Updated April 10, 2023
Introduction to NLTK Lemmatizer
NLTK Lemmatizer combines a word’s several inflected forms into a single item for analysis. Similar to stemming, lemmatization adds word context. As a result, it joins together words that have similar meanings. Both stemming and lemmatization are included in text preprocessing. People often misunderstand these two terms. Some people confuse these two. Lemmatization is preferable to stemming since it does a morphological examination of words.
What is NLTK Lemmatizer?
- In NLTK, lemmatization is nothing but the process of algorithmic determining a word’s lemma based on its meaning and context. In most cases, lemmatization refers to the morphological study of words to remove inflectional endings.
- It aids in the retrieval of the lemma, or basic or dictionary form, of a word. The NLTK Lemmatization technique uses the built-in morph function in WorldNet.
- The suffix word is how the steaming method works. In a larger sense, it slashes the word’s beginning or finish.
- On the other hand, lemmatization is a more powerful procedure that considers word morphological analysis. It returns the lemma, which is the inflectional form or basic form.
- We will need a lot of linguistic knowledge to make dictionaries and hunt for the right term form. Stemming is a broad process, but lemmatization is a smart operation that searches the dictionary for the right form. As a result, lemmatization aids in developing more effective machine learning features.
- In linguistics, lemmatization refers to grouping inflected versions of a word such that they can be analyzed as a single word. For various lemma determinations, NLTK includes various lemmatization techniques and functions. When opposed to stemming, lemmatization is better for determining a word’s context within a document.
- Unlike stemming, lemmatization examines the major context of the document using words in the sentence. As a result, NLTK Lemmatization is critical for comprehending a text and applying it to Natural Language Processing and Natural Language Understanding.
- NLTK Dictionary lookup algorithms lemmatize complex terms can benefit lemmatization.
- The main difference is that stemming can often produce words non-existent, whereas words are actual in lemmatizer. So, while we can’t check up on our root stem, we can look up a lemma in a dictionary.
- We may come up with a word that is extremely close to the one we started with, but we may also come up with something altogether different.
How to Use Words NLTK Lemmatizer?
WorldNet is a vast database of lexical items in a verbal language that aims to develop structured semantic associations between words. It’s also a lemmatizer and one of the first and most widely used. It has an interface provided by NLTK, but we must first download it before using it.
To use words nltk lemmatizer, we need to follow the below steps as follows:
1. Install nltk by using the pip command – The first step is to install nltk by using the pip command. Below are examples showing how to install nltk by using the pip command. In the example below, we have already installed nltk, showing satisfied requirements.
Code:
pip install nltkOutput:

2. After installing the pip command, we are login into the python shell by using the python command as follows:
Code:
pythonOutput:

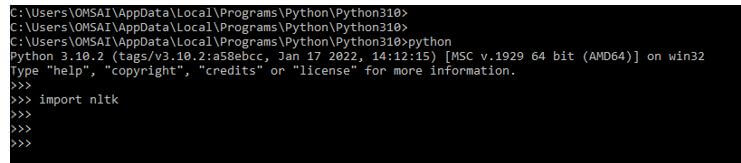
3. After login into the python shell, in this step, we are importing the nltk module in our program by using the import keyword.
Below example shows import the nltk module in our program as follows:
Code:
import nltkOutput:
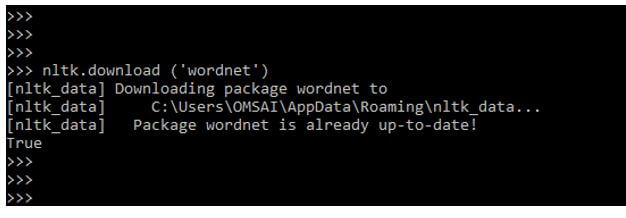
4. After importing the nltk module in this step, we download the WorldNet module in our program. We have already downloaded the wordnet package, so it will show the package is already up to date.
Code:
nltk.download ('wordnet')Output:
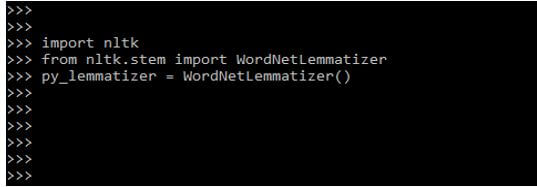
5. After downloading the wordnet package, for the lemmatization in this step, we will create the instance of WordNetLemmatizer and also call the lemmatize function as follows:
Code:
import nltk
from nltk.stem import WordNetLemmatizer
py_lemmatizer = WordNetLemmatizer ()Output:
6. After creating the instance of WordNetLemmatizer, in this step, we are lemmatizing the simple words as follows:
Code:
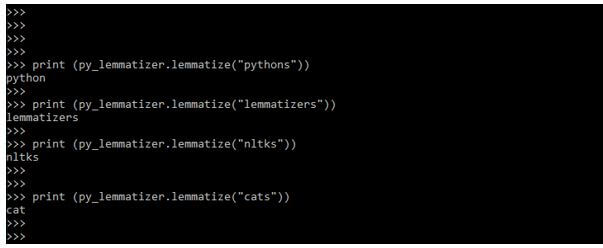
print (py_lemmatizer.lemmatize ("pythons"))
print (py_lemmatizer.lemmatize ("lemmatizers"))
print (py_lemmatizer.lemmatize ("nltks"))
print (py_lemmatizer.lemmatize ("cats"))Output:
Create for Text
- With or without a POS tag, lemmatization can be done. A part-of-speech tag, also known as a POS tag, assigns a tag to each word, increasing the correctness of the dataset.
- Without a POS tag, the word leaves would be lemmatized as a leaf; with a verb, it would be lemmatized as leave.
- Word forms are reduced to linguistically viable lemmas through lemmatization. Lemmatization is typically more complex and necessitates the use of a lexicon. Simple rule-based techniques were used for stemming.
- With lemmatizer, we use the pos tag to generate findings that align with the dataset’s context.
The below example shows create the lemmatized text.
Code:
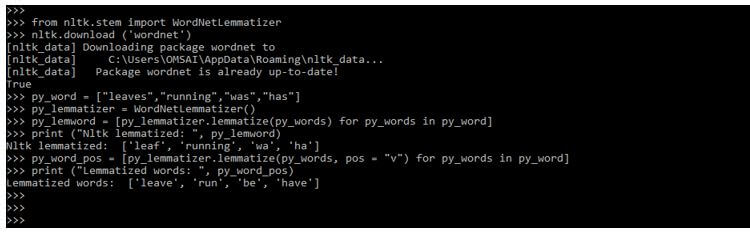
from nltk.stem import WordNetLemmatizer
nltk.download ('wordnet')
py_word = ["leaves", "running", "was", "has"]
py_lemmatizer = WordNetLemmatizer ()
py_lemword = [py_lemmatizer.lemmatize (py_words) for py_words in py_word]
print ("Nltk lemmatized: ", py_lemword)
py_word_pos = [py_lemmatizer.lemmatize (py_words, pos = "v") for py_words in py_word]
print ("Lemmatized words: ", py_word_pos)Output:
Examples of NLTK Lemmatizer
Different examples are mentioned below:
Example #1
Below is an example of an nltk lemmatizer. The below example shows lemmatizing a single word.
Code:
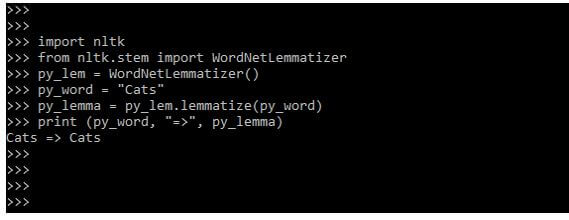
import nltk
from nltk.stem import WordNetLemmatizer
py_lem = WordNetLemmatizer()
py_word = "Cats"
py_lemma = py_lem.lemmatize (py_word)
print (py_word, "=>", py_lemma)Output:
Example #2
The below example shows lemmatizing verbs as follows.
Code:
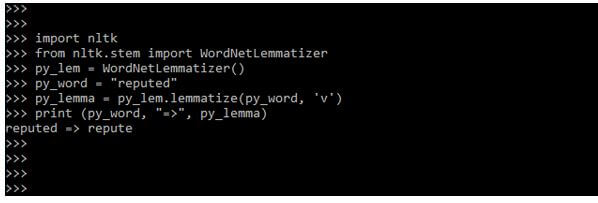
import nltk
from nltk.stem import WordNetLemmatizer
py_lem = WordNetLemmatizer()
py_word = "reputed"
py_lemma = py_lem.lemmatize (py_word, 'v')
print (py_word, "=>", py_lemma)Output:
Example #3
The below example shows lemmatizing adjectives as follows.
Code:
import nltk
from nltk.stem import WordNetLemmatizer
py_lem = WordNetLemmatizer()
py_word = "worst"
py_lemma = py_lem.lemmatize (py_word, 'a')
print (py_word, "=>", py_lemma)Output:

Example #4
The below example shows you lemmatize the adverb as follows.
Code:
import nltk
from nltk.stem import WordNetLemmatizer
py_lem = WordNetLemmatizer()
py_word = "computer"
py_lemma = py_lem.lemmatize (py_word, 'r')
print (py_word, "=>", py_lemma)Output:

Conclusion
NLTK lemmatization refers to grouping inflected versions of a word such that they can be analyzed as a single word. NLTK lemmatizer combines a word’s several inflected forms into a single item for analysis. Similar to stemming, lemmatization adds word context.
Recommended Articles
We hope that this EDUCBA information on “NLTK Lemmatizer” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

