Updated March 24, 2023

Overview of Logstash
Logstash is an open-source tool that is used for the real-time pipeline for the data injection between two different independent resources. Earlier it was used only for log collection but now it is used beyond that. Any data type can be injected through the logstash and transformed through the array of input, filter, and output plugins along with other code plugins which helps to transform the input data to required format types. Log management and event management both are made using a tool called Logstash.
It is an open-source event processing engine that can manipulate data to destination with numerous plugins. It is an event-based tool developed by the Elasticsearch Company. It is a part of the ELK stack. Plugin receive, manipulate, or ship data to the destination resource.
Logstash Configuration File Format
Pipeline = input + (filter) + Output
Logstash is not limited to processing only logs. It can handle XML, JSON, CSV, etc. alike easily. It has a very strong synergy with Elasticsearch and Kibana+ beats.
- Pipeline: Pipeline is the collection of different stages as input, output, and filter. The input data enters into the pipeline and processed as an event and at last send to the new stage which may be a filter or last output stage.
- Event: When any input data enters the pipeline, we call it an event.
- Input: The input means the data entering into the pipeline. This is the first stage of the pipeline.
- Filter: Filter is the next stage of the pipeline. In this stage, we can add more fields to the data or can change the data (manipulation stage) before sending it to the output stage.
- Output: This is the last stage of the pipeline. In this, the coming data will be formatted according to the requirements of the destination source.
Architecture of Logstach
Logstash is based on the decouple-architecture i.e. it is centralized event processing. Decouple architecture means two independently systems interact with each other without being directly connected to each other.
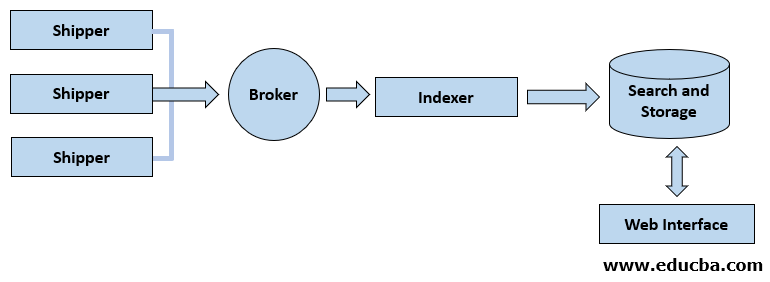
Logstash Design and Architecture
In this ecosystem view, our three components are:
- Shipper: It sends all data from the source to logstash.
- Broker and Indexer: This component will receive and formulate data for indexer events.
- Search and Storage: Allows to search and store events.
How does Logstash Work?
The working of Logstash is simple. It is used to define the source via a naïve forwarder. The set of rules is implemented for data formatting. The rules are used to forward data to the destination. The input, output keys, and filters are used for data processing. The data ingestion of all the size, source, shapes are made using input plugins. The transform and parse of information on the fly using filters. The output plugin is used to select the stash and export the information. Logstash is available as an open-source and is implemented as a server-side for pipeline processing that injects the data from multiple sources at the same time, and is used for transformation and sends to the favorite column of stash. Here stash represents the repository of data. It is implemented along with Elasticsearch in the NoSQL database. It is highly scalable.
If the user has a CSV file and uses command Logstash in the CSV file and all columns and datatypes. Now the Logstash understand the rules and filter the files to consider only the important requirements of CSV. Then CSV file parsing is made by Logstash to fetch the data. The configuration of stash makes the database to access it easier. Now the Logstash becomes familiar to add the data and collects it to the stash.
The working of Logstash is amazing in streaming the data. when the user executes the Logstash as a job, it persistently monitors the input source of the user and implies the accurate rule for formatting and push the collected information into the user preferred stash. The events are pushed through every phase in the interior queues and enable varied input for the user logs. The log can be parsed and filtered according to the user’s choice. It enables the centralized service for processing the data and analyses the huge variety of unstructured and structured events and data. Logstash provides many plugins to link with different kinds of input platforms and sources.
The event object is the main object in Logstash that encapsulates the flow of data in the pipeline of Logstash. It enables the object to save the input data and fetches the extra fields developed at filter stages. It provides event API to aggravate the events and logs. The pipeline comprises the flow data from input to output in Logstash. The input data is fed into the pipeline and operates as an event. Then it transfers to output destination in the end system according to the preferred format.
Input is the initial stage of the pipeline, used to fetch the data and process it further. It provides a lot of plugins to get information from varied platforms. Few plugins are Redis, Beats, Syslog, and file. The filter is located at the medium part of Logstash and processes the actual events. The developer applies pre-described Regex patterns to build sequences to segregate the event field in events only for requested input events. It is used to describe the structure to use plugin filters like Drop, Mutate, Clone, and Grok.
The output is the final stage of the pipeline and the output events can be edited according to the structure as needed by destination services. It transfers the output event once the process is completed by using destination plugins and most of the output plugins are File, Graphite, ElasticSearch.
Getting Logstash:
To install logstash, we need java installed in a given system. Even it is mentioned in JRuby, its developer given all dependencies in a tarbale so now logstash is easy to install.
Downloading Logstash:
$ wget https://artifacts.elastic.co/downloads/logstash/logstash-7.5.1.tar.gz
After download tarball, unzip it in your required directory.
Standby Logstash:
$ cd logstash-7.5.1
$logstash-7.5.1/
Inside of that logatsh directory create a dir called conf and save all future configuration files in that directory. Configuration file sample is given below:
input {
stdin{}
}
output{
stdout{}
}
Running the Logstash Agent:
After creating a configuration file, to run logstash we use the following commands:
$ cd logstash-7.5.1
$ bin/logstash -f path/of/the/conf/file/dir
If you change something in the configuration file then every time you have to restart the configuration file so that it can pick up the new and updated configuration.
How to Install Plugin?
To install different kinds of plugin input/output which are available use the following command:
$ bin/logstash_plugin install /name-of-the-plugin-name/
Example:
$ bin/logstash_plugin install logstash-input-beats
Scaling Logstash:
One of the great things about Logstash is that it is made up of easy to fit together components: Logstash itself, Redis as a broker, Elasticsearch and the various other pluggable elements of your Logstash configuration. One of the advantages of this method is the ease with which you can scale it and those components.
- Redis: Which we’re using as a broker for incoming events.
- Elasticsearch: Handling search and storage.
- Logstash: Which is consuming and indexing the events.
This is a fairly basic introduction to scaling these components with a focus on trying to achieve some simple objectives:
- To make Logstash as redundant as possible with no single points of failure.
- To avoid messages being lost in transit from inputs and outputs.
- To make it perform in the most efficient way.
Our final scaled architecture will look like this:
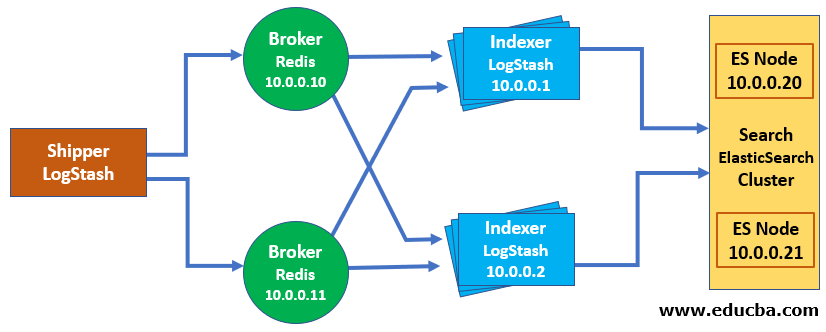
Logstash Scaled Architecture
Scaling Redis
In our implementation, we’re using Redis as a broker between our Logstash agents and the Logstash central server. One of the reasons we chose Redis is that it is very simple. Thankfully, making Redis redundant is also simple. This can send events to and receive events from multiple Redis instances in a failover configuration. It’s important to note that this is a failover rather than true high availability. Events are not round robined or load-balanced between Redis instances. It will try to connect to a Redis instance and send events.
If the sending succeeds then it will continue to send events to that Redis instance. If the send fails, Logstash will pick the next Redis instance and try to send it to the next instance instead of the failed one. This does, however, provide you with some basic redundancy for your broker through the deployment of additional Redis instances but has a limited impact if your Redis instance is a performance bottleneck for your environment. If this is an issue for you then you can designate Redis instances for specific agents or groups of agents with additional Redis instances defined if you’d like redundancy.

Logstash Redis failover
Benefits of Logstash
- With the help of logstash, we can connect two different independent sources together. It can send data with very high speed from one source to another source and also help to parse data in different formats before ingesting to the destination.
- It also helps to filter log data and supports different kinds of databases, protocols. It works as a central point which makes it easy to process and collect data from different sources.
- It provides the sequences of the Regex pattern to find various fields and parse it according to the input event.
- It supports different web pages and web servers from data sources to extract the logged data. It can make parsing and transform from the logging data into the user format. It is easy to process and gather data from multiple servers.
- It supports network protocols, multiple databases, other services as the main source of destination from the logging event. The HTTP protocol is used by Logstash and allows the user to upgrade the versions of Elasticsearch. Instead of upgrading, it can be lockstep also.
Conclusion
Logstash helps in transferring data from one source to another source. Logstash has fully optimized itself but using scale features, We can do more logstash control for the data pipeline. Hence, it is an important tool to collect, parse, filter, forward, and process the data. Logstash can manage multiple HTTP requests and data responses. It offers multiple filters to make it more important in data transformation and parsing of data. It is used to manage the sensors and data in the internet of things. It is accessible in the Apache license of version 2.
Recommended Articles
This is a guide to What is Logstash? Here we discuss the overview and configuration file format of logstash along with architecture, working and its benefits. You may also look at the following articles to learn more-
