Updated March 4, 2023
Introduction to Hadoop data lake
The Hadoop data lake is a data management platform. It will include the multiple-cluster environment of Hadoop. It will help to process the structure or non-structure data. The data will be in different verity like log data, streaming data, social media data, internet click record, sensor data, images, etc. It is also having the capability to hold the transactional level data. It will also pull it from the RDBMS. A number of components, multiple technologies come into the picture. It is not only stuck with the Hadoop technology only.
Note: The architecture is suitable for non-transactional data.
Syntax
As such, there is no specific syntax available for the Hadoop data lake. Generally, we are using several technologies in it. As per the requirement or need, we can use the necessary components of the Hadoop data lake and use the appropriate syntax it.
How does Hadoop Data Lake Works?
The Hadoop and the data lake both are different terms. We cannot molde both the Hadoop and the data lake in a single window. The Hadoop is a technology stack and the data lake is architecture. With the help of both things, we can develop the Hadoop data lake platform.
In the Hadoop data lake, we are having the combination of multiple technologies like Hadoop, BI, data warehouse, different applications, etc. In this, we can use any commodity hardware to build the Hadoop data lake. On the commodity hardware, we can use the HDFS file system to store the Hadoop level data in a distributed manner. We can also use different cloud storage platforms like Amazon S3, Azure DLS, etc. As per the use case or the client requirement, we can incorporate the multiple technologies or stack in the data lack implementation.
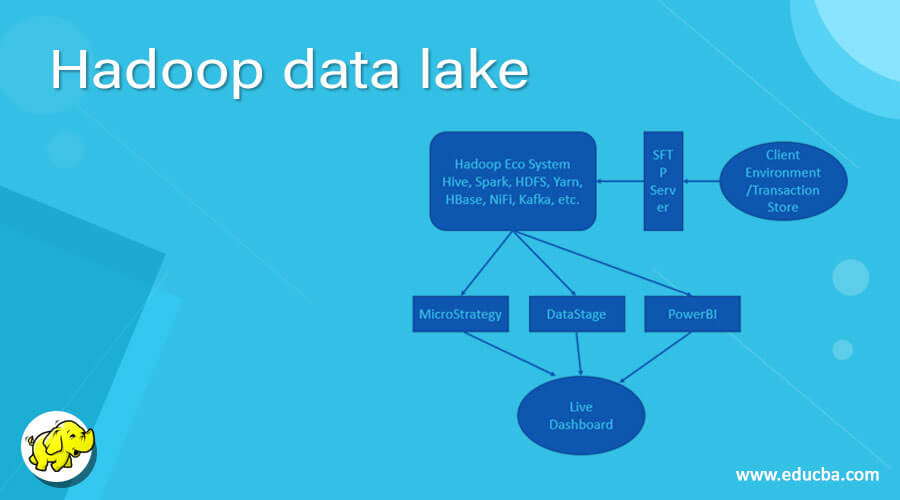
As per the below diagram, we are elaborate more on the data lake platform.
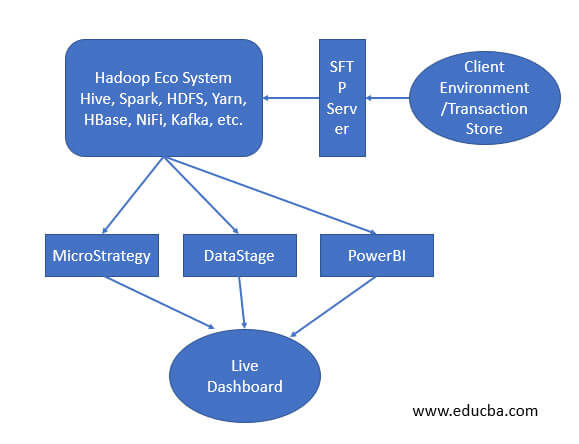
As we have discussed, the Hadoop data lake is architecture and the Hadoop is technology. As per the above diagram, we are going through the above use case.
Use Case: There are multiple stores on different geographic. There are different varieties of data and different formats like JSON, Avro, Excel, Text format, etc. All the data formats having different information like transaction data, sales data, inventory data, etc. We need to capture all the information. The data might be in structure or unstructured format. We need to work on the data and make it in a meaningful format. Once, the data will be available in the correct format. We need to pass it to the downstream system. Then the downstream systems will accept the finished data. On top of data, it will create a live dashboard on it. We can see the live data of the transaction, inventory, sales, etc.
Hadoop Data Lake Implementation
As we have discussed in the above case study. We need to work on it i.e. how to implement the solution with the help of Hadoop and other technologies.
We are having multiple stores in different geographies. Every store having there different types of data like sales data, store information, location, product description, product information, product quantity, etc. The store is having different data formats like JSON, Avro, Excel, Text format, etc. From the store, the same file will be uploaded to the SFTP location. While uploading the data, they are following the specific hierarchy on the SFTP.
Once the data will be available on the SFTP, we are using the SSH or NFS protocol, to get the same uploaded by the store. While capturing the data from SFTP, we need to write different validations like to avoid the copy, to avoid the multiple data copies, does not copy the same tags, etc.
As we have discussed, we are using the SSH or NFS protocol to copy the data from SFTP to the Hadoop environment. We are storing the data on the HDFS level. As per the data volume, we need to have the x3 times of HDFS storage.
Example: If you want to store the 1 TB data on HDFS level. Then we need to have a minimum of 3 TB storage (except OS storage).
In the Hadoop stack, we are having multiple services like the hive, hdfs, yarn, spark, HBase, oozie, zookeeper, etc. As per the requirement, we can use the hive, HBase, spark, etc.
By default, we need to use the HDFS for storage purpose. For resource scheduling, we are using the yarn service. We are having different execution engines in Hadoop like Tez, MapReduce. With the help of the hive, we can use the SQL queries. For the column storage, we are using the HBase. As per the requirement or use case, we are using the Hadoop service.
Once the data was transformed, we are storing the data on the HDFS level. For real-time data capturing we are using different services like NiFi or Kafka. On top of finished data, we need to do a different analysis. For that, we need to use different tools like MicroStrategy, Datastage, PowerBi, etc. With the help of these tools, we are creating different reports on top of this. Every tool having its own different functionality. As per the requirement, we can choose the BI technologies for the reporting front. We can also use the API calls, to fetch the relevant data information quickly. We can write the API in a different language like java, python, etc.
Conclusion
We have seen the uncut concept with the proper use case, explanation, and implementation method. The Hadoop data lake is nothing but architecture. Hadoop is technology. With help of Hadoop and different technologies, we can build the data lake. We can build it on normal commodity hardware or the cloud as well.
Recommended Articles
This is a guide to Hadoop data lake. Here we discuss the uncut concept of “Hadoop Data Lake” with the proper use case, explanation, and implementation method. You may also have a look at the following articles to learn more –
