Updated March 10, 2023

Introduction to Decision Tree Advantages and Disadvantages
Decision tree advantages and disadvantages depending on the problem in which we use a decision tree. A decision tree is defined as the graphical representation of the possible solutions to a problem on given conditions. A decision tree is the same as other trees structure in data structures like BST, binary tree and AVL tree. We can create a decision tree by hand or we can create it with a graphics program or some specialized software. In simple words, decision trees can be useful when there is a group discussion for focusing to make a decision.
Advantages and Disadvantages of Decision Tree
Given below are the advantages and disadvantages mentioned:
Advantages:
- It can be used for both classification and regression problems: Decision trees can be used to predict both continuous and discrete values i.e. they work well in both regression and classification tasks.
- As decision trees are simple hence they require less effort for understanding an algorithm.
- It can capture nonlinear relationships: They can be used to classify non-linearly separable data.
- An advantage of the decision tree algorithm is that it does not require any transformation of the features if we are dealing with non-linear data because decision trees do not take multiple weighted combinations into account simultaneously.
- They are very fast and efficient compared to KNN and other classification algorithms.
- Easy to understand, interpret, visualize.
- The data type of decision tree can handle any type of data whether it is numerical or categorical, or boolean.
- Normalization is not required in the Decision Tree.
- The decision tree is one of the machine learning algorithms where we don’t worry about its feature scaling. Another one is random forests. Those algorithms are scale-invariant.
- It gives us and a good idea about the relative importance of attributes.
- Useful in data exploration: A decision tree is one of the fastest way to identify the most significant variables and relations between two or more variables. Decision trees have better power by which we can create new variables/features for the result variable.
- Less data preparation needed: In the decision tree, there is no effect by the outsider or missing data in the node of the tree, that’s why the decision tree requires fewer data.
- Decision tree is non-parametric: Non-Parametric method is defined as the method in which there are no assumptions about the spatial distribution and the classifier structure.
Disadvantages:
- Concerning the decision tree split for numerical variables millions of records: The time complexity right for operating this operation is very huge keep on increasing as the number of records gets increased decision tree with to numerical variables takes a lot of time for training.
- Similarly, this happens in techniques like random forests, XGBoost.
- Decision tree for many features: Take more time for training-time complexity to increase as the input increases.
- Growing with the tree from the training set: Overfit pruning (pre, post), ensemble method random forest.
- Method of overfitting: If we discuss overfitting, it is one of the most difficult methods for decision tree models. The overfitting problem can be solved by setting constraints on the parameters model and pruning method.
- As you know, a decision tree generally needs overfitting of data. In the overfitting problem, there is a very high variance in output which leads to many errors in the final estimation and can show highly inaccuracy in the output. Achieve zero bias (overfitting), which leads to high variance.
- Reusability in decision trees: In a decision tree there are small variations in the data that might output in a complex different tree is generated. This is known as variance in the decision tree, which can be decreased by some methods like bagging and boosting.
- It can’t be used in big data: If the size of data is too big, then one single tree may grow a lot of nodes which might result in complexity and leads to overfitting.
- There is no guarantee to return the 100% efficient decision tree.
If you want to overcome the limitations of the decision tree, then you should use the random forest method, because it does not depend on a single tree. It creates a forest with multiple trees and takes the decision based on the number of majority of votes.
Decision Tree Regressor
The decision tree regressor is defined as the decision tree which works for the regression problem, where the ‘y’ is a continuous value. For, in that case, our criteria of choosing is impurity matric. In the classification, the impurity metric was based on Gini Index, Entropy-based, and classification error.
The purpose of using the impurity metric here is that because the probability factor is used in every aspect and that’s why you can calculate any value for the continuous value of ‘y’. So, the criteria of our choosing are MSE – Mean Scale Error. Mean Scale Error is the last decision or the leaf node of the decision tree. If four samples are remaining on which final output will be based, then the average of these four samples will be the value of ‘y’.
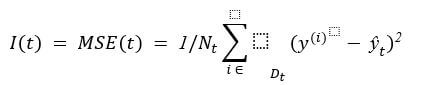
Here, N_t is the number of training examples at nodes t, D_tis the training subset at node t, y^((i))is the predicted target value (sample mean):
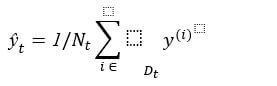
Conclusion
Decision trees have many advantages as well as disadvantages. But they have more advantages than disadvantages that’s why they are using in the industry in large amounts. Decision trees are more powerful than other approaches using in the same problems. The decision tree is very simple to represent and understand. Decision trees are so simple that they can understand even by non-technical people after a brief description. One needs to be careful with the size of the tree. It can be applied to any type of data, especially with categorical predictors. One can use decision trees to perform basic customer segmentation and build a different predictive model on the segments.
Recommended Articles
This is a guide to Decision Tree Advantages and Disadvantages. Here we discuss the introduction, advantages & disadvantages and decision tree regressor. You may also have a look at the following articles to learn more –
