Updated May 18, 2023

Difference Between Hadoop vs Spark
Hadoop is an open-source framework that allows storing and processing of big data in a distributed environment across clusters of computers. Hadoop is designed to scale from a single server to thousands of machines, where every machine offers local computation and storage. Spark is an open-source cluster computing designed for fast computation. It provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. The main feature of Spark is in-memory cluster computing, increasing an application’s speed.
Hadoop
- Hadoop is a registered trademark of the Apache software foundation. It utilizes a simple programming model to perform the required operation among clusters. All modules in Hadoop are designed with a fundamental assumption that hardware failures are common occurrences and should be dealt with by the framework.
- The application runs the MapReduce algorithm, which processes data in parallel on different CPU nodes. In other words, the Hadoop framework can develop applications capable of running on clusters of computers, and they can perform a complete statistical analysis for a vast amount of data.
- The core of Hadoop consists of a storage part known as Hadoop Distributed File System and a processing part called the MapReduce programming model. Hadoop splits files into large blocks and distributes them across the clusters, transferring package code into nodes to process data in parallel.
- This approach dataset to be processed faster and more efficiently. Other Hadoop modules are standard, with many Java libraries and utilities returned by Hadoop modules. These libraries provide a file system and operating system level abstraction and also contain required Java files and scripts to start Hadoop. Hadoop Yarn is also a job scheduling and cluster resource management module.
Spark
- Spark was built on top of the Hadoop MapReduce module and extended the MapReduce model to efficiently use more computations, including Interactive Queries and Stream Processing. Spark was introduced by the Apache software foundation to speed up the Hadoop computational computing software process.
- Spark has its cluster management and is not a modified version of Hadoop. Spark utilizes Hadoop in two ways – one is storage, and the second is processing. Since cluster management is arriving from Spark, it uses Hadoop for storage purposes only.
- Spark is one of Hadoop’s subprojects developed in 2009, and later it became open source under a BSD license. It has lots of wonderful features, by modifying specific modules and incorporating new modules. It helps run an application in a Hadoop cluster multiple times faster in memory.
- This is possible by reducing the number of read/write operations to disk. It stores the intermediate processing data in memory, saving read/write operations. Spark also provides built-in APIs in Java, Python, or Scala. Thus, one can write applications in multiple ways. Spark provides a Map and Reduce strategy and supports SQL queries, Streaming data, Machine learning, and Graph Algorithms.
Head-to-Head Comparison Between Hadoop vs Spark (Infographics)
Below is the top 8 difference between Hadoop and Spark:
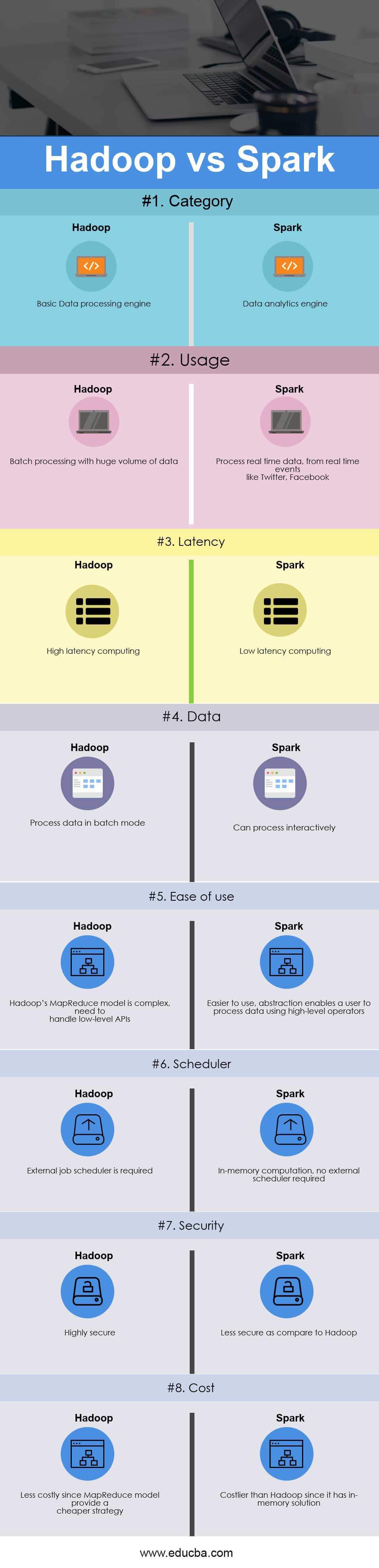
Key Differences between Hadoop and Spark
Both Hadoop vs Spark are popular choices in the market; let us discuss some of the significant differences between Hadoop and Spark:
- Hadoop is an open-source framework that uses a MapReduce algorithm. In contrast, Spark is a lightning-fast cluster computing technology that extends the MapReduce model to efficiently use more types of computations.
- Hadoop’s MapReduce model reads and writes from a disk, thus slowing down the processing speed. In contrast, Spark reduces the number of read/write cycles to disk and stores intermediate data in memory, hence faster-processing speed.
- Hadoop requires developers to hand code every operation, whereas Spark is easy to program with RDD – Resilient Distributed Dataset.
- The Hadoop MapReduce model provides a batch engine, hence dependent on different engines for other requirements, whereas Spark performs batch, interactive, Machine Learning, and Streaming all in the same cluster.
- Hadoop efficiently handles batch processing, while Spark excels in handling real-time data.
- Hadoop is a high latency computing framework, which does not have an interactive mode, whereas Spark is a low latency computing and can process data interactively.
- With Hadoop MapReduce, a developer can only process data in batch mode, whereas Spark can process real-time data through Spark Streaming.
- Hadoop is designed to handle faults and failures; it is naturally resilient toward faults, hence a highly fault-tolerant system, whereas, with Spark, RDD allows recovery of partitions on failed nodes.
- Hadoop needs an external job scheduler, for example – Oozie, to schedule complex flows, whereas Spark has in-memory computation, so it has its flow scheduler.
- Hadoop is a cheaper option compared to cost, whereas Spark requires a lot of RAM to run in-memory, thus increasing the cluster and hence cost.
Hadoop and Spark Comparison Table
The primary Comparison between Hadoop and Spark are discussed below
| Basis Of Comparison Between Hadoop vs Spark |
Hadoop |
Spark |
| Category | Basic Data processing engine | Data analytics engine |
| Usage | Batch processing with a huge volume of data | Process real-time data from real-time events like Twitter, Facebook |
| Latency | High latency computing | Low latency computing |
| Data | Process data in batch mode | Can process interactively |
| Ease of Use | Hadoop’s MapReduce model is complex and needs to handle low-level APIs | Easier to use, abstraction enables a user to process data using high-level operators |
| Scheduler | An external job scheduler is required | In-memory computation, no external scheduler is required |
| Security | Highly secure | Less secure as compare to Hadoop |
| Cost | Less costly since the MapReduce model provide a cheaper strategy | Costlier than Hadoop since it has an in-memory solution |
Conclusion
Hadoop MapReduce allows parallel processing of massive amounts of data. It breaks a large chunk into smaller pieces to process them separately on different data nodes. It automatically gathers the results from multiple nodes and returns a single result. If the resulting dataset is larger than the available RAM, Hadoop MapReduce may outperform Spark.
On the other hand, Spark is easier to use than Hadoop, as it comes with user-friendly APIs for Scala (its native language), Java, Python, and Spark SQL. Since Spark provides a way to perform streaming, batch processing, and machine learning in the same cluster, users find it easy to simplify their infrastructure for data processing.
The final decision between Hadoop vs Spark depends on the basic parameter – requirement. Apache Spark is a much more advanced cluster computing engine than Hadoop’s MapReduce since it can handle any need, i.e., batch, interactive, iterative, streaming, etc. At the same time, Hadoop limits to batch processing only. At the same time, Spark is costlier than Hadoop with its in-memory feature, which eventually requires a lot of RAM. It all depends on a business’s budget and functional requirements. I hope now you have a fairer idea of both Hadoop and Spark.
Recommended Articles
This has been a guide to the top difference between Hadoop vs Spark. Here we also discuss head-to-head comparison, key differences, infographics, and comparison tables. You may also look at the following Hadoop vs Spark articles to learn more.
