Updated March 21, 2023
Introduction to Dimension Table
A Dimension Table is present in the star or snowflake schema. Dimension tables’ help to describe dimensions i.e. dimension values, attributes and keys. It is generally small in size. Size can range from several to thousand rows. It describes the objects present in the fact table. Dimension Table refers to the collection or group of information related to any measurable event. They form a core for dimensional modelling. It contains a column that can be considered as a primary key column which helps to uniquely identify every dimension row or record. It is being joined with the fact tables through this key. When it is created a key called surrogate key that is system generated is used to uniquely identify the rows in the dimension.
Why do we need to use?
- Its help to store the history of the information or dimensional information.
- Its is easy to understand than the normalized tables.
- More columns can be added to the table without affecting the existing applications that are using those.
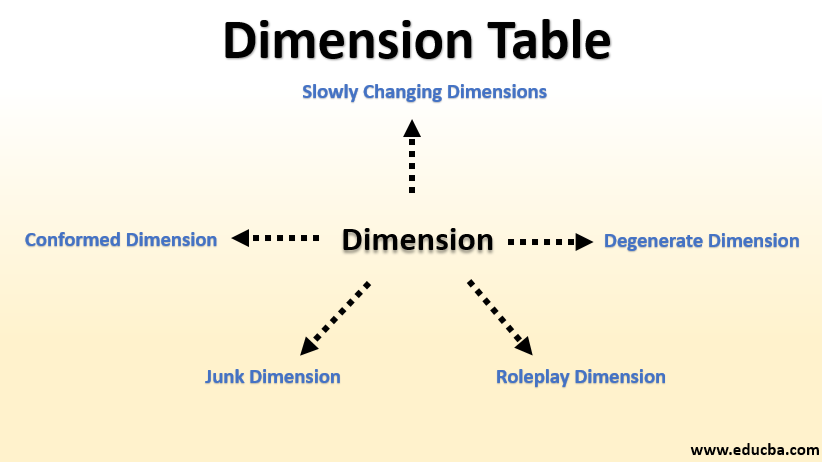
Types of Dimension Table
Following are the different types of Dimension Table:
1. SCD (Slowly Changing Dimensions)
The dimension attributes that tend to change slowly with time rather than changing in a regular interval of time are called slowly changing dimensions. For e.g. address and phone number changes but not regularly. Let us see an example of a man who travels to different countries so he needs to change his address according to that country. This can be done in three ways:
Type1: Overwrite the previous value. This method is easy to apply and helps to save space hence reduce cost. But, history is lost in this scenario.
The table before the change
| ID | NAME | COUNTRY | NATIONALITY |
| 1001 | Rachel | India | Indian |
Table after the change
| ID | NAME | COUNTRY | NATIONALITY |
| 1001 | Rachel | China | Indian |
Type2: Add a new row with the new value. In this method, the history is saved and can be used whenever necessary. But it takes large space hence increases the cost.
The table before the change
| ID | NAME | COUNTRY | NATIONALITY |
| 1001 | Rachel | India | Indian |
Table after the change
| ID | NAME | COUNTRY | NATIONALITY |
| 1001 | Rachel | India | Indian |
| 1001 | Rachel | China | Indian |
Type3: Add a new column. It is the best approach as history can be maintained easily.
The table before Change
| ID | NAME | COUNTRY | NATIONALITY |
| 1001 | Rachel | India | Indian |
Table after Change
| ID | NAME | COUNTRY | OLD COUNTRY | NATIONALITY |
| 1001 | Rachel | China | India | Indian |
2. Conformed Dimension
This dimension is shared among multiple subject areas or data marts. Same can be used in different projects without any modifications done in the same. This is used to maintain consistency. Conformed dimensions are those which are exactly same or a proper subset of any other dimension.
3. Junk Dimension
A junk dimension is a group of attributes of low cardinality. It contains different or various attributes which are unrelated to any other attribute. These can be used to implement RCD (rapidly changing dimension) such as flags, weights etc.
4. Degenerate Dimension
It attributes which are stored in the fact table itself and not as a separate dimension table, those attributes are called degenerate dimension. For e.g. ticket number, invoice number, transaction number etc.
5. Roleplay Dimension
The having multiple relationships with the fact table are called role-play dimension. In other words, it is when the same dimension key with all its related attributes is joined to many foreign key presents in the fact table. It can fulfil multiple purposes within the same existing database.
How does it work in the Data Warehouse?
- Dimension refers to the collection or group of information related to any measurable event. They form a core for dimensional modelling. When a dimension is created, a structure of a project is generated. Created can be used across different projects and it reflects the idea of reusability. When a change is made in any of it then its effect is reflected in that particular table only. When a report is to be created, the user can take the data from as dimension tables contain all the necessary information.
- When performing dimension modelling the atomic data is loaded into dimensional structures. Then the dimensional models are generated or build around the business processes. While creating it must be kept in mind to filter domain values and store labels of the reports in these tables. It must be ensured that surrogate key (System generated key used during the creation of dimension table which helps to uniquely identify each record present in the dimension table.) must be used while the dimension table is created. It must be denormalized because their task is to let the user read and analyze the data easily as efficiently rather than managing transactions. The main aim of dimension is to provide the filtering, perform grouping and efficient labelling.
Advantages
Below are the different advantages of the dimension table:
- It has a simple structure.
- It is easy to analyze and understand.
- Denormalized data.
- Helps to maintain historical information for any dimension.
- Easy to retrieve data from it.
- Fast to create and implement.
- It gives the context surrounding of any business process.
Conclusion- Dimension Table
This is an integral part of data modelling. It is used in star or snowflake schema. It contains the dimensions, keys and values of the attributes of the fact table. There are different types of which are used in different scenarios.
Recommended Articles
This is a guide to Dimension Table. Here we have discussed Types, How does Dimension Table work in the data warehouse with Advantages. You can also go through our other related articles to learn more-
