Updated March 13, 2023

Introduction to Hive insert into
As with all other databases, the HIVE, a sequential database, also expects data to be inserted. In the case of HIVE, this insert process can be performed in two ways the Load based insert and the insert query insert. Here the insert query-based insert allows to store or place data into the table from a parent table. So, when an insert query has been executed, all records from the parent table or the staging table will be copied and inserted into the current table. This is how the HIVE-based insert works. On top of this, the HIVE-based insert allows inserting the records using partitioning and various other processes. The Insert query executed in HIVE, which copies records from a different table, will be inserted into this current table with a map-reduce-based job triggered in the background.
Syntax:
INSERT OVERWRITE TABLE TABLE_NAME PARTITION SELECT COLUMN_VALUES FROM TABLE_NAME;The syntax of the Insert query is as above. First, the Insert value is used to mention that the operation is an insert. Next, a overwrite statement is specified if the records are expected to overwrite the previously present records at the destination. The overwrite process is followed by the table statement. The table statement has the table name associated with it then the partition statement is used to set the partition values. The partitions of the table are mentioned here. Finally, the select column values have all the column values listed here. The values in these column names will be inserted into the table. This select statement column will be the input values for the database insert, and the values will be taken from the table listed in the table name.
Examples of Hive insert into
Here are the following examples mention below
Example #1
Table creation Query:
CREATE TABLE Table_view(Time_viewed INT,
Id_User BIGINT,
url_of_pages STRING,
url_to_be_reffered STRING,
ip_value STRING COMMENT 'user ip')
COMMENT 'This is the staging page view table'
PARTITIONED BY(date STRING, country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;Table Insertion Query:
from Table_view_stage pvs
insert overwrite table Table_view partition (dt='09/30/2011', country='US')
select pvs.Table_view_Time_viewed,
pvs.Table_view_Id_User,
pvs.Table_view_page_url,
pvs.Table_view_referrer_url,
pvs.Table_view_ip;Output:
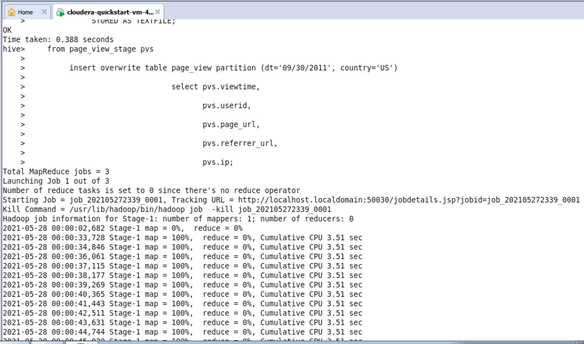
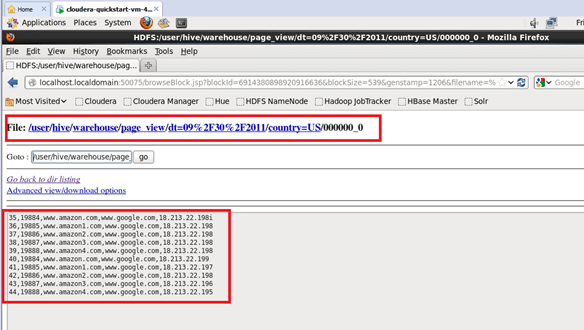
Explanation:
The records from the Table_view_stage table will be inserted into the table, and the reference snaps for the same is placed in the output section. We can notice from the inserted records that the initial table which has been created is portioned. As far as the staging table and the subdivision of the staging table are concerned, two different partitions are used. The first partition is representing the date on which the data is expected to be inserted into the Hive table. So these details are mentioned in the insert query with relation to the insertion date of the data as a partition. Next, after the date of record insertion, the other value which has been used for partitioning the table is the country of insertion. These partitions being expressed in the insertion will help the data to be searched very smoothly.
The country of data generated and the date on which the data is generated brings in a large amount of flexibility in searching the data through a select query. This is how portioning works in Hadoop file systems and allows us to bring a large amount of flexibility. The partition values followed during the insert are dt=09/30/2011, country=US. We can also notice from the map-reduce jobs triggered in the background on the number of mappers and reducers triggered in this process. The map-reduce jobs for this case of the insert are around three. From the map-reduce jobs involved, we can clearly notice 100% mapping and 100% reducing taking place in the process. The HDFS Read: 879 HDFS Write: 539 SUCCESS mentions the total read and write process involved.
Example #2
Table Insertion Query:
from Table_view_stage pvs
insert overwrite table Table_view partition (dt='29/31/2021', country='IND')
select pvs.Table_view_Time_viewed,
pvs.Table_view_Id_User,
pvs.Table_view_page_url,
pvs.Table_view_referrer_url,
pvs.Table_view_ip;Output:
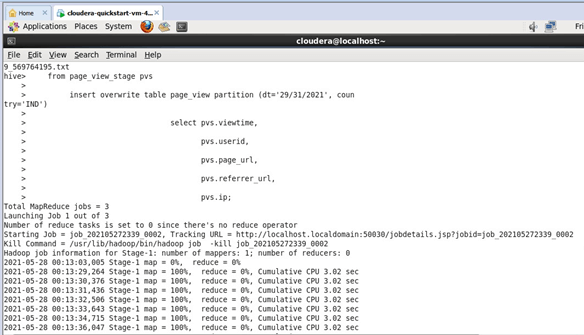
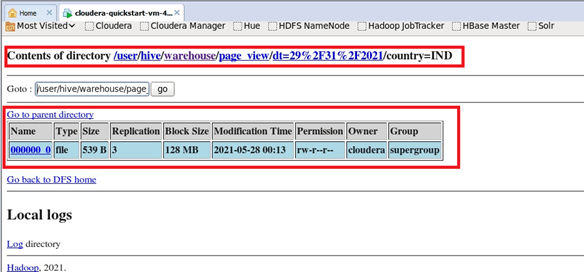
Explanation:
Again just like the above given first example here too the records are inserted into the expected staging table. Here the staging table used is also the same as the above case. The staging table Table_view_stage table records will be inserted into the child table, and the reference snaps for the same is placed in the output section, but the key difference here from the above example is the parameters of the partition used. The partition values used here are very different from the partition values used in the above table. So though the tables used are the same, the way in which the values are stored differs. In the second example, the date of insertion is manipulated along with the country too.
In the first example, the value of the country for partition was the US which represents the united states of America. In this second example, the country used for the insert is India, and the date value has also been changed. As mentioned in the above case, these partitions being expressed in the insertion will help the data be searched very smoothly. The country of data generated and the date on which the data is generated brings in a large amount of flexibility in searching the data through a select query. This is how partitioning works in Hadoop file systems and allows us to bring a large amount of flexibility. The records from the Table_view_stage table will be inserted into the Table_view table, but at this instance, the insertion partition values are changes as like dt=29/31/2021, country=IND, and then inserted is the major difference at this instance of the example.
Conclusion
The biggest flexibility of the Hive inserts is that being a bulk loaded system, yet the HIVE insert process is introduced in a flexible manner such that the inserts are Optimizely performed. This allows the capability to insert huge sets of records into the database. Furthermore, these huge portions of records inserted will be performed quickly because of the backend map-reduce sections triggered. This is the key advantage of the hive platform itself.
Recommended Articles
This is a guide to Hive insert into. Here we discuss the Examples of Hive insert into along with the outputs and explanation. You may also have a look at the following articles to learn more –
