Updated March 24, 2023

Introduction to Data Mining Cluster Analysis
Data Mining Clustering analysis is used to group the data points having similar features in one group, i.e. the data is partition into the set of groups by finding the similarity in the objects in the useful groups by different available methods (such as Density-based Method, Grid-based method, Model-based method, Constraint-based method Partition based method, and Hierarchical method). This feature is widely used in research for recognizing patterns, image processing, and data analysis.
What is Cluster Analysis?
As discussed above, the intent behind clustering. It is a methodology in which, in Machine Learning and Artificial Intelligence, abstract objects are converted into classes containing similar types of objects. For example, in a shop having a customer database, we can cluster customers into groups and target selling products based on what likes and dislikes exist in that group. Or maybe in streaming, we can group people in different clusters and recommend movies based on what taste a person has based on which cluster they fall.
In cluster analysis, we try to first partition the set of data into groups by finding the similarity in the objects in the group and then, if required, assign a label to it. The main advantage of clustering is that it tries to single out useful features in the dataset and uses them to distinguish different groups. Due to this reason, it is adaptable to changes as well. In a cluster analysis, we would like to keep in mind distinctions between sets of clusters to apply the meaning of cluster analysis in data mining fully.
- Exclusive vs non-exclusive: In an exclusive cluster, we would have data points in a particular cluster only, whereas in non-exclusive, the data point can belong to two or more clusters simultaneously.
- Fuzzy vs Non-Fuzzy: In a Fuzzy level of clustering, the data points belong to all clusters with a weight between 0 to 1, and all the weight should add up to 1. This is also known as probabilistic clustering. In a non-fuzzy, it is the opposite, where a data point belongs to one particular cluster.
- Partial vs Complete: During partial, we would like to cluster only a part of data for various business reasons.
- Heterogeneous vs Homogeneous: In heterogeneous, the cluster size, shape and densities may vary, but inhomogeneous, it is made sure that the cluster is of the same shape, size, and density.
Methods of Data Mining Cluster Analysis
In data mining, there are a lot of methods through which clustering is done. They are:
1. Partitioning Method
As the name suggests, the entire data set is partitioned into ‘k’ partitions. Once the partition is done, the methodology to improve partition by iterative relocation technique is implemented to fulfil 2 main requirements:
- One data point should be in only one cluster.
- Each group or partition will contain at least one object.
An example of an iterative relocation technique is K-means, where “k” is the number of clusters and arbitrary k centres are chosen and then optimized to get ‘k’ centres. The type of distance metric used is the least.
2. Hierarchical Method
For hierarchical clustering, let us look at how it is done; following that, it will be easier to understand the same intent. When data is taken, the distance of data points is calculated automatically and formulated into a matrix form. Now, once the matrix is calculated, two steps are performed consecutively, the clusters close to each other are identified and then clubbed together. Each step of clubbing became a split node and performed until all are clubbed together. Below a schematic representation using the dendrogram makes it easier to understand.
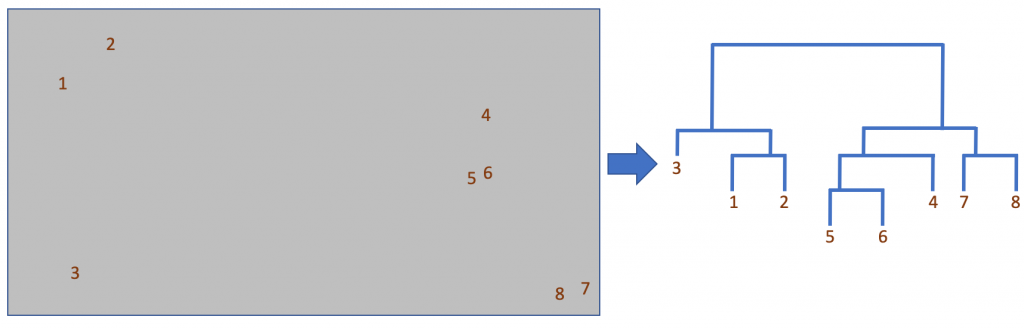
3. Density-based Method
As the name suggests, the intent behind this algorithm is density. Here the cluster is grown till the point density in a neighbourhood exceeds a threshold.
4. Grid-based Method
The main difference in this type of method is that the data points don’t play a major role in clustering but the value space of surrounding data. In a grid-based method, we face various advantages out of which the below mentioned two plays the major role.
- Fast processing time.
- Only the number of cells in the respective dimension are taken for evaluation.
5. Model-based Method
Here and the name suggests, a model is identified that best fits the data, and the clusters are located by clustering of the density function.
6. Constraint-based Method
In this method, the user is prompted for constraint as an interactive way of identifying the clusters and making desired clusters.
Application of Mining Cluster Analysis
In today’s world, cluster analysis has a wide variety of applications starting from as small as segmentation of objects, objects that may be people or things in a shop, to segmentation of reviews straight from the text of how the reviews’ sentiments are.
Below are the main applications of cluster analysis, though not an exhaustive list.
- Cluster analysis is widely used to recognise patterns or image processing or exploratory data analysis.
- Clustering analysis can be used to identify similar geographical land and analyse for better crop production or evaluated for investments.
- One can use clustering for grouping documents in a web search.
- Financial institutes are using clustering analysis extensively in fraud detection using cluster alongside outlier detection.
- In exploratory data analysis, data scientist uses clustering to derive fundamentals in the data distribution.
- In the retail segment, one uses the cluster to segment customers to target different products.
Conclusion
To conclude, there are different requirements one should keep in mind while clustering is performed. These vary from scalability, where one needs to perform analysis on how well these algorithms can be scaled for large databases. Also, one should keep in mind how well higher dimensional data is managed in clustering algorithms. Finally, the clustering algorithm is a potent tool and as we all say, with great power comes great responsibility. Thus points should be kept in mind while performing clustering in large datasets.
Recommended Articles
This is a guide to Data Mining Cluster Analysis. Here we discuss what data mining cluster analysis, along with its methods and application, is. You can also go through our other suggested articles to learn more –

