Updated March 22, 2023

Introduction to Data Model in Cassandra
Apache Cassandra has become one of the most powerful NoSQL databases. It is the right choice when you want high availability and scalability without compromising performance, especially for applications that can’t afford to lose data. In this topic, we are going to learn about the Data Model in Cassandra.
A quick fact, Cassandra engineers, are among the top paid tech professionals today. Companies like Netflix, Instagram, and Apple use Cassandra to provide a highly individualized customer experience. However, you need to carefully design the schema specific to the business problem to get the right performance. This article will look at the Cassandra Data Model, which is significantly different from what we see in RDBMS.
Cassandra Data Model Rules
In simple words, a Data model is the logical structure of a database. It describes how data is stored and accessed and the relationships among different types of data. Picking the right data model can be the hardest part of using a NoSQL Database like Cassandra. As I mentioned earlier, data modelling in Cassandra is different from what we see in an RDBMS. Partition key and Clustering key are the terms that anyone dealing with Cassandra should be aware of. Before we dive into the basic rules of data modelling in Cassandra, let us quickly look at what these terms mean,
Partition
Cassandra is a distributed database in which data is partitioned and stored across different nodes in a cluster. The data is portioned by using a partition key- which can be one or more data fields. This partition key is used to create a hashing mechanism to spread data uniformly across all the nodes.
Cluster
A cluster is a collection of nodes that represent a single logical database. A clustering key is made up of one or more fields that are used to group data together in a partition.
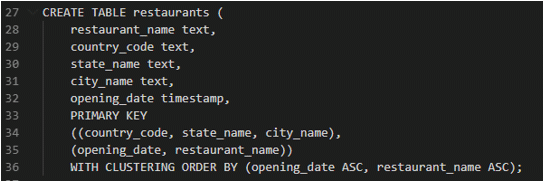
In this table restaurants, data will be partitioned using country_code, state_name and city_name, and within that partition data will be clustered and sorted based on opening_data and restaurant_name.
Now, let us look at the two rules for data modelling that should be kept in mind.
- Data is distributed evenly throughout the cluster
- Read from as fewer partitions as possible
Let’s look at what these rules are trying to convey
- We know what a cluster is right? A cluster consists of multiple nodes. We want to partition the data among these nodes such that each node has roughly the same amount of data. As we know data is partitioned into different nodes using a hash of the partition key (which is the first key of the Primary Key), so in short- “You should choose a good Primary Key”.
- Each partition resides on a different node, so when you retrieve data, you want to make sure that the data is retrieved from as fewer partitions as possible. If your query requires data from different partitions, a command will be issued to separate nodes to get you that data, which will be overhead and lead to latency.
The key to an efficient data model would be a balance between these two rules.
Handle Relationships in Cassandra
One thing to keep in mind is data modelling in Cassandra is done using Query driven approach unlike in RDBMS where you first identify entities, create tables then form queries using JOINS to retrieve data.
To put it in simple words, we don’t model around relations or objects, we model around queries.
1. One to One Relationship
Consider in a university a student can register for only one seminar. This is a one to one relationship. Keeping #1 rule we think of the queries we want. I want to search for the seminar a student is attending. In this case, we will make just one table. The table should contain the student details and the seminar details.
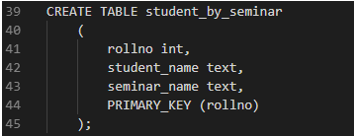
2. One to Many Relationship
In the same context, what if I wanted to search for all the students attending a seminar. Instead of using the same table and iterating over each row to get the student name for that particular seminar, I can make another table which partitions the data by seminar name. So when I issue the query, it only hits one node rather than going to all nodes to get the seminar name.
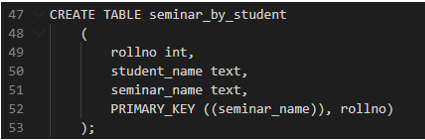
3. Many to Many Relationship
Now, let’s consider, a student can attend many seminars, and a seminar can be attended by many students. Here we have a many to many relationships. In this case, you can exploit the above two tables to make queries without having an overhead of making complex queries using Joins which you would typically do in RDBMS.
Importance of Cassandra
With the rapid expansion of digital data, it becomes more important to have a highly scalable, fault-tolerant database in place. Let me list out a few points on why you should use Cassandra
- Lighting fast read operations: We discussed how modelling your data the correct way can optimize read operations by massive scale.
- Fault-tolerant: Data is replicated across nodes so even if one node goes down your data is safe.
- Custom tuning: You can setup Cassandra to work according to your workload. If you write a lot of data, like logging, you can tweak it to handle write-heavy systems. There are several other tuning options available.
- Dealing with high data volumes: Based on the cluster size, Cassandra can deal with the huge volumes of data.
How to model the data in Cassandra?
A good data modeling follows these steps
- Conceptualize the queries required by your application
- Creating tables to satisfy those queries
Before we apply these rules, one thing to keep in mind is, “We focus on optimizing our read operations even if it requires data duplication”. We can have many tables that may contain almost similar data.
Now, consider we want a database that stores information on restaurants. Let us put a constraint that restaurant names have to be unique.
The table below can be used when we want to lookup based on the restaurant name:
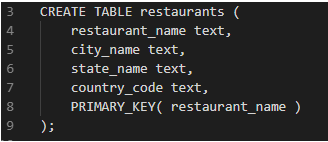
Now if we want to look up the restaurants for a particular location, we would write a query that iterates through all the rows and retrieves restaurant names.
Instead, keeping in mind #2 rule, we can easily create another table that will serve our need.
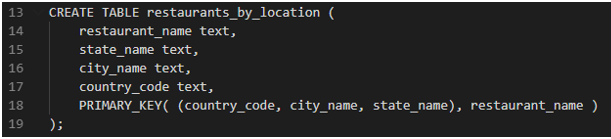
Now our data will be partitioned in a way that a node in the cluster will have restaurants for a particular location. This will optimize our read queries, as query lookup will only happen on one node with much lesser rows than the first table we created.
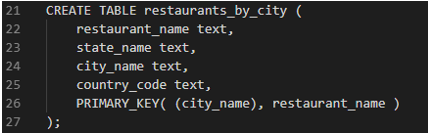
What if we wanted to search restaurants in a particular city we can make another table rather than iterating through all the rows in a single partition of the above table.
Conclusion
In this article, I have covered a few best practices you can follow one how to approach data modelling in Cassandra. If you understand these concepts and can efficiently recognize the kind of queries your application needs, you can design a great data model to get high performance out of your database.
Recommended Articles
This is a guide to Data Model in Cassandra. Here we discuss how to model our data in Cassandra along with the rules and Importance of Cassandra Data Models. You can also go through our other suggested articles to learn more –

