Updated August 10, 2023

Introduction to Fog Computing
Fog computing is a mid-layer between cloud data centers and IoT devices/sensors. It provides services of computation along with storage and networking at the proximity of the IoT devices/sensors. The fog computing concept is derived from Edge computing. Edge computing promises to bring data computation closer to the data origin. Edge devices, in Edge computing, aren’t able to support multiple applications in IoT because of their limited resources, resulting in resource contention and increased latency. It assimilates edge devices and cloud resources to overcome limitations associated with Edge computing.
Difference Between Cloud and Fog Computing
Below are some differences between cloud and fog computing.
|
Features |
Cloud Computing |
Fog Computing |
| Delay | High | Low |
| Latency | High | Low |
| Client-server Distance | Multiple hops | One hop |
| Service Location | Within the internet | At the edge of the local network |
| Real Time Interactions | Supported | Supported |
| Mobility Support | Low | Supported |
| Geo-distribution | Centralized | Distributed |
| Location Awareness | No | Yes |
Need of Fog Computing
Following are the needs pointed below:
- IoT applications generate a large amount of data. This data requires analysis to make decisions for implementation and to take various actions.
- Transferring this data to the cloud leads to a number of issues, for example, latency, excessive usage of bandwidth, delay in real-time responses, centralized location of data, etc.
- To overcome these challenges, faced by IoT applications, in the cloud environment, the term fog computing was introduced by Cisco in the year 2012.
- It promises to bring computation near to the end devices leading to minimization of latency and efficient usage of bandwidth.
- With the increase in sensor-based devices, a large amount of data is generated. This data needs storage as well as processing. Storing the data on the cloud is costly and adds to more processing time. It places resources near to the end devices, decreasing the processing time and saving the cost also.
Working
The working of this can be understood with a layered architecture:
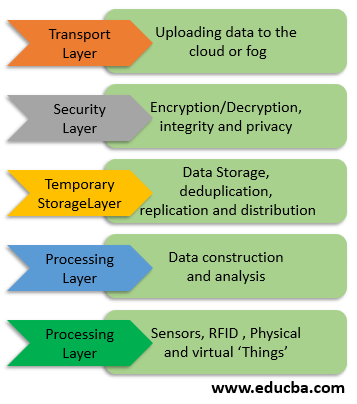
1. Physical and Virtualization Layer
In this layer, we have nodes- physical as well as virtual. Nodes are geographically distributed and capture data. Sensors are used in nodes to sense the surroundings, collect the data and send it to upper layers through gateways for more processing and filtering.
2. Monitoring Layer
In this layer, the various nodes are monitored which includes monitoring tasks performed by various nodes, the time at which the task is performed, and the next course of action. Application performance and status are also monitored. The energy usage of fog nodes is also taken into consideration for monitoring purposes.
3. Pre-Processing Layer
The pre-processing layer performs data analysis operations. The collected data is cleaned and unimportant data is filtered out. Data filtering in this layer may include removing all impurities from the data and making sure that only useful information is collected at this layer.
4. Temporary Storage Layer
This layer is associated with temporary data distribution and replication. The use of storage virtualization is made in this layer. A number of storage devices like NAS, FC, ISCSI, etc.
5. Security Layer
Security in fog computing involves privacy, integrity, encryption, and decryption of data. Privacy can be usage privacy, data privacy, and location privacy.
6. Transport Layer
This layer uploads pre-processed data to the cloud for permanent storage. The data is made to pass through various smart gateways for making sure that whatever has to be stored on the cloud is passed through the gateways.
Scope
The scope can be discussed under the following headings:
- Bandwidth-Aware Fog System Design: It is supposed to reduce bandwidth usage in the core network. The study of bandwidth in fog computing is in its initial stage. A number of experiments need to be carried out to find the proper usage of bandwidth in fog computing. The impact of adding innumerable devices to the fog architecture and the effect on fog bandwidth has to be considered.
- Fog System SLAs: Fog system, as of now, doesn’t have its own defined SLAs. All the current SLAs used for fog computing are actually meant for cloud computing. Fog architecture is distributed in nature, as compared to the central cloud model, comprising of devices form across different platforms. A potential and viable SLA is the need of the future, which will be specifically meant for the fog computing paradigm.
- Fog Scalability: The various algorithms and currently available schemes used in it aren’t matching with the scale of IoT devices. This acts as a hindrance for compatibility between fog and IoT devices.
- Green Fog Computing: There is a big need for improving the energy consumption of fog nodes. Currently, the use of energy harvesters for IoT devices and sensors has to be taken into consideration. Fueling of fog nodes by renewable energy sources like wind, sunlight should also be considered.
- Fog Resource Monitoring: As a fog node is used by a number of different users, located across multiple locations, monitoring becomes a challenge. Developing a fog-resource monitoring technique that supports multiple-operator usage is required in the future.
Advantages and Disadvantages of Fog Computing
Given below are the advantages and disadvantages mentioned:
Advantages:
- Low Latency: One of the important benefits of fog-computing is the nearness of resources. Data isn’t sent to far off servers for processing and analytics purposes. Data processing is done nearer to the devices, and thus latency is decreased to a larger extent.
- Better Security: Because of localized data processing, fog provides an advantage related to security. Same security policies as are implemented in any IT infrastructure can be implemented in a fog computing environment, and on a local basis.
- Reduced Operation Cost: Data is processed locally, saving network bandwidth, and infrastructure costs which add upsetting a big central cloud infrastructure.
- Scalability: This benefit allows devices to be added up rapidly in the fog environment. Devices can be scaled up on-demand basis.
- Flexibility: It allows multiple devices, from multiple platforms to be connected and share data without any hindrance.
Disadvantages:
- Authentication: With a large number of connected devices, authentication of devices is a major problem in fog computing. It becomes very difficult to identify a particular device in fog computing because of its distributed nature.
- Scheduling: As tasks are moved between fog devices, fog nodes, and cloud servers, so scheduling poses a problem.
- Power Consumption: Fog nodes use more power than centralized cloud architecture.
- Fog Servers: Fog servers have to be placed at appropriate places for maximum service.
Conclusion
It is a promise to remove the disadvantages which are currently faced by IoT data which is stored in data centers located far off. It places processing nodes between end-devices and cloud-data centers, removing the latency and improving efficiency.
Recommended Articles
This is a guide to Fog Computing. Here we also discuss the need and scope of fog computing along with its advantages and disadvantages. You may also have a look at the following articles to learn more –

