Introduction
Within the expansive domain of C++ programming, function prototypes emerge as foundational pillars for cultivating organized, efficient, and resilient code development. They erect complex software systems upon the cornerstones they represent, guiding the compiler through code labyrinths and providing vital insights long before function implementation. Like heralds, prototypes anticipate function arrivals, imparting fundamental essences like return type, name, and parameters to the compiler. Much like master architects draft blueprints, prototypes meticulously outline function structural integrity, clarifying purpose and functionality. They lay the groundwork for intricate code interplay, establishing scaffolding for compilers to conduct symphonies of syntax checks and type validations. Function prototypes are dynamic catalysts in the grand tapestry of software development, propelling progress and fostering cohesive ecosystems by enabling anticipation of code module interdependencies.
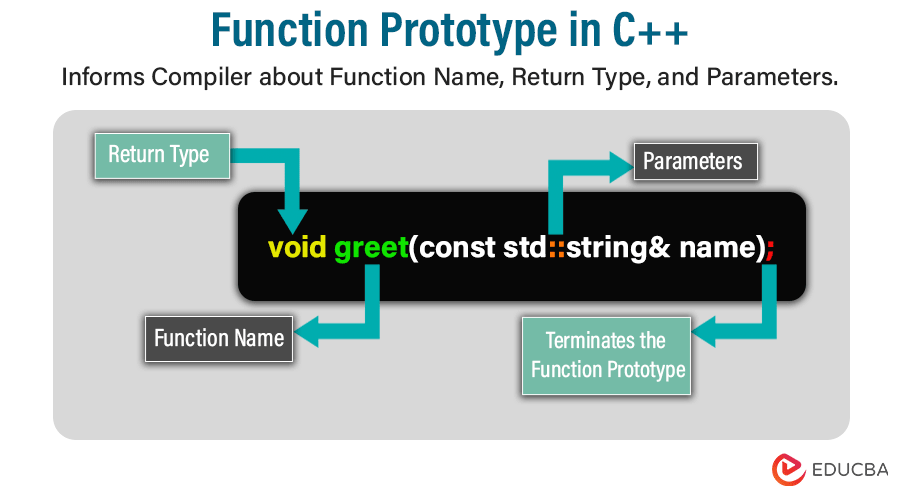
Table of Contents
Anatomy of a Function Prototype
Understanding the Syntax
The syntax governing function prototypes in C++ follows a structured format:
Syntax:
return_type function_name(parameter_list);This syntax reveals its key components:
- return_type: This component denotes the value’s data type that the function will return upon execution. It encapsulates a spectrum of possibilities, from fundamental data types like integers and floating-point numbers to intricate user-defined types like classes or structs.
- function_name: Central to the function’s identity, the function name serves as a unique identifier within its scope. Following the rules of C++ identifier naming conventions, it signifies the callable entity within the program, embodying its purpose and functionality.
- parameter_list: Here lies the roster of parameters the function anticipates receiving during invocation. Each parameter declaration pairs a data type with a corresponding parameter name, separated by commas. This list remains void or populated with the void keyword even without parameters.
Example
Code:
#include
using namespace std;
// Declaring a Function prototype
int square(int x);
int main() {
int number;
cout << "Enter a number: "; cin >> number;
// Calling the function
int result = square(number);
cout << "The square of " << number << " is: " << result <<endl;
return 0;
}
// Function definition
int square(int x) {
return x * x;
}Output:
![]()
Explanation:
- Function Prototype Declaration: Before the main() function, we declare a function prototype for a function named square. This prototype informs the compiler about the existence and signature of the square function. It specifies that square takes an integer parameter (int x) and returns an integer (int).
- Main Function: Inside the main() function, we prompt the user to input a number. Then, we call the square function with the entered number as an argument and assign the result to the result variable.
- Function Definition: Below the main(), It takes an integer parameter x and returns the square of x (x * x).
Why Use Function Prototypes in C++?
Function prototypes are more than just a syntactical requirement in C++ programming; they are pivotal in enhancing code organization, readability, and maintainability. Here are several reasons why utilizing function prototypes is beneficial:
- Facilitating Top-Down Program Design: Function prototypes enable a top-down program design approach, empowering developers to establish the structure and interfaces of functions before delving into their implementations. This hierarchical method fosters modularity and abstraction, simplifying the management of intricate codebases by segmenting them into smaller, more understandable units.
- Ensuring Type Safety: Developers can ensure type safety within their code by explicitly declaring return types and parameter lists in function prototypes. This proactive measure mitigates errors from mismatched data types or improper function utilization, as the compiler identifies such discrepancies during compilation rather than runtime.
- Preventing Errors: Function prototypes act as preemptive error indicators in code, alerting the compiler to potential issues such as misspelled function names, absent function implementations, or inconsistencies between declarations and definitions. This proactive error detection mechanism aids in identifying and resolving issues before they escalate into runtime errors, thereby refining code reliability and expediting the debugging process.
- Enhancing Code Readability: Function prototypes offer a brief overview of a program’s functions, enhancing codebase readability and comprehension. Developers can swiftly consult function prototypes to grasp their objectives, anticipated inputs, and outputs without sifting through extensive code sections. This enhancement fosters collaboration among team members and simplifies maintenance activities.
Where to Place Function Prototypes?
Determining the optimal placement of function prototypes within a C++ program is crucial for maintaining code organization, readability, and adherence to best practices.
- Before main(): A conventional approach places function prototypes before the main() function within the same file. It ensures all function declarations are accessible to the compiler before any function calls occur within the main(). While this method is suitable for small to medium-sized programs, it may lead to cluttered source files in larger projects.
Example:
#include
using namespace std;
// Function prototypes before the main()
void greet();
int add(int a, int b);
int main() {
greet(); // Function call
int result = add(3, 4); // Function call
cout << "Result of addition: " << result << endl;
return 0;
}
// Function definitions
void greet() {
cout << "Hello, world!" << endl;
}
int add(int a, int b) {
return a + b;
}Output:
![]()
- Header Files: In larger projects or when implementing modular designs, Developers often place function prototypes in header files (.h or .hpp files) separate from the implementation files (.cpp files). Header files contain declarations of functions, classes, and other entities used across multiple source files. By including the necessary header files at the beginning of each source file, developers can ensure that function prototypes are visible wherever needed, promoting code reusability and modularity.
Example:
functions.h
#ifndef FUNCTIONS_H
#define FUNCTIONS_H
// Function prototypes
void greet();
int add(int a, int b);
#endiffunctions.cpp
#include "functions.h"
#include
using namespace std;
// Function definitions
void greet() {
cout << "Welcome to EDUCBA!" << endl;
}
int add(int a, int b) {
return a + b;
}main.cpp
#include
#include "functions.h" // Include the header file
using namespace std;
int main() {
greet(); // Function call
int result = add(7, 5); // Function call
cout << "Result of addition: " << result << endl;
return 0;
}Output:
![]()
In this example, We declared the function prototypes in the functions.h header file. Then, we included the header file in the main.cpp source file using #include “functions.h”. This approach separates the function declarations from the main program logic, promoting modularity and code reuse.
Examples of Function Prototypes
Example 1: Basic Function Prototype
Code:
include
using namespace std;
// Function prototype declaration
void displayMessage();
int main() {
// Function call
displayMessage();
return 0;
}
// Function definition
void displayMessage() {
cout << "Welcome to the domain of EDUCBA Learning!!!" << endl;
}Output:
![]()
We have a basic function prototype displayMessage() declared before main(). This function prototype does not specify any parameters or return type. The function is defined later in the code and displays a welcome message when called.
Example 2: Function Prototype with Parameters
Code:
#include
using namespace std;
// Function prototype declaration
int multiply(int a, int b);
int main() {
int result = multiply(335, 75); // Function call with arguments
cout << "Product: " << result << endl;
return 0;
}
// Function definition
int multiply(int a, int b) {
return a * b;
}Output:
![]()
We have a function prototype multiply() declared before main(), specifying two integer parameters, a and b, and an int return type.
Example 3: Function Prototype with Return Type
Code:
#include
// Function prototype declaration
double calculateCircleArea(double radius);
int main() {
double area = calculateCircleArea(9.0); // Function call with argument
std::cout << "Circle area: " << area << std::endl;
return 0;
}
// Function definition
double calculateCircleArea(double radius) {
return 3.14159 * radius * radius;
}Output:
![]()
The code declares a function prototype for calculateCircleArea() with a double return type. It then calls the function in main() with a radius value 9.0. This example showcases how function prototypes specify the return type of a function, ensuring consistency between the declared and actual return values.
Function Prototype vs. Function Definition
| Section | Function Prototype | Function Definition |
| Role | Declaration of a function’s interface. | Actual implementation of the function. |
| Purpose | Informs the compiler about the function’s existence, name, return type, and parameters. | Defines the behavior and logic of the function. |
| Syntax | Includes return type, name and parameter list, terminated by semicolon. | Includes return type, name, parameter list, and function body enclosed within curly braces. |
| Placement | Typically placed at the beginning of a program or in header files. | Typically follows the prototype and can be placed anywhere in the program. |
| Example |
|
|
Forward Declarations in C++
Forward declarations are a mechanism in C++ used to declare the existence of a class, function, or variable before providing its full definition. This mechanism enables referencing entities before they are fully defined, enabling greater flexibility in program design.
Forward declarations allow the compiler to know about an entity’s existence without requiring its complete definition at that point in the code. It is useful in scenarios where entities must reference each other or when reducing compilation dependencies.
Usage
- Classes: Forward declarations frequently establish class relationships, notably in header files where classes may need to refer to each other. This practice helps avert circular dependencies and minimizes compilation duration.
- Functions: Programmers find forward declarations valuable when they define functions they invoke before their complete definitions are accessible. This situation arises in scenarios of mutual recursion or when defining functions across separate files.
- Variables: Forward declarations for variables are commonly employed in declaring global variables within header files shared across numerous source files.
Benefits
Forward declarations offer several advantages:
- Reduced Compilation Dependencies: They diminish dependencies between header files, lessening the need for recompilation when they change.
- Enhanced Compilation Time: Declaring entities before their definition can expedite compilation, particularly in sizable projects with intricate interdependencies.
- Improved Modularity: Forward declarations foster modularity and separation of concerns by enabling entities to be declared independently of their full definition.
Drawbacks
- Increased Complexity: Overusing forward declarations can make code more complex to understand and maintain, mainly if many interdependent entities exist.
- Risk of Mistakes: Incorrect or missing forward declarations can result in compilation errors or runtime issues, making it important to ensure their accuracy.
Advanced Topics
Inline Function Prototypes
Inline functions, often compact and frequently utilized, are expanded by the compiler at the moment of invocation rather than through a traditional function call. Inline function prototypes indicate that the function ought to be expanded inline. This approach can enhance performance by mitigating function call overhead. Nonetheless, excessive reliance on inline functions may inflate code size. A comprehensive understanding of when and how to employ inline function prototypes is pivotal for optimizing performance-sensitive code.
Example:
#include
#include
using namespace std;
// Inline function prototype
inline int countUniqueElements(int arr[], int size);
int main() {
int arr[] = {25,22,23,23,21,24,22,21,20};
int size = sizeof(arr) / sizeof(arr[0]);
int uniqueCount = countUniqueElements(arr, size); // Function call
cout << "Number of unique elements: " << uniqueCount << endl;
return 0;
}
// Inline function definition
inline int countUniqueElements(int arr[], int size) {
unordered_set uniqueElements;
for (int i = 0; i < size; ++i) {
uniqueElements.insert(arr[i]);
}
return uniqueElements.size();
}Output:
![]()
The countUniqueElements() function is declared inline using the function prototype. It informs the compiler to expand the function inline wherever the code calls it. The function calculates the unique elements in the provided array using an unordered set and returns the count. Using an inline function in this context can improve performance by reducing function call overhead.
Template Function Prototypes
Template function prototypes declare the presence of template functions without specifying the specific data types they will handle. This fosters code reusability and adaptability, enabling a single function to work with various data types. Proficiency in template function prototypes is crucial for harnessing the complete capabilities of C++ generics and the Standard Template Library (STL).
Example:
#include
// Template function prototype
template
T maximum(T a, T b);
int main() {
int intMax = maximum(5, 10); // Function call with int arguments
double doubleMax = maximum(3.5, 7.8); // Function call with double arguments
std::cout << "Maximum of integers: " << intMax << std::endl;
std::cout << "Maximum of doubles: " << doubleMax << std::endl;
return 0;
}
// Template function definition
template
T maximum(T a, T b) {
return (a > b) ? a : b;
}Output:
![]()
We declare maximum() as a template function using the function prototype. The template parameter T allows the function to accept arguments of any data type. It enables code reuse and flexibility, as developers may use the same function with different data types.
Function Overloading and Prototypes
Function overloading permits the creation of several functions that share the same name but differ in their parameter lists. Developers can overload functions with different data types, regardless of whether they use prototypes. Function overloading with prototypes entails declaring multiple function prototypes with identical names but distinct parameter lists. This practice notifies the compiler about the presence of overloaded functions, facilitating type-checking during function calls. A comprehensive grasp of function overloading and its interplay with prototypes is essential for crafting lucid, articulate, and polymorphic code.
Example
#include
using namespace std;
// Function prototypes for overloaded functions
void display(int num);
void display(double num);
void display(char ch);
int main() {
display(5); // Calls display(int)
display(3.5); // Calls display(double)
display('A'); // Calls display(char)
return 0;
}
// Function definitions for overloaded functions
void display(int num) {
cout << "Integer: " << num << endl;
}
void display(double num) {
cout << "Double: " << num << endl;
}
void display(char ch) {
cout << "Character: " << ch << endl;
}Output:
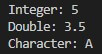
We overload the display() function with three different parameter types: int, double, and char. Each function version is declared with a separate function prototype, enabling the compiler to perform type-checking and resolve function calls appropriately based on the argument types.
Best Practices
- Modularization:
- Divide your code into modular components, each handling a specific task or functionality.
- Utilize functions, classes, and namespaces to logically encapsulate and organize your code.
- Modularization enhances code readability, maintainability, and reusability.
- Consistent Naming Conventions:
- Adhere to uniform naming conventions for variables, functions, classes, and other identifiers.
- Employ descriptive names that clearly express the purpose and functionality of each entity.
- Consistent naming fosters code clarity and facilitates comprehension and maintenance.
- Code Documentation:
- Thoroughly document your code using comments and documentation tools like Doxygen.
- Offer explanations for intricate algorithms, significant decisions, and obscure code segments.
- Concise and transparent documentation aids other developers in comprehending your code and expedites the development process.
- Error Handling and Exception Safety:
- Implement robust error-handling mechanisms to manage unexpected situations gracefully.
- Reserve exceptions for exceptional circumstances and employ error codes for anticipated errors.
- Ensure exception safety by adeptly managing resources and preserving the integrity of the program’s state.
- Memory Management:
- Embrace RAII (Resource Acquisition Is Initialization) and leverage smart pointers, such as std::unique_ptr and std::shared_ptr, for secure resource management.
- Minimize manual memory management to mitigate the risk of memory leaks and resource conflicts.
- Employ containers and algorithms from the Standard Template Library (STL) to handle dynamic memory allocation and deallocation.
Conclusion
Understanding the nuances of function prototypes in C++ is paramount for crafting efficient and maintainable software solutions. Adherence to best practices such as modularization, consistent naming conventions, thorough documentation, robust error handling, and efficient memory management ensures code quality and readability. Function prototypes, features like templates, inline functions, and function overloading empower developers to create versatile applications across diverse domains. By mastering function prototypes and embracing best practices, developers can harness the complete capabilities of C++ to tackle intricate challenges and produce groundbreaking solutions.
Frequently Asked Questions (FAQs)
Q1. Are function prototypes necessary in every C++ program?
Answer: Although not mandatory in every program, employing function prototypes is widely recommended because they aid in error detection and ensure type safety. It is especially beneficial in extensive projects where functions are declared across multiple files or referenced before implementation.
Q2. Can a function prototype be declared inside another function?
Answer: Declaring a function prototype within another function is not feasible in C++. Usually, function prototypes are declared either globally or within a namespace, class, or header file.
Q3. Do function prototypes affect the size of the compiled executable?
Answer: Function prototypes do not impact the size of the compiled executable. The compiler primarily utilizes them for type checking and ensuring proper function usage without adding to the executable file size.
Recommended Articles
We hope that this EDUCBA information on “Function Prototypes in C++” was beneficial to you. You can view EDUCBA’s recommended articles for more information,

