
Introduction to Decision Tree in Data Mining
In today’s world of “Big Data”, the term “Data Mining” means that we need to look into large datasets and perform “mining” on the data and bring out the important juice or essence of what the data wants to say. A very analogous situation is coal mining, where different tools are required to mine the coal buried deep beneath the ground. Of the tools in Data mining, “Decision Tree” is one of them. Thus, data mining in itself is a vast field wherein we will deep dive into the Decision Tree “tool” in Data Mining in the next few paragraphs.
Algorithm of Decision Tree in Data Mining
A decision tree is a supervised learning approach wherein we train the data present knowing the target variable. As the name suggests, this algorithm has a tree type of structure. Let us first look into the decision tree’s theoretical aspect and then look into the same graphical approach. In Decision Tree, the algorithm splits the dataset into subsets based on the most important or significant attribute. The most significant attribute is designated in the root node, and that is where the splitting takes the place of the entire dataset present in the root node. This splitting done is known as decision nodes. In case no more split is possible, that node is termed as a leaf node.
To stop the algorithm from reaching an overwhelming stage, a stop criterion is employed. One of the stop criteria is the minimum number of observations in the node before the split happens. While applying the decision tree in splitting the dataset, one must be careful that many nodes might have noisy data. To cater to an outlier or noisy data problems, we employ techniques known as Data Pruning. Data pruning is nothing but an algorithm to classify out data from the subset, making it difficult for learning from a given model.
The Decision Tree algorithm was released as ID3 (Iterative Dichotomiser) by machine researcher J. Ross Quinlan. Later C4.5 was released as the successor of ID3. Both ID3 and C4.5 are a greedy approach. Now let us look into a flowchart of the Decision Tree algorithm.
We would take “n” data points for our pseudocode understanding, each having “k” attributes. Below flowchart is made keeping in mind “Information Gain” as the condition for a split.
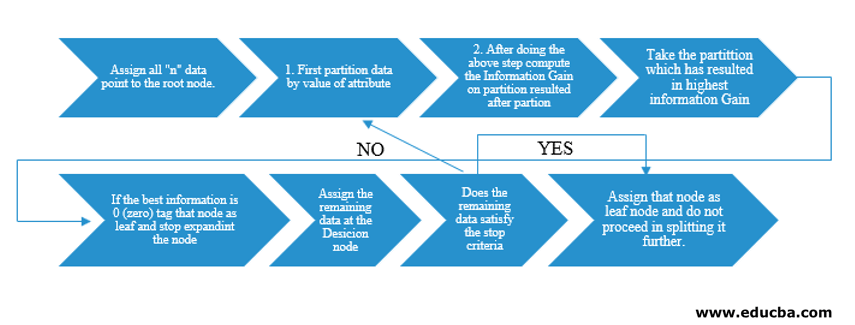
Instead of Information Gain (IG), we can also employ the Gini Index as split criteria. For understanding the difference between these two criteria in layman terms, we can think about this Information gain as Difference of Entropy before the split and after the split (split based on all features available).
Entropy is like randomness, and we would reach a point after the split to have the least randomness state. Hence, Information Gain needs to be the greatest on the feature we want to split. If we want to choose on dividing based on the Gini Index, we would find the Gini index for different attributes and use the same. We find out the weighted Gini Index for different split and use a higher Gini Index to split the dataset.
Important Terms of Decision Tree in Data Mining
Here are some of the important terms of a decision tree in data mining given below:
- Root Node: This is the first node where the splitting takes place.
- Leaf Node: This is the node after which there is no more branching.
- Decision Node: The node formed after splitting data from a previous node is known as a decision node.
- Branch: Subsection of a tree containing information about the aftermath of split at the decision node.
- Pruning: When removing a decision node’s sub-nodes to cater to an outlier or noisy data is called pruning. It is also thought to be the opposite of splitting.
Application of Decision Tree in Data Mining
Decision Tree has a flowchart kind of architecture in-built with the type of algorithm. It essentially has an “If X then Y else Z” pattern while the split is done. This type of pattern is used for understanding human intuition in the programmatic field. Hence, one can extensively use this in various categorization problems.
- This algorithm can be widely used in the field where the objective function is related to its analysis.
- When there are numerous courses of action available.
- Outlier analysis.
- Understanding the significant set of features for the entire dataset and “mine” the few features from a list of hundreds of features in big data.
- Selecting the best flight to travel to a destination.
- Decision-making process based on different circumstantial situations.
- Churn Analysis.
- Sentiment Analysis.
Advantages of Decision Tree
Here are some advantages of the decision tree explained below:
- Ease of Understanding: The way the decision tree is portrayed in its graphical forms makes it easy to understand for a person with a non-analytical background. Especially for people in leadership who want to look at which features are important, just a glance at the decision tree can bring out their hypothesis.
- Data Exploration: As discussed, obtaining significant variables is a core functionality of the decision tree and using the same; one can figure out during data exploration on deciding which variable would need special attention during the course of the data mining and modelling phase.
- There is very little human intervention during the data preparation stage, and as a result of that time consumed during data, cleaning is lessened.
- Decision Tree is capable of handling categorical as well as numerical variables and also cater to multi-class classification problems as well.
- As a part of the assumption, Decision trees have no assumption from a spatial distribution and classifier structure.
Conclusion
Finally, to conclude, Decision Trees bring in a whole different class of non-linearity and cater to solving problems on non-linearity. This algorithm is the best choice to mimic humans’ decision-level thinking and portray it in a mathematical-graphical form. It takes a top-down approach in determining results from new unseen data and follows the principle of divide and conquer.
Recommended Articles
This is a guide to Decision Tree in Data Mining. Here we discuss the algorithm, importance, and decision tree application in data mining and its advantages. You may also look at the following articles to learn more –

