Updated February 28, 2023

Introduction to Mapreduce Combiner
A Mapreduce Combiner is also called a semi-reducer, which is an optional class operating by taking in the inputs from the Mapper or Map class. And then it passes the key value paired output to the Reducer or Reduce class. The predominant function of a combiner is to sum up the output of map records with similar keys. The key value assembly output of the combiner will be dispatched over the network into the Reducer as an input task. Class of combiner is placed between class of map and class of reduce to decrease the data volume transferred between reduce and map. Usually, the map output task data is large and the transferred data to task for reduction is high.
How does MapReduce Combiner works?
This is a brief summary on the working of MapReduce Combiner:
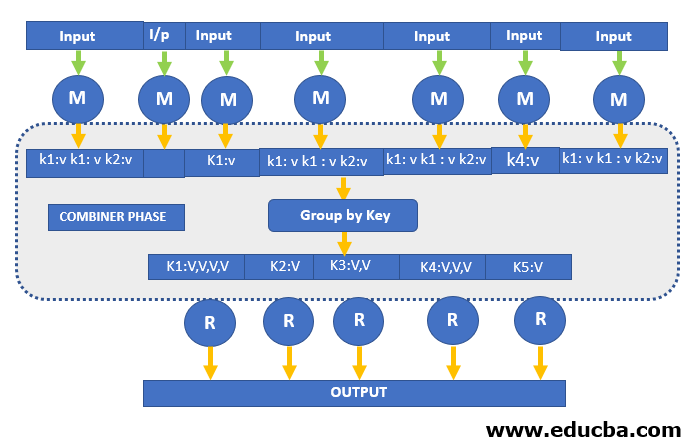
The Mapreduce Combiner must implement a reducer interface method as it does not have a predefined interface. Each of the output of map key is operated by the combiner, Similar key value output should be processed as Reducer class cause the combiner operated on each key map output. The combiner will be able to produce sum up information even with a huge dataset because it takes the place of the original output data of the map. When a MapReduce job is run on a large dataset, a huge chunk of intermediate data is created by map class and the intermediate data is given to the reducer for later processing which will lead to huge network congestion.
MapReduce program outline is somehow like this without the combiner:
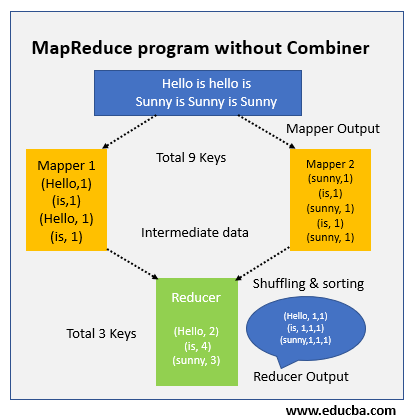
No combiner is used in above diagram. The input is halved into two map classes or mappers and keys are 9 generated in number from mappers. Now we take in the intermediate data to be 9 key value pairs and then the mapper sends directly this data to reduce class or While dispatching the data to the reducer, it takes in time some bandwidth network (bandwidth is the time which is taken to transfer data from one machine to another machine). Time has a significant increase while data transfer if the size of the data is too big.
In between reducer and mapper, we have a combiner hadoop then intermediate data is shuffled prior dispatching it to the reducer and generates the output as 4 key value pairs. With a combiner, it is just two. To know how, look below.
MapReduce program outline is somehow like this with the combiner:
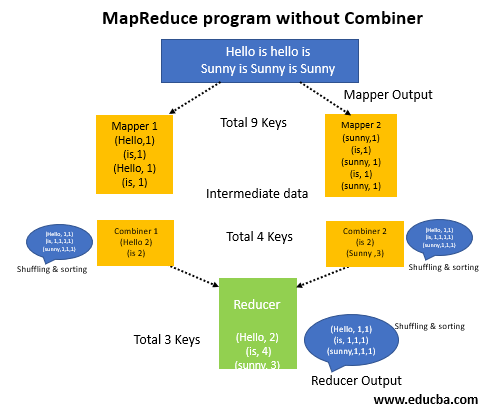
Reducer is now processing only 4 key value pairs which are given as an input from 2 combiners. Reducer is getting executed only 4 ties to give the final result output, which boosts up the overall performance.
Let’s understand more with examples:
A basic code which is used to understand the virtues of MapReduce programming paradigm is through word count. This program has methods of map, combine and reduce which count the number of occurrences of occurrences of each word in a data file.

Setup a new project in Eclipse and add the above Hadoop dependency to pom.xml . This will say if the required access to Hadoop library core is there or not.
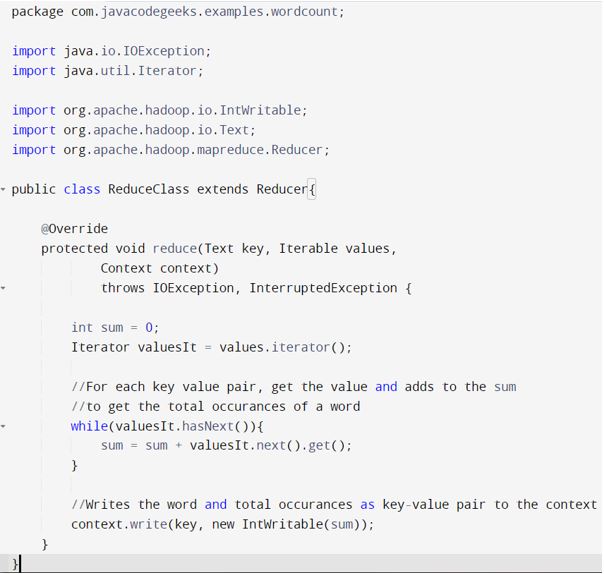
– The block of code first checks if the number of arguments in demand are provided.
– Then it creates new job and set the job name and the class of main
– Input and output pathways are set from the arguments
– Key values type classes are set which precedes the output format class. The classes have to be of the same type which are used in reduce and map for the output.
– The classes of map, combiner, reduce are set in the job.
– Job is executed and waits until its completion.
Implementation of MapReduce Components and MapReduce Combiner
Below are the implementation of Mapreduce componenets
1. Map Phase
Map phase splits the input data into two parts. They are : Keys and Values. Writable and comparable is the key in the processing stage where only in the processing stage, Value is writable. Let’s say a client gives input data to a Hadoop system, task tracker is assigned tasks by job tracker.Mini reducer which is commonly called a combiner, the reducer code places input as the combiner. Network bandwidth is high when a huge amount of data is required. Hash is the default partition used. Partition module plays a key role in Hadoop. More performance is given by reducing the pressure by petitioner on the reducer.
2. Processing in Intermediate
In the intermediate phase, the map input gets into the sort and shuffle phase. Hadoop nodes do not have replications where all the intermediate data is getting stored in a local file system. Round – robin data is used by Hadoop to write to local disk, the intermediate data. There are other shuffle and sort factors to be considered to reach the condition of writing the data to local disks.
3. Reducer Phase
Reducer takes in the data input that is sorted and shuffled. All the input data is going to be combined and similar key value pairs are to be written to the hdfs system. For searching and mapping purposes, a reducer is not always necessary. Setting some properties for enabling to set the number of reducers for each task. During job processing, the speculative execution plays a prominent role.
Conclusion
The above example elaborates the working of Map – Reduce and Mapreduce Combiner paradigm with Hadoop and understanding with the help of word count examples including all the steps in MapReduce. Then we understood the eclipse for purposes in testing and the execution of the Hadoop cluster with the use of HDFS for all the input files.
Recommended Articles
This is a guide to Mapreduce Combiner. Here we discuss the introduction to Mapreduce Combiner, how does it works, implementation of components and combiner. You can also go through our other related articles to learn more –
