Updated April 27, 2023
Difference Between Apache Spark vs Apache Flink
Apache Spark is an open-source cluster computing framework developed by Apache Software. Apache Spark is very fast and can be used for large-scale data processing. It is an alternative to existing large-scale data processing tools in the area of big data technologies. Apache Flink is an open-source framework for stream processing data streaming applications for high availability, performance, stability, and accuracy in distributed applications. Apache Flink provides low latency and high throughput in the streaming engine with fault tolerance for data engine or machine failure.
Let us study much more about Apache Spark and Apache Flink in detail:
- The University of California Berkeley originally developed Spark as a cluster computing framework, which was later donated to the Apache Software Foundation and made open source.
- The Apache Software Foundation developed Apache Flink as an open-source software framework, with its core component being a distributed streaming and data processing engine written in Java and Scala.
- Apache Spark is very fast and can be used for large-scale data processing, which is evolving considerably nowadays. It has become an alternative to many existing large-scale data processing tools in the area of big data technologies.
- Apache Spark can run programs 100 times faster than Map Reduce jobs in the Hadoop environment, making this preferable. Spark can also be run on Hadoop or Amazon AWS cloud by creating Amazon EC2 (Elastic Cloud Compute) instance or standalone cluster mode and can also access different databases such as Cassandra, Amazon Dynamo DB, etc.,
Head-to-Head Comparison Between Apache Spark vs Apache Flink (Infographics)
Below are the Top 8 Comparison between Apache Spark vs Apache Flink
Key Differences Between Apache Spark vs Apache Flink
Below are the key differences Between Apache Spark vs Apache Flink:
- Spark is a set of Application Programming Interfaces (APIs) out of all the existing Hadoop-related projects, more than 30. The creators of Stratosphere, a research project, changed its name to Flink, which later became Apache Flink.
- Spark provides high-level APIs in programming languages like Java, Python, Scala, and R. The Apache Projects Group accepted Apache Flink as an Apache Incubator Project in 2014.
- Spark has core features such as Spark Core, Spark SQL, MLib (Machine Library), GraphX (for Graph processing), and Spark Streaming. Flink is used for performing cyclic and iterative processes by iterating collections.
- Apache Spark and Apache Flink are general-purpose streaming or data processing platforms in the big data environment. Spark cluster mode can stream and process the data on different clusters for large-scale data to process fast and parallel.
- Spark Cluster mode will have applications running as individual processes in the cluster. Flink is a vital and high-performing tool for batch processing jobs and scheduling processes.
- The components of the Spark cluster are Driver Manager, Driver Program, and Worker Nodes. Flink has another feature of suitable compatibility mode to support different Apache projects such as Apache storm and Map, reducing jobs on its execution engine to improve the data streaming performance.
- Spark has different types of cluster managers available such as HADOOP Yarn cluster manager, standalone mode (already discussed above), Apache Mesos (a general cluster manager), and Kubernetes (experimental, which is an open-source system for automation deployment). Flink has only a data processing engine compared to Spark, which has different core components.
- Spark cluster component functions have Tasks, Cache, and Executors inside a worker node, whereas a cluster manager can have multiple worker nodes. Flink architecture works so that the streams need not be opened and closed every time.
- Spark and Flink have in-memory management. Spark crashes the node when it runs out of memory but has fault tolerance. Flink has a different approach to memory management. Flink writes to disk when the in-memory runs out.
- Apache Spark and Apache Flink work with the Apache Kafka project developed by LinkedIn, which is also a robust data streaming application with high fault tolerance.
- Spark can share memory within different applications residing in it, whereas Flink has explicit memory management that prevents the occasional spikes present in Apache Spark.
- Spark has more configuration properties, whereas Flink has fewer configuration properties.
- Flink can approximate batch processing techniques. At the same time, Spark provides a unified engine that can connect to many cluster managers, storage platforms, and servers and can be run independently on top of Hadoop.
- When triggered, Apache Spark experiences less network usage at the beginning of a job, which can cause a delay in the job’s execution. Apache Flink uses the network from the start, effectively using its resource.
- Less resource utilization in Apache Spark causes less productivity, whereas in Apache Flunk, resource utilization is effective, rendering it more productive with better results.
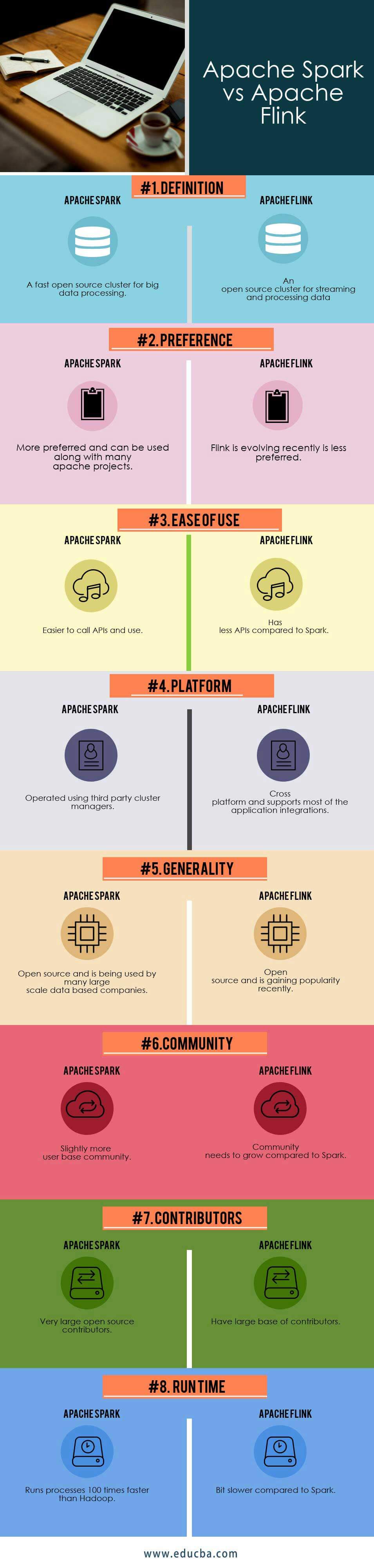
Apache Spark vs Apache Flink Comparision Table
Below is the top comparison between Apache Spark vs Apache Flink:
| Basis of Comparison | Apache Spark | Apache Flink |
| Definition | A fast open-source cluster for big data processing. | An open-source cluster for streaming and processing data. |
| Preference | More preferred and can be used along with many Apache projects. | Flink has been evolving recently and is less preferred. |
| Ease of use | Easier to call APIs and use. | It has fewer APIs compared to Spark. |
| Platform | It is operated using third-party cluster managers. | Cross-platform and supports most of the application integrations. |
| Generality | Many large-scale data-based companies are using Spark, which is an open-source technology. | Open source has been gaining popularity recently. |
| Community | Slightly more user base community. | The community needs to grow compared to Spark. |
| Contributors | Huge open-source contributors. | Have a large base of contributors. |
| Run Time | Runs process 100 times faster than Hadoop. | A bit slower compared to Spark. |
Conclusion
Developers design Flink and Spark applications for general-purpose data stream processing, but they differentiate in their APIs, architecture, and core components. Spark has multiple core components for different application requirements, whereas Flink has only data streaming and processing capacity. Depending on the business requirements, the software framework can be chosen. Spark has existed for a few years, whereas Flink is evolving gradually nowadays in the industry, and there are chances that Apache Flink will overtake Apache Spark. Companies prefer Spark over Flink to support multiple applications in a distributed environment due to its ability to integrate with various frameworks.
Recommended Articles
This has been a guide to Apache Spark vs Apache Flink. Here we have discussed Apache Spark vs Apache Flink head-to-head comparison, key differences, and a comparison table. You may also look at the following articles to learn more –
