Updated March 16, 2023
Introduction to Kafka confluent
The Kafka confluent is defined as an open-source flowing and processing platform that can utilize to manage the concurrent storage of the data. Confluent is the data-outflowing platform that can establish based on Apache Kafka, which can not only produce and accept but also store and filter the data under a flow. The confluent is an extra concluded dispersal of the Apache Kafka. LinkedIn initially implemented Apache Kafka, and after that, it contributed to the Apache software foundation, and now it has been supported by the confluent.

What is Kafka confluent?
At first, Apache Kafka emerged on LinkedIn. After that, it became a project of Apache, Kafka written down in Scala and Java, and Apache Kafka brings out which depends on the fault-tolerant which is the messaging system, as it is rapid, extensible, and gives out by using design, as we already know that it is a software platform which can depend on the data flowing process. Therefore, the messaging system can publish and accept it, allowing us to interchange the data between various applications, servers, and processors.
- Messaging System: It is an easy way to swap data between two or more devices, and it can allow to convey and accept the explanation that messages in which the conveyor is known as the producer and accepter is also called a consumer which can ingest that message by taking it.
- The Streaming or Flowing Process: It is the process of flowing data in a connected equivalence system which can allow various applications to control or manage the flowing of data in which one record can accomplish the data without the output, and such type of flowing system can allow users to clarify the task of data flowing process in executing parallel implementation.
Why Use Kafka confluent?
Many users across the world can utilize Kafka confluent as it is a software platform that has some reasons for using it, which are given below:
- It can control large data storage, or we can say that it can control large messages per second.
- It works as an arbitrator for connecting the producer and the target system. The producer can send the data to Apache Kafka, where data can be decoupled, and the target system can overwhelm the data from Kafka.
- Combining historical and real-time data into a single and middle data into a single in which confluent can make it simple to construct an entirely new classification of present-time, event-driven applications. It can also unlock impressive new use cases with full connectivity, presentation, and solidity.
- It can give a high performance which means it can have low latency.
- It can have a resilient architecture that can prevent unexpected data-sharing difficulties.
- Various organizations like Walmart and NETFLIX can make use of Apache Kafka.
- It can also accomplish to support fault tolerance.
- Studying Kafka is a good origin of revenue hence those who wish to increase their income in the future.
Kafka confluent Connection
Connectors can be utilized for flowing the data from Apache Kafka and the target system, which can have two various types of connectors,
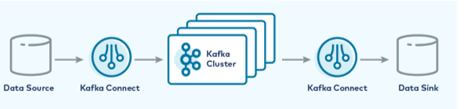
- Self-Managed Connectors for the confluent Platform: This connector has been used to copy data from Apache Kafka to the target system, which we have to bring in data from, or we can squeeze the data and we can download it from the confluent platform; there are various self-managed connectors such, JDBC source and sink, JMC Source, Elasticsearch Service Sink, Amazon S3 Sink, HDFS 2 Sink, and Replicator.
- Fully-Managed Connectors for the confluent Platform: This connector has been used to connect with external systems in which confluent, it has a straightforward UI that can be based on the configuration, and elastic scaling, which does not have the infrastructure for controlling, and the confluent connectors can affect data which is present in the process of flowing data having low latency.
a. Source connector: It can consume complete databases and flow table updates substitute to Kafka topics; it can gather periodically from our application servers and supply to make the data accessible to flow.
b. Sink connector: This connector can distribute data from Kafka into the secondary indicator.
Kafka confluent AWS Marketplace
The AWS marketplace in Kafka confluent is the digital software index that can be put together to make it simple to find, try, purchase, implement, and support the software which can move on the AWS; it has a large and intense choice of ISV blending which can assist in helping us to operate present-time applications implementation in the cloud.
Those products can be consolidated using the services of AWS and other existing technologies, allowing us to design, implement, and amend applications with the help of DevOps practice.
- The AWS marketplace is beneficial in finding the solution, which is 46% faster in which it can find the market-leading tools, and we need to orchestrate your absolute DevOps toolchain.
- It can also be beneficial to acquire new tools, which are 53% faster; hence, it can lead the developer tool and clarify acquisition using unified AWS billing.
- It can also implement our path, which is 48% faster in implementing DevOps solutions using methods that can be the most acceptable way of using the containers.
- It can also trust AWS interoperable technologies, including tools designed for AWS interworking and regularly examined for security purposes.
Conclusion
In this article, we conclude that the Kafka confluent is a platform that can be available to manage real-time data storage; we have also discussed why to use the Kafka confluent, the Kafka confluent connection, and the AWS marketplace.
Recommended Articles
This is a guide to Kafka confluent. Here we discuss the introduction; why use Kafka confluent? Connection and AWS marketplace. You may also have a look at the following articles to learn more –
