Updated March 22, 2023

Introduction to Join in Spark SQL
Join in Spark SQL is the functionality to join two or more datasets that are similar to the table join in SQL based databases. Spark works as the tabular form of datasets and data frames. The Spark SQL supports several types of joins such as inner join, cross join, left outer join, right outer join, full outer join, left semi-join, left anti join. Joins scenarios are implemented in Spark SQL based upon the business use case. Some of the joins require high resource and computation efficiency. For managing such scenarios spark support SQL optimizer and cross join enabler flags features.
Types of Join in Spark SQL
Following are the different types of Joins:
- INNER JOIN
- CROSS JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
- LEFT SEMI JOIN
- LEFT ANTI JOIN
Example of Data Creation
We will use the following data to demonstrate the different types of joins:
Book Dataset:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Writer Dataset:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin",1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Types of Joins
Below are mentioned 7 different types of Joins:
1. INNER JOIN
The INNER JOIN returns the dataset which has the rows that have matching values in both the datasets i.e. value of the common field will be the same.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. CROSS JOIN
The CROSS JOIN returns the dataset which is the number of rows in the first dataset multiplied by the number of rows in the second dataset. Such kind of result is called the Cartesian Product.
Prerequisite: For using a cross join, spark.sql.crossJoin.enabled must be set to true. Otherwise, the exception will be thrown.
spark.conf.set("spark.sql.crossJoin.enabled", true)
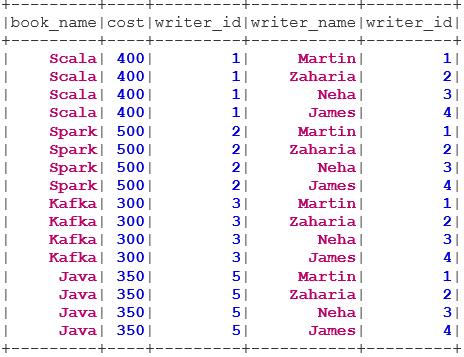
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. LEFT OUTER JOIN
The LEFT OUTER JOIN returns the dataset that has all rows from the left dataset, and the matched rows from the right dataset.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. RIGHT OUTER JOIN
The RIGHT OUTER JOIN returns the dataset that has all rows from the right dataset, and the matched rows from the left dataset.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. FULL OUTER JOIN
The FULL OUTER JOIN returns the dataset that has all rows when there is a match in either the left or right dataset.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. LEFT SEMI JOIN
The LEFT SEMI JOIN returns the dataset which has all rows from the left dataset having their correspondence in the right dataset. Unlike the LEFT OUTER JOIN, the returned dataset in LEFT SEMI JOIN contains only the columns from the left dataset.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()

7. LEFT ANTI JOIN
The ANTI SEMI JOIN returns the dataset which has all the rows from the left dataset that don’t have their matching in the right dataset. It also contains only the columns from the left dataset.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Conclusion
Joining data is one of the most common and important operations for fulfilling our business use case. Spark SQL supports all the fundamental types of joins. While joining, we need to also consider performance as they may require large network transfers or even create datasets beyond our capability to handle. For performance improvement, Spark uses SQL optimizer to re-order or push down filters. Spark also restrict the dangerous join i. e CROSS JOIN. For using a cross join, spark.sql.crossJoin.enabled must be set to true explicitly.
Recommended Articles
This is a guide to Join in Spark SQL. Here we discuss the different types of Joins available in Spark SQL with the Example. You may also look at the following article.
