Updated March 16, 2023
Difference Between Apache hive vs Apache hbase
The following article provides an outline for Apache hive vs Apache hbase. Apache Hive is a software used for data warehousing built over Apache Hadoop, providing data analysis and query. Apache Hive provides an interface like SQL for querying the data stored in different databases and file systems integrated with Big Data Hadoop. For executing SQL applications and querying over a distributed area, the sql queries must be implemented in MapReduce Java. On the other hand, Apache HBase is a non-relational database also open-source, modeled explicitly after Google’s Bigtable is written in Java. Apache Hbase was built under Apache Software Foundation’s Apache Hadoop project. It runs on Hadoop Distributed File System or Alluxio, which provides capabilities like Bigtable for Hadoop.
Head-to-Head Comparison Between Apache hive vs Apache hbase (Infographics)
Below are the top differences between Apache hive vs Apache hbase
Key Differences between Apache hive vs Apache hbase
Both Apache Hive and Apache Hbase are highly popular in the market. However, they have some significant differences, which are discussed below:
- Apache Hive is a data warehousing system that is built over Hadoop. It is used for querying large pools of unstructured data on Hadoop, data analysis, and data summarization. Through Apache Hive, we can also query data stored in Apache Hadoop distributed file system or from the data stored in Spark, Apache Hbase, or Map-reduce. On the other hand, Apache Hbase runs over the Alluxio or Hadoop distributed file system; moreover, it is a NoSQL value/ key store. The operations in Hbase run in real-time on the database instead of Map-reduce jobs, which is not in the case of Apache Hive. So, from Apache Hbase, we get additional random access capabilities that are not available in Hadoop distributed file system as Hadoop distributed file system is not made for real-time data analytics and random write/ read operations. So, HBase adds many features to Hadoop distributed file system’s functionalities. Apache Hbase can also be used as a data storage for data processed in real-time through Hadoop.
- In Apache Hive, the language used for querying batch Map-reduce jobs is just like SQL and is called HiveQL or HQL. ACID transactions, including INSERT/ IMAGE/ DELETE/ UPDATE statements, are supported in Apache Hive. Some additional features and functionalities have been updated in Apache Hive version 3.0, reducing the table schema constraints. Moreover, vectorized queries can also be accessed now. On the other hand, Apache Hbase can also be integrated into Map-reduce. SQL functions can be gained in Apache Hbase by integrating Apache Hive and Map-reduce.
- Apache Hive is very suitable for SQL professionals in querying data from different data storage integrated with Hadoop. Apache Hive is compliant with JDBC; it can be easily integrated with tools based on SQL. Hive queries are time-taking as they go through the complete data in the table by default. However, Apache Hive has a partitioning feature limiting the total amount of data. On the other hand, the partitioning feature of Apache Hbase enables the user to deploy a filter on the stored data within the different folders and reads the data which matches.
- Moreover, Apache Hbase includes tables, and tables can be further distributed into column families. The column families declared in the schema include a specific set of columns, and the columns have no requirement to follow the schema definition. For example, the “details” column family can contain columns such as: “Name,” “Contact Number,” “Date of Birth,” “Address,” “Fax,” “Company,” “Designation,” and “Course Enrolled.” Every value/critical pair in Apache Hbase is called a cell, and every key contains a row-key, column, column family, and time stamp. A row is Apache Hbase is represented as value/ key groups mapping, which is identified as row-key. Apache Hbase uses Hadoop’s scales and infrastructure horizontally.
- Apache Hive can be summarized as a system that provides SQL-like features to Hadoop/ Spark. Working on the Java API of Map Reduce isn’t easy. This system can work like a data warehousing system and an ETL tool, including high-class integrations and different user-friendly features. Moreover, Apache Hive can also handle technically different other functions, just like Apache Pig. For example, If we have to use Map-reduce, we don’t have to write a lengthy code; instead, we can use SQL over Apache Hive. Using Apache Hive can be uniquely different for every user according to the specific requirements. Whereas, We can summarize Apache Hbase as a system that can store data and process Hadoop data along with real-time write/ read requirements. Both types of data, i.e., structured and unstructured data, can be included. However, Hbase is very much suitable for unstructured data. Apache Hbase operates in low latency and is accessible using shell commands, REST, Java APIs, or Thrift. In Hadoop clusters, Hbase is represented as a storage layer, and big companies like Adobe uses Apache Hbase for every storage need of Hadoop.
Comparison Table between Apache hive vs Apache hbase
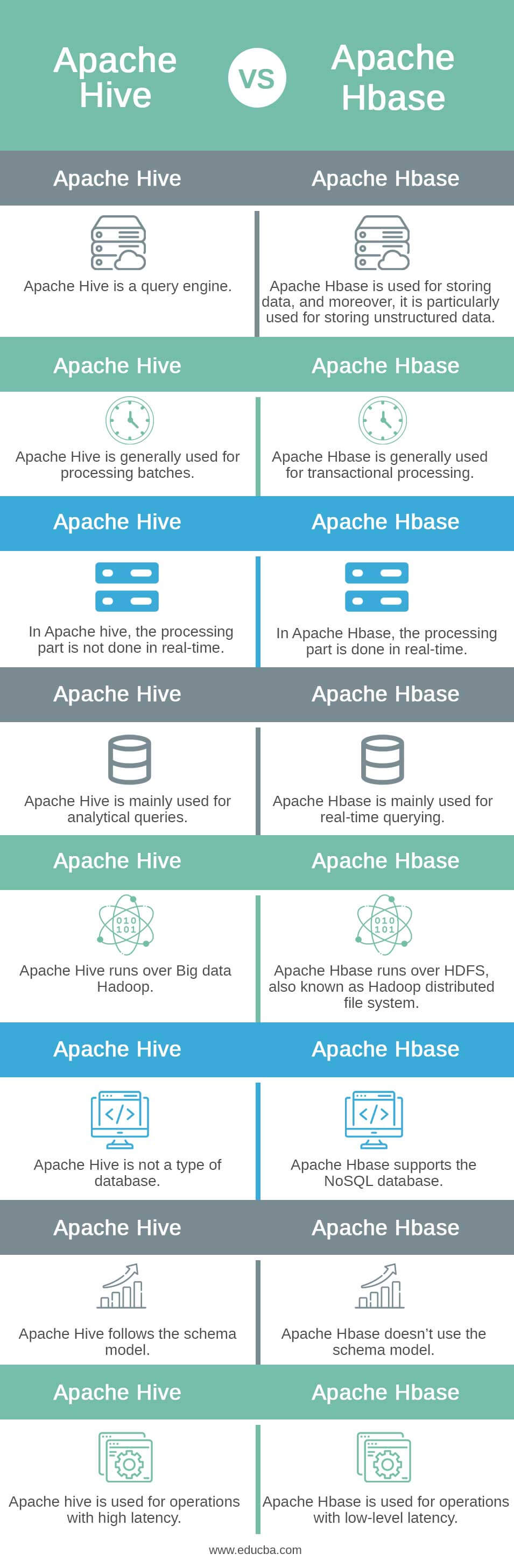
Below is the comparison table between Apache hive vs Apache hbase:
| Apache Hive | Apache Hbase |
| Apache Hive is a query engine | Apache Hbase is used for storing data, and it is mainly used for storing unstructured data. |
| Apache Hive is generally used for processing batches. | Apache Hbase is generally used for transactional processing. |
| In Apache hive, the processing part is not done in real-time. | In Apache Hbase, the processing part is done in real-time. |
| Apache Hive is mainly used for analytical queries. | Apache Hbase is mainly used for real-time querying. |
| Apache Hive runs over Big data Hadoop | Apache Hbase runs over HDFS, also known as Hadoop distributed file system. |
| Apache Hive is not a type of database | Apache Hbase supports the NoSQL database. |
| Apache Hive follows the schema model | Apache Hbase doesn’t use the schema model |
| Apache hive is used for operations with high latency | Apache Hbase is used for operations with low-level latency |
Conclusion
Based on the above article, we understood Apache Hive and Apache Hbase. We went through the basics of Apache Hive and Apache Hbase. Moreover, the different differentiating features of Apache Hive and Apache Hbase are explored in detail. This article will help beginners understand the differences between Apache Hive and Apache Hbase.
Recommended Articles
This is a guide to Apache hive vs Apache hbase. Here we discuss the Apache hive vs Apache hbase key differences with infographics and a comparison table. You may also have a look at the following articles to learn more –
