Updated April 14, 2023

Introduction to Tokenization in Python
Tokenization in Python is the most primary step in any natural language processing program. This may find its utility in statistical analysis, parsing, spell-checking, counting and corpus generation etc. The tokenizer is a Python (2 and 3) module.
Why Tokenization in Python?
Natural Language Processing or NLP is a computer science field with learning involved computer linguistic and artificial intelligence and mainly the interaction between human natural languages and computer.By using NLP, computers are programmed to process natural language. Tokenizing data simply means splitting the body of the text. The process involved in this is Python text strings are converted to streams of token objects. It is to be noted that each token is a separate word, number, email, punctuation sign, URL/URI etc. There is also segmentation of tokens into streams of sentences having dates and abbreviation in the middle of the sentences. The tokenizer is licensed under the MIT license.
Object: Token
As discussed above, each token is represented by a <namedtuple>, and it has three fields:(kind, txt,val)
The kind field: It contains one of the following integer constants, which are defined under the TOK class.
The txt field: It contains the original text, and in some cases, it is noticed that the tokenizer auto-corrects the source text. It is seen to convert the single and double quotes to the Icelandic ones.
The val field: This field contains auxiliary information according to the corresponding token.
Installation: You can clone the repository from https://github.com/mideind/Tokenizer
If one wished to run the built-in tests , they can install pytest. Then cd to Tokenizer, and you also need to activate your virtualenv , then run.
Python -m pytest
Methods to Perform Tokenization in Python
Below are listed the number of methods to perform Tokenization:
- Python’s split function
- Using Regular Expressions with NLTK
- spaCy library
- Tokenization using Keras
- Tokenization with Gensim
Example to Implement Tokenization in Python
Here are the example of Tokenization in Python
Example #1
Python’s split function: This is the most basic one, and it returns a list of strings after splitting the string based on a specific separator.The separators can be changed as needed. Sentence Tokenization: Here, the structure of the sentence is analyzed. As we know, a sentence ends with a period(.); therefore, it can be used as a separator.
Code:
text = """ This tool is an a beta stage. Alexa developers can use Get Metrics API to seamlessly analyse metric. It also supports custom skill model, prebuilt Flash Briefing model, and the Smart Home Skill API. You can use this tool for creation of monitors, alarms, and dashboards that spotlight changes. The release of these three tools will enable developers to create visual rich skills for Alexa devices with screens. Amazon describes these tools as the collection of tech and tools for creating visually rich and interactive voice experiences. """
data = text.split('.')
for i in data:
print (i)Output:

- Word Tokenizer: It works similarly to a sentence tokenizer. Here the textis split upinto token based on (‘ ‘) as the separator.We give nothing as the parameter it splits by space by default.
Code:
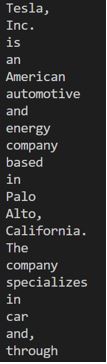
text = """ Tesla, Inc. is an American automotive and energy company based in PAlo Alto, California. The company specializes in electric car manufacturing and, through its SolarCity subsidiary, solar panel manufacturing. """
data = text.split()
for i in data:
print (i)Output:
Example #2
Using Regular Expressions with NLTK: Regular expression is basically a character sequence that helps us search for the matching patterns in thetext we have.The library used in Python for Regular expression is re, and it comes pre-installed with the Python package.Example: We have imported re library use \w+ for picking up specific words from the expression.
Code:
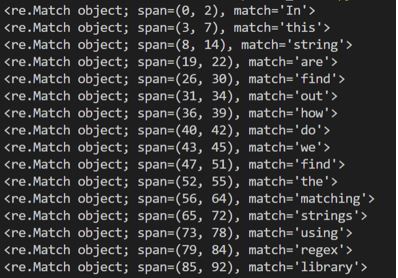
import re
text_to_search = """ In this string you are to find out, how do we find the matching strings using regex library """
pattern = re.compile('\w+')
matches = pattern.finditer(text_to_search)
for match in matches:
print(match)Output:
It is to be noted that nltk needs to be imported before we can use regular expressions.
Tokenization by NLTK: This library is written mainly for statistical Natural Language Processing. We use tokenize () to further split it into two types:
- Word tokenize: word_tokenize() is used to split a sentence into tokens as required.
- Sentence tokenize: sent_tokenize() is used to split a paragraph or a document into sentences.
We see in the terminal below with the output:
from nltk.tokenize import regexp_tokenize
from nltk.tokenize import sent_tokenize
from nltk.tokenize import word_tokenize
s = "I can't do this. I won't do it!"
sent_tokenize(s)
word_tokenize(s)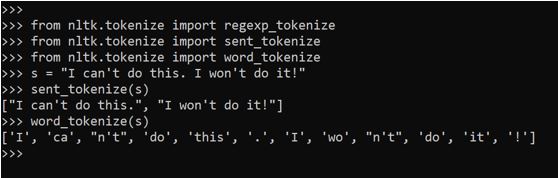
(The very above output was run in cmd as I was having some issue in my Visual Studio Code.)
In the above example we see that the words “can’t” and “won’t” are also separated out. If that has to be considered as a single word then we follow the below approach.
We handle it by adding another line of code . By specifying [\w’]+, we ensure telling python that there is a word after the apostrophe(‘) and that also needs to be handled.
regexp_tokenize(s,"[\w']+")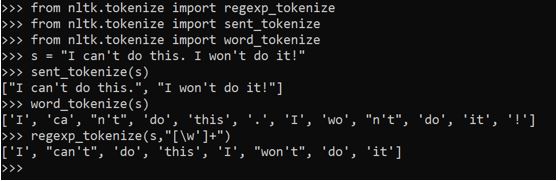
Methods of NLTK
The tokenize() Function: When we need to tokenize a string, we use this function and we get a Python generator of token objects. Each token object is a simple tuple with the fields. In Python 2.7, one can pass either a Unicode string or byte strings to the function tokenizer.tokenize(). And in the later version, it is seen that the byte string is encoded in UTF-8.
Example #3
spaCy library: It is an open-source library for NLP. Here we use spacy.lang.en, which supports the English Language.spaCy is a faster library than nltk.
Before using spaCy, one needs Anaconda installed in their system. Anaconda is a bundle of some popular python packages and a package manager called conda (similar to pip). These packages are very popular in Data Science study. Some popular anaconda packages are numpy, scipy, nltk(the one used above) , jupyter, scikit-learn etc. The reason why conda is used instead of pip is that it helps one to use non-python dependencies as well, whereas pip does not allow that.
The input for the tokenizer is a Unicode text, and the Doc object is the output. Vocab is needed to construct a Doc object.SpaCy’s tokenization can always be reconstructed to the original one and it is to be noted that there is preservation of whitespace information.
Code:
import spacy
from spacy.tokens import Doc
from spacy.lang.en import English
nlp = English()
doc = Doc(nlp.vocab, words = ["Hello", " , ", "World", " ! "], spaces = [False, True, False, False])
print([(t.text, t.text_with_ws, t.whitespace_) for t in doc])Output:

Example #4
Tokenization using Keras: It is one of the most reliable deep learning frameworks. It is an open-source library in python for the neural network. We can install it using: pip install Keras. To perform tokenization we use: text_to_word_sequence method from the Classkeras.preprocessing.text class. One good thing about Keras is it converts the alphabet in the lower case before tokenizing it and thus helpful in time-saving.
Code:
from keras.preprocessing.text import text_to_word_sequence
# define the text
text = 'Text to Word Sequence Function works really well'
# tokenizing the text
tokens = text_to_word_sequence(text)
print(tokens)Output:
![]()
Example #5
Tokenization with Gensim: This open-source library is designed at extracting semantic topics automatically and has found great utility in unsupervised topic modelling and in NLP. It is to be noted that Gensim is quite particular about the punctuations in the string, unlike other libraries.
Code:
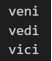
from gensim.summerization.textcleaner import tokenize_by_word
g = tokenize_by_word('Veni. Vedi. Vici. ')
print(next(g))
print(next(g))
print(next(g))Output:
Conclusion
Tokenization is a useful key step in solving an NLP program. As we need to handle the unstructured data first before we start with the modelling process. Tokenization comes handy as the first and the foremost step.
Recommended Articles
We hope that this EDUCBA information on “Tokenization in Python” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

