Updated March 21, 2023
Introduction to Data Science Machine Learning
Data is basically information, especially facts or numbers, collected to be examined and considered and used to help decision-making or information in an electronic form that can be stored and used by a computer. Now, we will learn the definition of Data Science and Machine Learning.
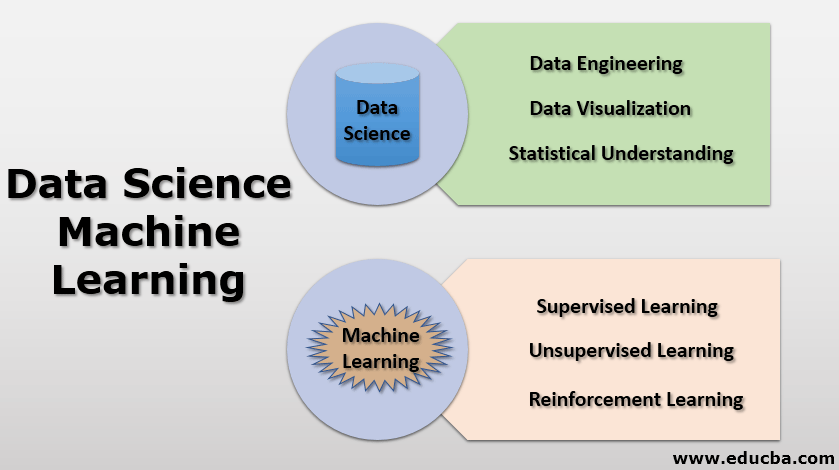
Data Science (DS): It is a vast field where different techniques like statistical methods, scientific approaches, architectural processes, variety of algorithms are used to extract insightful information from available data, which could be either structured data or unstructured data.
Machine Learning (ML): It is a subset of Data Science. With the help of statistical models and different algorithms, machines are trained in machine learning basics without giving explicit instructions; it relies on patterns created with data.”
Importance of Data Science
- We are living in an age of technology, where each person in some way or other uses technology for comfort/ effectiveness/ ease, e.g., cell phone/ Laptops / Tablets for communication, cars/trains/buses/aeroplanes for transportation, services like banking/electricity and many more for ease of life.
- At each such occasion, we are creating data knowingly or unknowingly like call logs/ texts / social media – images/ videos/ blogs all are part of data, with transportation our navigation to different locations by GPS/ performance of vehicle recorded through ECU is also part of data. Our banking and mobile wallets’ transactions create a huge amount of data; electricity consumption by any area or a sector is also a part of data.
- And to say this data is increasing exponentially day by day or minute by minute.
- Now the question that arises is, can we do something with this data? Can we use this data to provide some useful insights? Can we increase the effectiveness? Can we use this data to predict future outcomes?
- To answer all such questions, we have a field called data science.
- Data Science can be considered as a broad field that comprises data mining, data engineering, data visualization, data integration statistical methods, R/python/SQL programming, machine learning, Big data, and more.
Now let’s understand the important concepts of data science.
1. Data Engineering
Data engineering is one aspect of data science, which mainly focuses on data collection applications, data collection, and data analysis. All the work which data scientists do, like to answer several questions related to predictions or analysis, uses a large set of information.
Now what they need is right and useful information, which creates a need for collecting and validating the available information. These all are part of engineering tasks. Some of these tasks are checking for null values (Missing data), categorizing the data (categorical data), creating data structures (Association rules), etc.
2. Data Visualization
Data visualization is a graphical approach to represent the data. Here we use python’s inbuilt library to create visual elements, for example, tables, correlation charts, bar graphs, pair-plots, etc.; data visualization plays a vital role in providing a straightforward way to analyze the data, see and understand trends, figure out the outliers, etc.
3. Statistical Understanding
Statistics play a vital role in the field of data science. Statistics is a potent tool for performing the tasks of Data Science (DS). Statistics use mathematics to do technical analysis of available information. With visualizations like a bar or a chart, we can get the trend information, but statistics help us to operate on the data in a mathematical way/targeted way. Without knowledge of data, science visualization is just a game of guessing.
We will discuss some important statistical methods which data scientists daily use.
- Mean: Mean is basically an average of all data, calculated by adding all the data elements and dividing them by several elements. Used for identifying the centre value of all the elements.
- Median: Median is also used to find the centre value of elements available, but here all the data is arranged in an order, and the exact middle value is considered a median.
If number of elements are odd, then median is ((n + 1) / 2) th term. If a number of elements are even, then the median will be ((n / 2) + 1)th term.
- Mode: Mode is a statistical parameter that points out the most frequent or the value that appears the most number of times is treated as the mode.
- Standard Deviation: Standard deviation indicates how much spread is present in data, or it is a measurement to define spread from the mean values or average value or expected value.
If we have a low standard deviation, it indicates that most of the data values are near the average value. Our data values are more spread out from the mean value if we have a high standard deviation.
- Variance: variance is the same as standard deviation with a small difference; it is a standard deviation square. Standard deviation is derived from variance because Standard deviation shows spread in terms of data, while variance shows the spread with a square. It is easy to correlate spread using a variance.
- Correlation: Correlation is one of the most important statistical measures; it indicates how the data set variables are related. When we change one parameter, how it affects the other parameter.
If we have a positive correlation value which means the variables will either increase or decrease in parallel
If we have a negative correlation value, which means the variables will behave inversely on an increment, one other will decrease and vice versa.
In statistics, we have a probability distribution, Bayesian statistics, and hypothesis testing, which are also essential tools for a data scientist.
Machine Learning
Machine Learning basically means a way by which machines can learn and produce output based on input features.
Definition: “Machine learning is a Field of study where the computer learns from available data/historical data without being explicitly programmed.”
In Machine learning, the focus is on automating and improving computers’ learning processes based on their input data experiences. We won’t program the code explicitly for each type of problem, i.e. machine will figure out how to approach the problem. Here results may not be accurate, but a good prediction can be made.
Let’s understand it this way:
Traditionally computers are used to ease the process of computation, so if we have any arithmetic calculation. What will we do? We will prepare one computer program which will solve that operation in an easy and fast manner. e.g., if we want to add two entities, we will create one piece of software code, which will take two inputs, and in the output, it will show summation.
The machine learning approach is different; instead of feeding a direct algorithm, a special algorithm is put into software code that will try to recognize a pattern and, based on those patterns, will try to predict the best possible output. Here we are not coding any algorithm explicitly for any specific operation; instead, we are feeding data to a machine to learn the pattern and the output.
Why do we need to go for this approach when we can directly get the exact results by coding the exact algorithm? The Exact Algorithms are complex and are limited. Let’s see it from a different perspective; this is an era where we have an abundance of data, and it is exploding every day, as we have discussed in the previous section. Here we deal with Supervised and Unsupervised learning.
Machine learning is of acute interest nowadays because we are having an abundance of data. To make sense of this data, we need to have some meaningful outcomes or meaningful patterns, which can be analyzed and put into real use.
But still, why are we interested in Machine learning and this data?
We know that humanity replays history like we are the same as our previous generations were. Our descendants are also going to face several same situations we are facing now or have faced. At this stage, we must imagine how to react to the future using historical data.
So now we know that data is a precious asset.
The Challenge is How Best Can we Utilize This Available Data?
This is the most interesting topic (How?), where we will make sense of available data. There are basically 3 approaches for machine learning:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
These three approaches are used for creating a machine learning model (Linear regression, logistic regression, random forest, decision trees, etc.).
There is a wide variety of applications of these machine learning models, for example:
- Finance: fraud detection
- Marketing/ Sales: personalize the recommendation
- Healthcare: identify the trend of the disease.
Conclusion
- Data Science is a broad field in which machine learning is a subset. In this, we analyze the historical data available to us, and we try to predict the most likely future outcomes.
- To predict, we need to clean the data, arrange the data (data engineering). With data in hand, we visualize the pattern/trends, and then, with statistical understanding, we infer insightful information.
- This data will be fed to a machine using a Machine learning algorithm.
- These algorithms train the machine and create one machine learning model.
- This model then can be used for prediction.
Recommended Articles
This is a guide to Data Science Machine Learning. Here we discuss the importance of data science along with machine learning. You may also look at the following articles to learn more –
