Updated April 11, 2023

Introduction to Pandas resample
Pandas resample work is essentially utilized for time arrangement information. A period arrangement is a progression of information focuses filed (or recorded or diagrammed) in time request. Most generally, a period arrangement is a grouping taken at progressive similarly separated focuses in time and it is a convenient strategy for recurrence transformation and resampling of time arrangement. Article must have a datetime-like record such as DatetimeIndex, PeriodIndex or TimedeltaIndex or spend datetime-like qualities to the on or level catchphrase.
Syntax of Pandas resample
Given below is the syntax :
Pandas. Resample(how=None, rule, fill_method=None, axis=0, label=None, closed=None, kind=None, convention='start', limit=None, loffset=None, on=None, base=0, level=None)Where,
- Rule represents the offset string or object representing target conversion.
- Axis represents the pivot to use for up-or down-inspecting. For Series this will default to 0, for example along the lines. It must be DatetimeIndex, TimedeltaIndex or PeriodIndex.
- Closed means which side of container span is shut. The default is ‘left’ for all recurrence balances with the exception of ‘M’, ‘A’, ‘Q’, ‘BM’, ‘BA’, ‘BQ’, and ‘W’ which all have a default of ‘right’.
- Label represents the canister edge name to name pail with. The default is ‘left’ for all recurrence counterbalances which all have a default of ‘right’.
- Convention represents only for PeriodIndex just, controls whether to utilize the beginning or end of rule.
- Kind represents spending on ‘timestamp’ to change over the subsequent file to a DateTimeIndex or ‘period’ to change over it to a PeriodIndex. As a matter of course the info portrayal is held.
- Loffset represents in reorganizing timestamp labels.
- Base means the frequencies for which equitably partition 1 day, the “birthplace” of the totalled stretches.
- On represents For a DataFrame, segment to use rather than record for resampling. Segment must be datetime-like.
- Level means for a MultiIndex, level (name or number) to use for resampling. Level must be datetime-like.
How does resample() Function works in Pandas?
Given below shows how the resample() function works :
Example #1
Code:
import pandas as pd
import numpy as np
info = pd.date_range('1/1/2013', periods=6, freq='T')
series = pd.Series(range(6), index=info)
series.resample('2T').sum()
print(series.resample('2T').sum())Output:
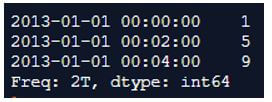
In the above program we see that first we import pandas and NumPy libraries as np and pd, respectively. Then we create a series and this series we add the time frame, frequency and range. Now we use the resample() function to determine the sum of the range in the given time period and the program is executed.
Example #2
Code:
import pandas as pd
import numpy as np
info = pd.date_range('3/2/2013', periods=6, freq='T')
series = pd.Series(range(6), index=info)
series.resample('2T', label='right').sum()
print(series.resample('2T', label='right').sum())Output:
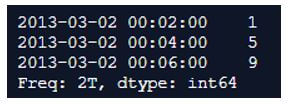
In the above program, we first as usual import pandas and numpy libraries as pd and np respectively. Then we create a series and this series we define the time index, period index and date index and frequency. Finally, we use the resample() function to resample the dataframe and finally produce the output.
Example #3
Code:
import pandas as pd
import numpy as np
info = pd.date_range('3/2/2013', periods=6, freq='T')
series = pd.Series(range(6), index=info)
series.resample('2T', label='right', closed='right').sum()
print(series.resample('2T', label='right', closed='right').sum())Output:
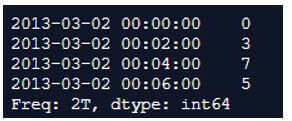
In the above program, we first import the pandas and numpy libraries as before and then create the series. After creating the series, we use the resample() function to down sample all the parameters in the series. Finally, we add label and closed parameters to define and execute and show the frequencies of each timestamp.
The resample technique in pandas is like its groupby strategy as you are basically gathering by a specific time length. You at that point determine a technique for how you might want to resample. df.speed.resample() will be utilized to resample the speed segment of our DataFrame. The ‘W’ demonstrates we need to resample by week. At the base of this post is a rundown of various time periods. The mean() is utilized to show we need the mean speed during this period. With separation, we need the aggregate of the separations throughout the week to perceive how far the vehicle went throughout the week, all things considered we use whole(). With aggregate separation we simply need to accept the last an incentive as it’s a running total aggregate, so all things considered we utilize last().
If there should be an occurrence of upsampling we would need to advance fill our speed information, for this we can utilize ffil() or cushion. Our separation and cumulative_distance section could then be recalculated on these qualities.
Conclusion
As an information researcher or AI engineer, we may experience such sort of datasets where we need to manage dates in our dataset. In this article, we will see pandas works that will help us in the treatment of date and time information. With the correct information on these capacities, we can without much of a stretch oversee datasets that comprise of datetime information and other related undertakings.
Recommended Articles
We hope that this EDUCBA information on “Pandas resample” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

