
Introduction to XPath Relative
XPath is used to find a respective node on an XML Document. Relative XPath is defined as a type of XPath used to search an element node anywhere that exist on the web page. It is specified by the double forward slash notation (//) which starts from the middle of the DOM Structure and it is not necessary to add a long XPath. No need to start from the root node could start with the node that we have selected and relative path can have children as well. And This Relative Path is preferred due to no direct access from the root node.
Syntax
The general format used to search an element is given below:
// tagname[@ attribute=’value’]
Here
- // is the current node element
- Tag: is the element node like < p> , <div > etc.
- @: It denotes an attribute.s
- // *[@class= ‘value ‘]
So, in the next section, we shall learn what is XPath and what are the different ways to use a relative path to find the hidden elements.
How does Relative path work in XPath?
Relative XPath is much easier to work on compared with the absolute path. This path starts by just referencing the element that we need to reach to which is automatically meant for testing an element. In other words, we can say that the required object on the web page is marked by the exact Path. The evaluation part always starts from the context node which can be changed with an XPath Query. Before we move into the concept it is good to know the differences between the single slash and double slash. Relative Path helps in avoid giving the Exception ‘Element Not Found Exception’.
- Single Slash (‘/ ‘) looks for the element which is a root.
- Double slash (“//”) looks for any element in the code, for example, it may be a child or grand-child inside the root element.
The relative path can take different forms never mind about the ancestor’s elements. The relative path requires less time to navigate the node and could be used with XPath Axes to make the expression good. And here comes some of the axes which are used n relative path expression to make efficient a path. They are:
- Simple XPath: This simple Path Starts with // followed by tag name.
- Text (): It checks with the text content matches.
- Contains (): To find the specific element containing the text we use this function.
- Following, siblings, Ancestors, descendants.
One of the Disadvantages of Relative Path is that it takes too long time while searching since only the partial path is specified rather than an exact location. Next, it is very slow compared with CSS and their implementations vary on the browsers.
The advantage is they have good efficiency as they find an accurate location path.
Examples to Implement XPath Relative
Now let us start exploring in the examples with the relative XPath – which are short and consistent
Example #1
Using Simple XML file where we get to have an element related to Cosmetics.
cosmetic.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE cosmeticstore [
<!ELEMENT cosmeticstore (cosmetics+)>
<!ELEMENT cosmetics (CName, type+, category*, country?, mfd?, expdate?, price)>
<!ATTLIST cosmetics prodcode CDATA #REQUIRED>
<!ELEMENT CName (#PCDATA)>
<!ELEMENT type (#PCDATA)>
<!ELEMENT category (#PCDATA)>
<!ELEMENT country (#PCDATA)>
<!ELEMENT mfd (#PCDATA)>
<!ELEMENT expdate (#PCDATA)>
<!ELEMENT price (#PCDATA)>
]>
<cosmeticstore>
<cosmetics prodcode="GO305">
<CName>Face</CName>
<type>Foundation</type>
<category>Women</category>
<mfd>USA</mfd>
<expdate>2021</expdate>
<price>12.69</price>
</cosmetics>
<cosmetics prodcode="HG767">
<CName>Lips Treatement</CName>
<type>Lip Contour and Liner</type>
<category>Women</category>
<mfd>Germany</mfd>
<expdate> 2022 </expdate>
<price>29.99</price>
</cosmetics>
<cosmetics prodcode="KJ879">
<CName> Face Wash</CName>
<type>All</type>
<type> Men Brand </type>
<category> White Anti-Agent</category>
<category>Garnier</category>
<country>London</country>
<mfd>France</mfd>
<expdate>2023</expdate>
<price>60.19</price>
</cosmetics>
</cosmeticstore>
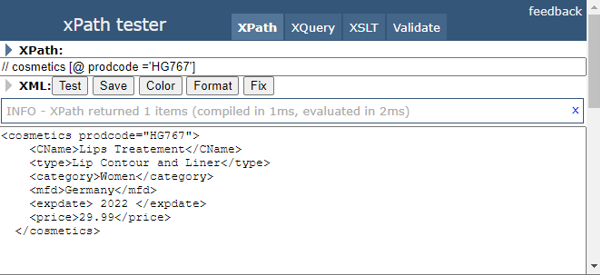
The Xpath Relative location for the above XML code is given as :
// cosmetics [@ prodcode ='HG767']
Here Not every element is accessed. I’m pointing into the root nodes child which is ‘cosmetics’ with the attribute prod code (directing to second child node). The relative Path is accessing the middle of the element in the code. And the resulting output is given below:
Output:
Example #2 – With Html Elements
Relative Path access to the class here.
main.html
<html>
<head>
<title>Button-Click Demo</title>
</head>
<body>
<div id="header" class="main">
<div id="logo">
<img src="bullets blue.gif" alt="My logo">
</div>
<div id="main" class="head">
<h1>Welcome To Home Shopping</h1>
<div id="text">
<p>Hello World</p>
<div id="first bt">
<button type="button" onclick="alert('Triggering the button')">Press Me</button>
</div>
</div>
<div id="Select Option">
<select>
<option value="ch1" selected>Choose 1</option>
<option value="ch2">Choose 2</option>
<option value="ch3">Choose 3</option>
</select>
</div>
<div id="getInput">
<input id="InputId" type="text" placeholder="Test input">
</div>
</div>
<div id="foot" class="foot-main">
<end>Copyright @</end>
</div>
</body>
</html>
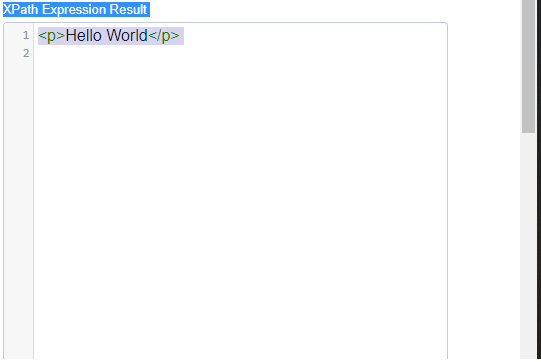
So for this location path – the relative path focus on the element class ‘head’ which has a header <h1> with the text ‘hello world’ is displayed.
//*[@class='head']//*[text()='Hello World']
For the Xpath Expression with Relative Path the Resulting Output is given below:
Output:
Example #3 – With Xml Style Sheet
cargopk.xsl
<?xml version = "1.0" encoding = "UTF-8"?>
<xsl:stylesheet version = "1.0">
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
<xsl:template match = "/">
<html>
<body>
<h3>Cargo Company Invoice.</h3>
<table border = "1">
<tr bgcolor = "purple">
<th>no </th>
<th>Cname </th>
<th>address</th>
<th>Vyoage </th>
<th>Npack </th>
</tr>
<xsl:for-each select = "//company/invoice/no">
<tr>
<td><xsl:value-of select = "@no"/> </td>
<td><xsl:value-of select = "Cname"/> </td>
<td><xsl:value-of select = "address"/> </td>
<td><xsl:value-of select = "Vyoage"/> </td>
<td><xsl:value-of select = "Npack "/> </td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
cargo.xml
<?xml version = "1.0"?>
<?xml-stylesheet type = "text/xsl" href = "cargopk.xsl"?>
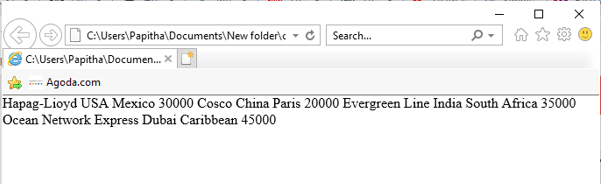
<company>
<invoice no = "B762">
<Cname>Hapag-Lioyd</Cname>
<address>USA</address>
<Vyoage>Mexico</Vyoage>
<Npack>30000</Npack>
</invoice>
<invoice no = "K564">
<Cname>Cosco</Cname>
<address>China</address>
<Vyoage>Paris</Vyoage>
<Npack>20000</Npack>
</invoice>
<invoice no = "F583">
<Cname>Evergreen Line</Cname>
<address>India</address>
<Vyoage>South Africa</Vyoage>
<Npack>35000</Npack>
</invoice>
<invoice no = "Z124">
<Cname>Ocean Network Express</Cname>
<address>Dubai</address>
<Vyoage>Caribbean</Vyoage>
<Npack>45000</Npack>
</invoice>
</company>
Output:
Conclusion
XPath is a powerful Selector element and has many different operators and attributes methods to work with Web elements. To have an effective and good option it is advisable to rely on the pre-generated path rather than the browsers. This Relative Path is much easier to assign like //element [id = ‘…’], The web developer should be much consistent in assigning the location path for their website to perfectly automate the control flow when there is an updating in the code.
Recommended Articles
This is a guide to XPath Relative. Here we discuss an introduction to XPath Relative, how does it work with examples to implement. You can also go through our other related articles to learn more –
