Updated March 4, 2023
Introduction to Kafka Use Cases
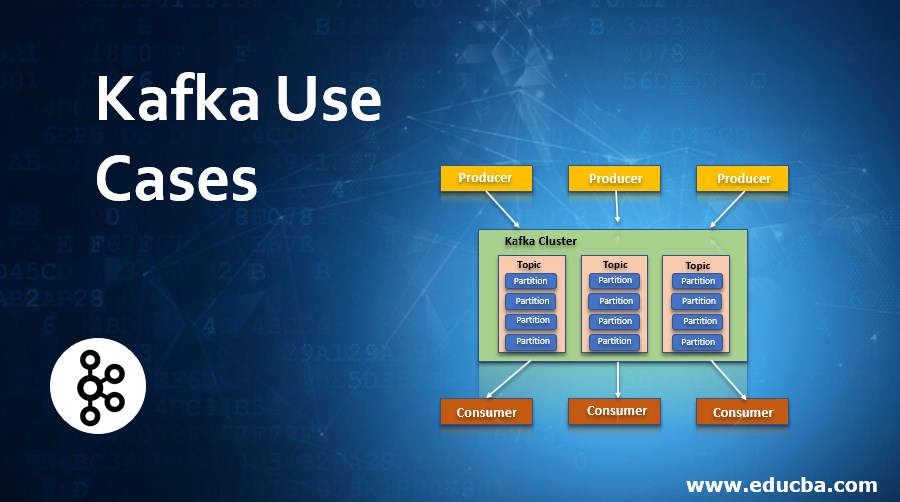
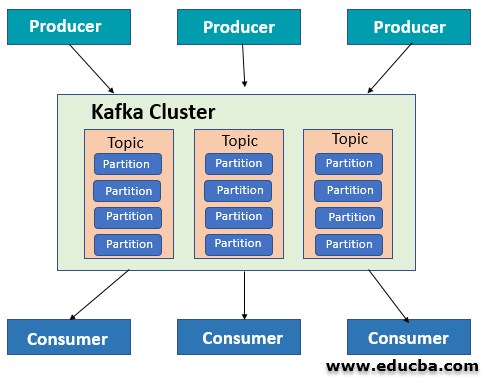
Apache Kafka is an open-source streaming platform used to Publish or subscribe to a stream of records in a fault-tolerant(operating in event of failure) and sequential manner. It can also be termed as a distributed persistent log system. Kafka runs as a cluster on multiple servers which stores streams of records in topics. The data is published to topics by producers and consumed by Consumers. In this topic, we are going to learn about Kafka Use Cases.
Kafka handles trillions(petabytes) of data on a daily basis with diverse use cases in the industry. Major IT giants like Twitter, LinkedIn, Netflix, Mozilla, Oracle uses Kafka for data analytics. From core IT to Manufacturing industries, Companies are incorporating Kafka to harness their huge data. The following are the major use cases.
- Traffic data monitoring
- Real-time Fraud detection
- Communication between services
- Transforming ETL pipeline to real-time streaming pipeline
- Website tracking
Why do we need Kafka to Use Cases?
- It supports multiple languages and provides backward compatibility with older clients.
- Handles large amounts of data with high throughput and can continue processing even in case of node failure.
- Overcomes the problems of traditional messaging systems like RabbitMQueue, ActiveMQ by providing built-in partitioning and data replication.
- Uses commit log data structure for storing messages and replicating data between nodes. Also, implements a Message retention policy to avoid data loss.
- Kafka server does not maintain the consumer/downstream data information and hence saves the complexity overhead.
- Guarantee’s Ordering of messages.
- Effectively used for monitoring operational data.
Detailed Use Cases
Here are the detailed use cases mentioned below
1. Traffic data monitoring
IoT creates a better and efficient network of connected vehicles on the road which generates an enhanced navigation system, Real-time traffic updates, weather alerts, etc. IOT along with big data applications including Kafka can be used to produce and monitor real-time traffic data based on different routes. The following use case illustrates the technique.
- Connected vehicles generate IOT which are captured by Kafka message broker and are sent to streaming Application for processing.
- Spark Streaming application consumes IOT data streams and process/transform them for traffic data analysis.
- In the Spark application, the total vehicle count for different vehicles is counted and stored in a NoSQL database.
- Finally, a UI dashboard is created which fetches data from the database and sent to the web page. Bootstrap.js can be used to display the data on mobile/ desktop devices.
2. Real-time fraud detection
Fraud detection is the primary use case concern for many financial, retail, govt. Agencies. With the rising digital transactions, online frauds are increasing continuously. Here, Credit card transactions can be traced based on the spending activities of the user. In this, Kafka along with other Big data applications and machine learning models can be used to capture and predict fraudulent activities based on the available real-time data.
In the use case,
- Kafka ingests the transaction events. The events are written in Kafka’s topics as nonfraudulent.
- Spark Streaming receives the streaming data and performs transformations on the stream data to get the necessary credit card details.
- The historical data and real-time data are cross-checked to analyze any discrepancies. If the transaction is over the limit of regular spending, it is written to the fraud Kafka topic.
- The fraud-labeled topic is further analyzed to study customer behavior and stored in NoSQL databases like HBase.
3. Real-time data Pipeline
Linkedin is a professional network site which manages data for numerous professional across the globe. Kafka was initially recognized by Linkedin to leverage the large data and create a smooth user experience. Below is the Linkedin use case.
- A centralized data pipeline is created using Kafka connect which connects various components including, operational metrics, data warehousing, security, User tracking, etc.
- Data is sent to local Kafka clusters and replicated to other clusters
- Kafka consists of an aggregated Commit log which helps in high throughput.
- Kafka handles over 10 billion messages/day with 172000 messages/second with minimum latency as per Linkedin record.
- This real-time-based approach has effectively replaced the ETL approach earlier used by Linkedin to manage the services and its data.
4. Communication between services
Traditional standalone software architecture is being replaced by Microservices these days. From core IT to banking to manufacturing sectors, all the monolithic systems are being decommissioned to incorporate the cloud.
Microservices decouples the singleton architecture to create multiple independent services. Hence, communication between the components becomes important and Apache Kafka is the appropriate choice for creating such a communication bridge. The use case shows steps to creating a microservice and using Kafka.
- Configure Kafka instance and configure Producer Api to send data to the broker server in JSON format.
- Configure Consumer Api to deserialize the JSON data to Java Object and setup Kafka Listener for listening to topics.
- Setup Zookeeper for orchestration.
- Test and implement the services to check the flow of the application.
5. Web Site Activity Tracking
E-commerce is a very lucrative industry for big data analysis. Online retailers tend to analyze user behavior to enhance their products. Also, Customers are classified based on their views and choices and hence product placements can be optimized.
- ClickStreaming is used to track user activity by recording users tapping and click activity.
- The recorded data is stored in JSON format on Hdfs.
- Kafka is used to ingesting the recorded data in topics and process the data. Eg. Taking an input stream of sales and processing an output stream of reorders and process adjustment.
- The topics are available for multiple consumers to read and monitor the data in real-time.
- Using spark streaming to process or transform the clickstream data for further analysis.
- Visualizing the data using Tableau in sheets and charts.
Conclusion
Apache Kafka is widely being used in big data applications and primarily for handling real-time data. It is efficiently transforming the former ETL (Extract Transform Load ) pipeline methodology. It is also being predicted that this Streaming Platform can be big as a relational database due to its reliability, scalability, and throughput.
Recommended Articles
This is a guide to Kafka Use Cases. Here we discuss Why do we need Kafka to Use Cases and also explain the major and detailed Use Cases. You may also have a look at the following articles to learn more –
