficient and scalable than the Pig framework. Pig Latin scripts can be used as SQL-like functionalities, whereas Spark supports built-in functionalities and APIs such as PySpark for data processing.
Head-to-Head Comparison Between Pig vs Spark (Infographics)
Below are the top 10 comparisons between Pig vs Spark:
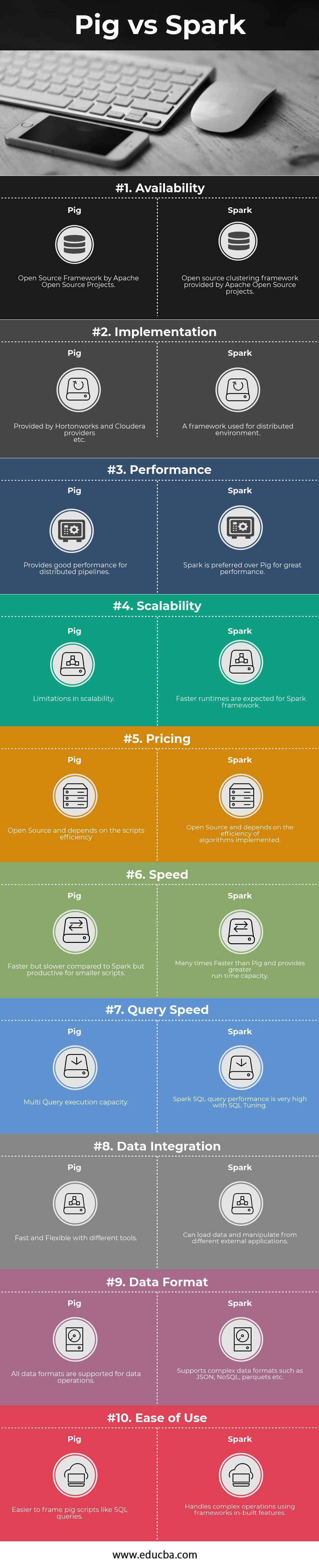
Key Differences Between Pig vs Spark
Below are the lists of points that describe the key Differences Between Pig vs Spark:
- The Apache Pig is a general-purpose programming and clustering framework for large-scale data processing compatible with Hadoop. In contrast, Apache Pig is a scripting environment for running Pig Scripts to manipulate complex and large-scale data sets.
- Apache Pig is a high-level data flow scripting language that supports standalone scripts and provides an interactive shell that executes on Hadoop. In contrast, Spark is a high-level cluster computing framework that can be easily integrated with the Hadoop framework.
- You can run data manipulation operations by executing Pig Scripts. Spark SQL module is used to execute SQL queries in Spark.
- Apache Pig provides extensibility, ease of programming, and optimization features, and Apache Spark offers high performance and runs 100 times faster to run workloads.
- Regarding Pig architecture, the scripting can be parallelized and enables handling large datasets, whereas Spark provides batch and streaming data operations.
- In Pig, there will be built-in functions to carry out some default operations and functionalities. In Spark, SQL, streaming, and complex analytics can be combined, which powers a stack of libraries for SQL, core, MLib, and Streaming modules available for different complex applications.
- Apache Pig provides Tez mode to focus more on performance and optimization flow, whereas Apache Spark delivers high performance in streaming and batch data processing jobs.
- Apache Pig provides Tez mode to focus more on performance and optimization flow, whereas Apache Spark delivers high performance in streaming and batch data processing jobs. The Tez mode can be enabled explicitly using configuration.
- Apache Pig is being used by most of the existing tech organizations to perform data manipulations, whereas Spark is recently evolving, which is an analytics engine for large scale.
- Apache Pig uses a lazy execution technique, and the Pig Latin commands can be easily transformed or converted into Spark actions. In contrast, Apache Spark has an in-built DAG scheduler, a query optimizer, and a physical execution engine for the fast processing large datasets.
- Apache Pig is similar to the Data Flow execution model in Data Stage job tools like ETL (Extract, Transform, and Load). In contrast, Apache Spark runs everywhere, works with Hadoop, and can access multiple diverse data sources.
Pig vs Spark Comparison Table
Below are the lists of points that describe the comparisons Between Pig vs Spark:
|
Basis of Comparison |
Pig | Spark |
| Availability | Open Source Framework by Apache Open Source Projects. | Open source clustering framework provided by Apache Open Source projects. |
| Implementation | Provided by Hortonworks and Cloudera providers etc. | A framework used for a distributed environment. |
| Performance | Provides good performance for distributed pipelines. | People prefer Spark over Pig for its excellent performance. |
| Scalability | Limitations in scalability. | We expect faster runtimes for the Spark framework. |
| Pricing | Open source and depends on the script’s efficiency. | Open source and depends on the efficiency of algorithms implemented. |
| Speed | Faster but slower compared to Spark but productive for smaller scripts. | Many times Faster than Pig and provides greater runtime capacity. |
| Query Speed | Multi Query execution capacity. | Spark SQL query performance is very high with SQL Tuning. |
| Data Integration | Fast and Flexible with different tools. | Can load data and manipulate it from different external applications. |
| Data Format | All data formats are supported for data operations. | Supports complex data formats such as JSON, NoSQL, parquets, etc. |
| Ease of Use | Easier to frame pig scripts like SQL queries. | Handles complex operations using frameworks’ in-built features. |
Conclusion
The final statement to conclude the comparison between Pig and Spark is that Spark wins regarding ease of operations, maintenance, and productivity. In contrast, Pig lacks, in terms of performance scalability and features, integration with third-party tools and products in the case of a large volume of data sets. As both Pig and Spark projects belong to Apache Software Foundation, both Pig and Spark are open source and can be used and integrated with a Hadoop environment and deployed for data applications based on the amount and volumes of data to be operated upon.
In most cases, Spark has been the best choice to consider for large-scale business requirements by most clients or customers to handle the large-scale and sensitive data of any financial institution or public information with more data integrity and security. Besides the existing benefits, Spark has its advantages as an open-source project. It has been evolving more sophistically with significant clustering operational features that replace existing systems to reduce cost-incurring processes and the complexities and run time.
Recommended Articles
This has been a guide to Pig vs Spark. Here we have discussed Pig vs Spark head-to-head comparison, key differences, infographics, and comparison table. You may also look at the following articles to learn more –
