What is Site Reliability Engineering?
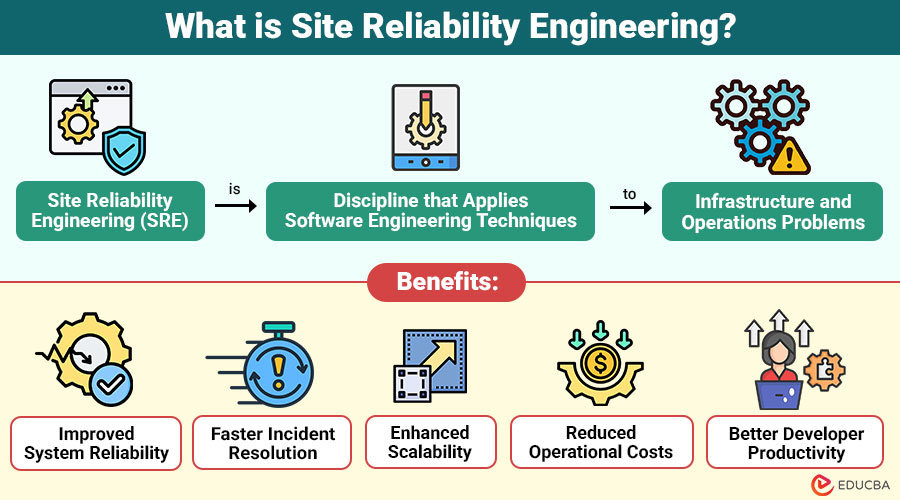
Site Reliability Engineering (SRE) is discipline that applies software engineering techniques to infrastructure and operations problems. Its primary goal is to build scalable and highly reliable software systems.
In simple terms, SRE ensures that systems are available, performant, and resilient, while also minimizing manual operational work through automation.
Table of Contents:
- Meaning
- Key Objectives
- Core Principles
- Key Components
- Tools
- Benefits
- Challenges
- Real-World Example
- Best Practices
Key Takeaways:
- Site Reliability Engineering combines software engineering and operations to build scalable, reliable, and automated systems efficiently.
- It uses SLOs, SLIs, and error budgets to balance reliability with continuous innovation efforts.
- Automation and observability reduce manual work, improve performance, and enable faster incident resolution times.
- SRE adoption enhances scalability, reduces downtime, optimizes costs, and improves overall user experience significantly
Key Objectives of Site Reliability Engineering
SRE focuses on balancing innovation and reliability. Its key objectives include:
1. System Reliability
Ensuring consistent uptime, minimizing outages, maintaining service availability, and quickly resolving failures to deliver a dependable user experience.
2. Automation
Automating repetitive operational tasks using scripts and tools to reduce manual effort, errors, and improve overall system efficiency.
3. Scalability
Designing systems capable of handling increasing workloads, users, and data growth without compromising performance, stability, or responsiveness.
4. Efficiency
Optimizing resource utilization, improving system performance, and reducing operational costs while maintaining high service quality and reliability standards.
5. Risk Management
Identifying potential failures, implementing safeguards, and managing risks effectively without slowing development speed or innovation initiatives.
Core Principles of Site Reliability Engineering
Here are the core principles that form the foundation of effective site reliability engineering practices:
1. Service Level Objectives
Define target reliability levels, such as uptime percentage, guiding teams to balance performance, availability, and user expectations.
2. Service Level Indicators
Quantifiable metrics like latency, error rates, and availability are used to measure and evaluate actual system performance.
3. Error Budgets
Represent allowable failure limits, enabling teams to innovate while ensuring reliability by restricting releases when thresholds are exceeded.
4. Automation Over Manual Work
Focuses on automating repetitive operational tasks, reducing human error, improving efficiency, and enabling faster, more consistent system management.
5. Monitoring and Observability
Continuous monitoring and observability tools provide insights into system health, helping detect issues early and understand behavior effectively.
Key Components of Site Reliability Engineering
Here are the essential components that ensure reliability, scalability, and efficient system operations:
1. Monitoring and Alerting
Track system metrics continuously and trigger alerts when thresholds are exceeded using tools like Prometheus and Grafana.
2. Incident Management
Respond to outages using structured processes, ensuring rapid recovery, clear communication, and minimal impact on users and services.
3. Capacity Planning
Forecast future demand and ensure infrastructure scales efficiently to handle increased workloads without affecting performance or reliability.
4. Change Management
Implement safe deployment practices like canary releases and gradual rollouts to minimize risks and maintain system stability.
5. Postmortems
Analyze incidents thoroughly to identify root causes, document learnings, and implement improvements to prevent future system failures.
Tools Used in Site Reliability Engineering
SRE relies on a variety of tools to manage systems efficiently:
1. Monitoring Tools
Nagios and Datadog help track system performance, detect anomalies, and trigger alerts for proactive issue resolution.
2. Containerization
Docker enables packaging applications with dependencies, ensuring consistent environments across development, testing, and production systems.
3. Orchestration
Kubernetes enhances dependability and operational efficiency at scale by automating the deployment, scaling, and management of containerized applications.
4. CI/CD Tools
Jenkins supports continuous integration and delivery by automating build, testing, and deployment pipelines efficiently
5. Cloud Platforms
Amazon Web Services and Microsoft Azure provide scalable infrastructure, storage, and services essential for modern SRE practices.
Benefits of Site Reliability Engineering
Here are the major benefits of adopting Site Reliability Engineering in modern organizations:
1. Improved System Reliability
Ensures high availability, consistent performance, reduced failures, and dependable user experience across varying workloads and operating conditions.
2. Faster Incident Resolution
Structured incident response processes enable quick detection, efficient troubleshooting, and rapid recovery, minimizing downtime and service disruptions
3. Enhanced Scalability
Systems are built to scale seamlessly, handling increasing user demand, traffic, and data growth without compromising stability or performance
4. Reduced Operational Costs
Automation of repetitive tasks reduces manual effort, lowers operational expenses, and improves overall efficiency in managing complex infrastructure
5. Better Developer Productivity
Developers focus on innovation and feature development while SRE practices ensure system reliability, stability, and smooth operational support
Challenges in Implementing Site Reliability Engineering
While SRE offers many advantages, organizations may face challenges such as:
1. Cultural Resistance
Shifting from traditional operations to SRE requires organizational mindset changes, collaboration, and acceptance of shared responsibility for reliability
2. Skill Gap
SRE demands professionals skilled in both development and operations, making hiring and training experienced talent a significant challenge
3. Initial Investment
Implementing monitoring, automation, and infrastructure tools requires upfront financial investment, which may be high for smaller organizations initially
4. Complex Systems
Managing large-scale distributed systems introduces complexity, requiring advanced tools, coordination, and expertise to maintain reliability and performance.
Real-World Example
Here is a practical example illustrating how Site Reliability Engineering improves system performance and reliability:
A large e-commerce company experiences frequent downtime during peak sales events. By adopting SRE practices:
- They define SLOs for uptime and latency
- Implement monitoring tools for real-time alerts
- Use automation for scaling infrastructure during high traffic
As a result, the company reduces downtime, improves customer experience, and increases revenue.
Best Practices for Site Reliability Engineering
To successfully implement SRE, organizations should follow these best practices:
1. Define Clear SLOs and SLIs
Establish measurable reliability targets and performance indicators to guide teams in maintaining service quality and meeting user expectations.
2. Automate Repetitive Tasks
Automate routine operational tasks to reduce manual effort, minimize errors, and improve efficiency, consistency, and system reliability.
3. Adopt a Blameless Culture
Encourage open incident analysis without blame, focusing on learning, accountability, and continuous improvement across teams and processes.
4. Continuously Monitor Systems
Implement continuous monitoring to track performance, detect anomalies early, and ensure proactive issue resolution and system stability.
5. Invest in Observability Tools
Use advanced observability tools to gain deep insights into system behavior, enabling faster troubleshooting and informed decision-making.
6. Balance Reliability and Innovation
Maintain a balance between system reliability and innovation by managing risks while allowing continuous development and feature releases.
Final Thoughts
Site reliability engineering is powerful approach that bridges the gap between development and operations. By focusing on reliability, automation, and scalability, SRE enables organizations to deliver high-quality services while maintaining system stability. Adopting SRE techniques is now necessary for long-term success as companies continue to rely on digital infrastructure.
Frequently Asked Questions (FAQs)
Q1. What skills are required for SRE?
Answer: Skills include programming, system administration, cloud computing, and monitoring tools.
Q2. Which companies use SRE?
Answer: Major tech companies like Google, Netflix, and Amazon widely use SRE practices.
Q3. What programming languages are useful for SRE?
Answer: Common languages include Python, Go, Java, and Bash scripting, which help automate tasks, manage infrastructure, and build scalable systems efficiently.
Q4. How does SRE improve system performance?
Answer: SRE improves performance through continuous monitoring, automation, efficient resource utilization, and proactive issue detection, ensuring systems run smoothly under varying workloads.
Recommended Articles
We hope that this EDUCBA information on “Site Reliability Engineering” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
