Updated July 1, 2023
Introduction to Pandas to dict
The Pandas to_dict() technique is used to convert a DataFrame into a dictionary-like data structure, either in the form of a list or a dictionary, depending on the value provided for the orient parameter. Python is an extraordinary language for doing information examinations because of the awesome environment of information-driven Python bundles. Pandas is one of those bundles and makes bringing in and breaking down information a lot simpler.
Syntax and Parameters:
Df.to_dict(orient='dict',into=)Where,
Orient represents a string value that defines which datatype changes over Columns(series into). For instance, ‘list’ would restore a word reference of records with Key=Column name and Value=List (Converted arrangement).
Into represents, the class can get through a real class or example. For instance, if there should arise an occurrence of default dict example of a class can be passed. The default estimation of this boundary is dict.
It returns the changed dictionary dataframe in Pandas.
How Pandas to dict function work?
Now we see various examples of how pandas to dict function work.
Example #1
Using Pandas to dict function by giving value to the index in the Pandas Dataframe
Code:
import pandas as pd
import pprint as pp
info = {
'Brand': ['BMW', 'Apple, Samsung', 'Mercedes, Inc.',\
'Hyundai Inc.', 'Amazon, Inc.'],
'SFM': ['BMW', 'App', 'Merc', 'Hyun', 'Amzn'],
'Prices': [200, 150, 175, 300, 60],
}
df = pd.DataFrame(info, index=['First', 'Second', 'Third', 'Fourth', 'Fifth'])
s = df.to_dict()
pp.pprint(s)Output:
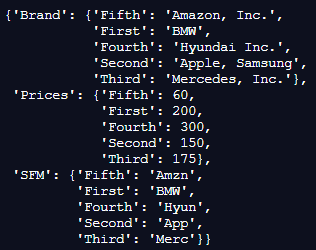
In the above program, we first import the panda’s library and also the pprint libraries, respectively, which helps to run the program. After this, we create a dataframe and add values to the dataframe. Then we use the dict function to add the values into the Python dictionary; hence, the program is executed, and the output is as shown in the above snapshot.
Example #2
Pandas to dict function using orient parameter
Code:
import pandas as pd
import pprint as pp
info = {
'Brand': ['BMW', 'Apple, Samsung', 'Mercedes, Inc.',\
'Hyundai Inc.', 'Amazon, Inc.'],
'SFM': ['BMW', 'App', 'Merc', 'Hyun', 'Amzn'],
'Prices': [200, 150, 175, 300, 60],
}
df = pd.DataFrame(info, index=['First', 'Second', 'Third', 'Fourth', 'Fifth'])
s = df.to_dict(orient='list')
pp.pprint(s)Output:
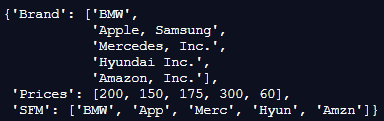
In the above program, we import pandas and pprint libraries, respectively. After importing the libraries, we create a dataframe and add values to this dataframe. After adding values to the dataframe, we use the orient parameter in pandas to dict, which orients the list of values according to the user.
To convert a pandas DataFrame into a Python dictionary, you can use the DataFrame’s example strategy by specifying the orient parameter. This allows you to format the resulting dictionary in different orientations. In the dictionary orientation, the to_dict() method stores the values of each column in the DataFrame as key-value pairs in a dictionary.
The dictionary orientation is specified with the string “dict” for the orient parameter. This is the default orientation for the conversion output. Each column is converted into a list in the list orientation, and the lists are added to a dictionary against the column labels. The list orientation is specified with the string “list” for the orient parameter.
In the series orientation, the to_dict() method converts each column of the DataFrame into a pandas Series. The resulting Series instances are then indexed against the column names in the resulting dictionary object. To indicate the series orientation, you should set the orient parameter to the string “series” when invoking the to_dict() method.
Conclusion
Hence, I conclude by stating that the pandas dataframe to dict capacity can be utilized to change over a pandas data frame to a word reference. It additionally permits a scope of directions for the key-esteem sets in the brought word reference back. In this instructional exercise, we will see how to utilize this capacity with the various directions to get a word reference.
Recommended Articles
We hope that this EDUCBA information on “Pandas to dict” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

