Updated June 9, 2023

Introduction to Pig Commands
Apache Pig is a tool/platform for analyzing large datasets and performing extended data operations. Pig is used with Hadoop. All pig scripts internally get converted into map-reduce tasks and then get executed. It can handle structured, semi-structured, and unstructured data. Pig stores its result in HDFS. In this article, we learn more types of Pig Commands.
Here are some characteristics :
- Self-Optimizing: Pig can optimize the execution jobs; the user has the freedom to focus on semantics.
- Easy to Program: Pig provides a high-level language/dialect known as Pig Latin, which is easy to write. Pig Latin provides many operators that programmers can use to process the data. The programmer has the flexibility to write their functions as well.
- Extensible: Pig facilitates the creation of custom functions called UDFs (User-defined functions), which make programmers capable of achieving any processing requirement fast & efficiently. The pig script runs on a shell known as the grunt.
Why Pig Commands?
Programmers not good with Java usually struggle to write programs in Hadoop, i.e., writing map-reduce tasks. Pig Latin, which is quite alike SQL language, is a boon for them. Its multi-query approach reduces the length of the code.
So overall, it is a concise and effective way of programming. Pig Commands can invoke code in many languages like JRuby, Jython, and Java.
The Architecture of Pig Commands
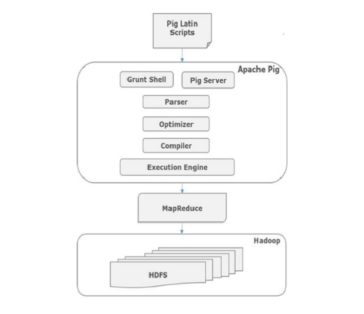
All the scripts written in Pig-Latin over the grunt shell go to the parser to check the syntax, and other miscellaneous checks also happen. The output of the parser is a DAG. The Optimizer receives the DAG and performs logical optimization tasks such as projection and push-down. Then compiler compiles the logical plan to MapReduce jobs. In the end, Hadoop receives these MapReduce jobs in sorted order. These jobs execute and produce the desired results.
The pig-Latin data model is fully nested, allowing complex data types such as maps and tuples.
Any single value of Pig Latin language (irrespective of datatype) is known as Atom.
Basic Pig Commands
Let’s take a look at some of the Basic Pig commands, which are given below:-
1. Fs: This will list all the files in the HDFS
grunt> fs –ls
2. Clear: This will clear the interactive Grunt shell.
grunt> clear
3. History:
This command shows the commands executed so far.
grunt> history
4. Reading Data: Assuming the data resides in HDFS, we need to read data to Pig.
grunt> college_students = LOAD ‘hdfs://localhost:9000/pig_data/college_data.txt’
USING PigStorage(‘,’)
as ( id: int, firstname:chararray, lastname:chararray, phone:chararray,
city:chararray );
PigStorage() is the function that loads and stores data as structured text files.
5. Storing Data: The store operator stores the processed/loaded data.
grunt> STORE college_students INTO ‘ hdfs://localhost:9000/pig_Output/ ‘ USING PigStorage (‘,’);
Here, “/pig_Output/” is the directory where the relation needs to be stored.
6. Dump Operator: This command displays the results on the screen. It usually helps in debugging.
grunt> Dump college_students;
7. Describe Operator: It helps the programmer view the relation’s schema.
grunt> describe college_students;
8. Explain: This command helps to review the logical, physical, and map-reduce execution plans.
grunt> explain college_students;
9. Illustrate operator: This gives step-by-step execution of statements in Pig Commands.
grunt> illustrate college_students;
Intermediate Pig Commands
1. Group: This command works towards grouping data with the same key.
grunt> group_data = GROUP college_students by first name;
2. COGROUP: It works similarly to the group operator. The main difference between Group & Cogroup operators is that the group operator usually uses one relation, while cogroup uses more than one relation.
3. Join: This is used to combine two or more relations.
Example: To perform self-join, the relation “customer” is loaded from HDFS tp pig commands in two relations, customers1 & customers2.
grunt> customers3 = JOIN customers1 BY id, customers2 BY id;
Join could be self-join, Inner-join, or Outer-join.
4. Cross: This pig command calculates the cross product of two or more relations.
grunt> cross_data = CROSS customers, orders;
5. Union: It merges two relations. The condition for merging is that the relation’s columns and domains must be identical.
grunt> student = UNION student1, student2;
Advanced Commands
Let’s take a look at some of the advanced Pig commands, which are given below:
1. Filter: This helps filter out the tuples out of relation based on certain conditions.
filter_data = FILTER college_students BY city == ‘Chennai’;
2. Distinct: This helps in the removal of redundant tuples from the relation.
grunt> distinct_data = DISTINCT college_students;
This filtering will create a new relation name, “distinct_data.”
3. Foreach: This helps generate data transformation based on column data.
grunt> foreach_data = FOREACH student_details GENERATE id,age,city;
This will get each student’s id, age, and city values from the relation student_details and store it in another relation named foreach_data.
4. Order by: This command displays the result in a sorted order based on one or more fields.
grunt> order_by_data = ORDER college_students BY age DESC;
This will sort the relation “college_students” in descending order by age.
5. Limit: This command gets a limited no. of tuples from the relation.
grunt> limit_data = LIMIT student_details 4;
Tips and Tricks
Below are the different tips and tricks:-
1. Enable Compression on your input and output
set input. Compression.enabled true;
set output. Compression.enabled true;
Above mentioned lines of code must be at the beginning of the Script, allowing the Pig Commands to read compressed files or generate compressed files as output.
2. Join multiple relations
For performing the left join on three relations (input1, input2, input3), one needs to opt for SQL. This is because Pig does not support outer joins on more than two tables.
Rather you perform left to join in two steps:
data1 = JOIN input1 BY key LEFT, input2 BY key;
data2 = JOIN data1 BY input1::key LEFT, input3 BY key;
This means two map-reduce jobs.
To perform the above task more effectively, one can opt for “Cogroup.” A cogroup can join multiple relations. Cogroup, by default, does outer join.
Conclusion
Data scientists typically use Pig, a procedural language, to perform ad-hoc processing and quick prototyping. It’s a great ETL and big data processing tool. Other languages can invoke the scripts and vice versa. Therefore, Pig Commands can build more extensive and more complex applications.
Recommended Articles
This has been a guide to Pig commands. Here we have discussed basic and advanced Pig commands and some immediate commands. You may also look at the following article to learn more –

