Updated February 28, 2023
Introduction to MapReduce Architecture
Hadoop cluster stores a large set of data which is parallelly processed mainly by MapReduce. Firstly, it was just a thesis that Google designed. That provides parallelism, fault-tolerance, and data distribution. For processing huge chunks of data, MapReduce comes into the picture. Map Reduce provides API with features such as parallel processing of huge amounts of data, batch processing, and high availability. Map Reduce programs are written by programmers when there is a need for an application for business scenarios. The development of applications and deployment across Hadoop clusters is done by the programmers when they understand the flow pattern of MapReduce.
Explanation of MapReduce Architecture
Hadoop can be developed in programming languages like Python and C++. MapReduce Hadoop is a software framework for ease in writing applications of software processing huge amounts of data. MapReduce is a framework which splits the chunk of data, sorts the map outputs and input to reduce tasks. A File-system stores the work and input of jobs. Re-execution of failed tasks, scheduling them, and monitoring them is the task of the framework.
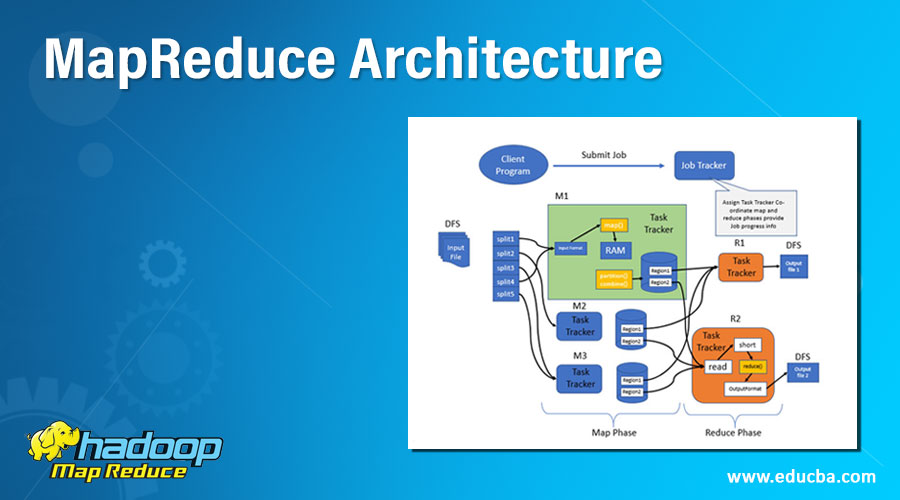
The architecture of MapReduce basically has two main processing stages, and those are Map and Reduce. The MapReduce happens in Job tracker. Intermediate processes will take place in between the Map and Reduce phases. Sort and shuffle are the tasks taken up by Map and Reduce, which are done intermediate. The local file system stores the intermediate data.
- Map() Function: Create and process the import data. Takes in data, converts it into a set of other data where the breakdown of individual elements into tuples is done—no API contract requiring a certain number of outputs.
- Reduce() Function: Mappers output is passed into the reduction. Processes the data into something usable. Every single mapper is passed into the reduced function. The new output values are saved into HDFS.
MapReduce Architecture Components
Below is the explanation of components of MapReduce architecture:
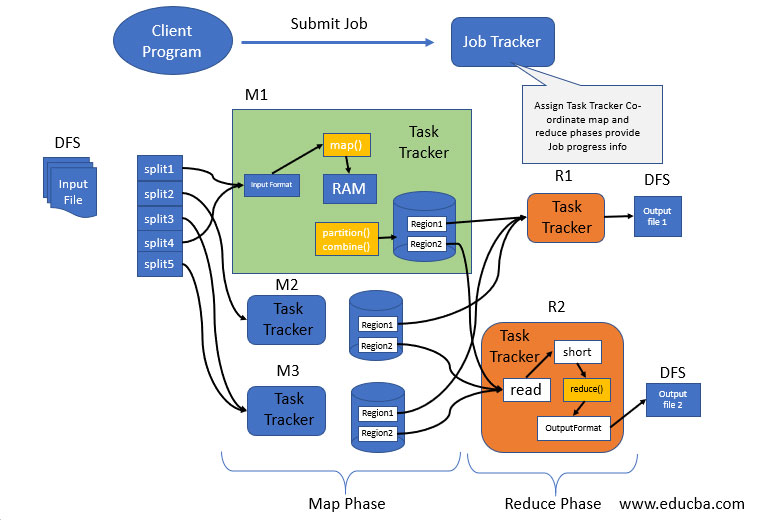
1. Map Phase
Map phase splits the input data into two parts. They are Keys and Values. Writable and comparable is the key in the processing stage where only in the processing stage, Value is writable. Let’s say a client gives input data to a Hadoop system; task tracker is assigned tasks by job tracker. Splitting of input is done into several inputs. Key-value pair conversion is done with the input data by the record reader. This is the actual data input for Map as in mapped information for further processing. The format type varies, so the coder has to look into each piece of data format and code accordingly.
Mini reducer which is commonly called a combiner, the reducer code places input as the combiner. Network bandwidth is high when a huge amount of data is required. Hash is the default partition used. The partition module plays a key role in Hadoop. More performance is given by reducing the pressure by petitioner on the reducer.
2. Processing in Intermediate
In the intermediate phase, the map input gets into the sort and shuffle phase. Hadoop nodes do not have replications where all the intermediate data is stored in a local file system. Round – robin data is used by Hadoop to write to local disk, the intermediate data. There are other shuffles and sort factors to be considered to reach the condition of writing the data to local disks.
3. Reducer Phase
The reducer takes in the data input that is sorted and shuffled. All the input data will be combined, and similar key-value pairs are to be written to the hdfs system. For searching and mapping purposes, a reducer is not always necessary. Setting some properties for enabling to develop of the number of reducers for each task. During job processing, speculative execution plays a prominent role. The performance is FIFO that is first in first out, and if more than one mapper is working on similar data, and if one is running slow, then the tasks are assigned to the next mapper for a fast program run by the job tracker.
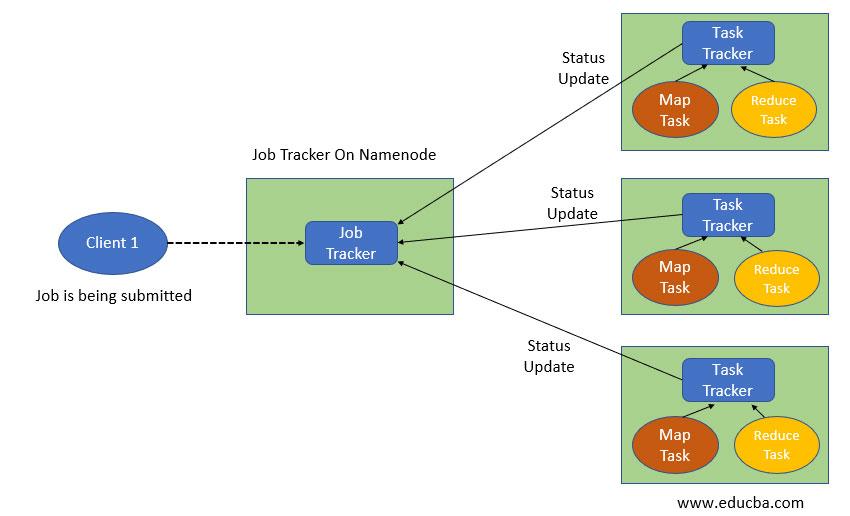
This is how MapReduce organizers work.
- The job is divided into two components: Map tasks (Splits and mapping) and Reduce tasks (Reducing and shuffling).
- The above picture says that Job tracker is associated with complete execution of a given job, by behaving like a master. Whereas, the Multiple task trackers act like slaves by performing the job each.
Conclusion
Imagine you have lots of documents, which is huge data. And you need to count the number of occurrences of each word throughout the documents. I might seem like an arbitrary task, but the basic idea is that let’s say you have a lot of web pages and you want to make them available for search queries. The reducer does aggregation of data, and it consists of all the keys and combines them all for similar key-value pairs which is basically the Hadoop shuffling process.
Recommended Articles
This is a guide to MapReduce Architecture. Here we discuss an introduction to MapReduce Architecture, explanation of components of the architecture in detail. You can also go through our other related articles to learn more –
