Introduction
In NLP and modern AI systems, machines cannot process raw text directly, so language must be converted into numerical form. Tokenization and embeddings enable this transformation. Tokenization breaks text into smaller units, whereas embeddings represent those units numerically, capturing their meaning and context. Understanding tokenization vs embeddings is essential for building effective language models, chatbots, search engines, and recommendation systems. This article provides a detailed comparison of tokenization and embeddings, explaining how they work, where they differ, and how they are used in real-world applications.
Table of Contents:
- Introduction
- What is Tokenization?
- What are Embeddings?
- Key Differences
- Examples
- Use Cases
- Advantages and Disadvantages
- Which One Do You Need?
What is Tokenization?
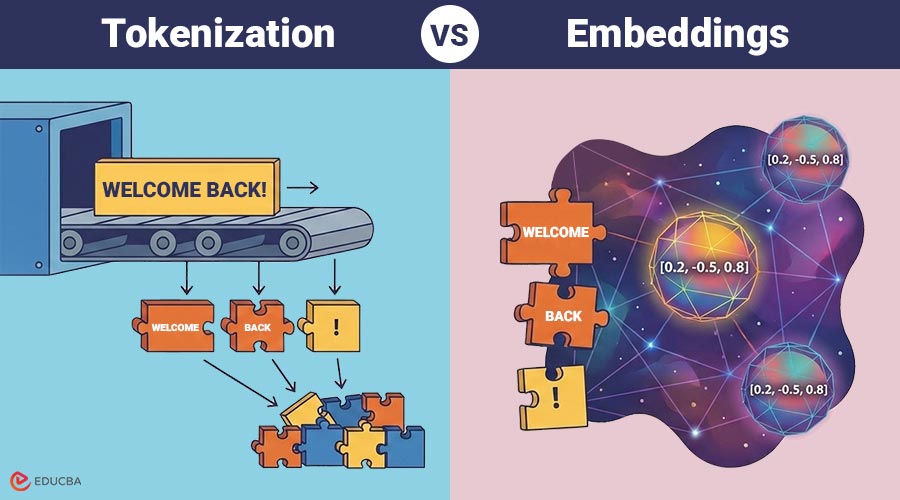
Tokenization is process of breaking raw text into smaller units called tokens. These tokens can be words, subwords, characters, or symbols, depending on the chosen tokenization method.
Purpose:
- Standardize text input
- Handle punctuation and special characters
- Reduce complexity for downstream processing
- Convert text into manageable pieces for models
What are Embeddings?
Embeddings are numerical vector representations of tokens that capture semantic meaning, context, and relationships between words or phrases. Each token is mapped to a dense real-valued vector. Tokens with similar meanings tend to have vectors that are close together in the embedding space.
Purpose:
- Understand semantic similarity
- Capture context and relationships
- Perform mathematical operations on language
- Power tasks like search, classification, clustering, and recommendations
Tokenization vs Embeddings: Key Differences
Here is a concise comparison of tokenization and embeddings across key aspects:
| Aspect | Tokenization | Embeddings |
| Purpose | Split text into units | Represent meaning numerically |
| Output | Tokens (text or IDs) | Numerical vectors |
| Captures meaning | No | Yes |
| Captures context | No | Yes |
| Position in pipeline | First step | After tokenization |
| Human-readable | Yes | No |
| Dimensionality | Low or none | High (e.g., 300, 768, 1024) |
Examples of Tokenization and Embeddings
Here are examples illustrating tokenization and embeddings in action:
1. Tokenization
Text: “AI improves productivity”
Tokens: [“AI”, “improves”, “productivity”]
2. Embeddings
Each token is converted into a vector:
- “AI” → [0.12, -0.45, 0.89, …]
- “improves” → [0.67, 0.21, -0.33, …]
- “productivity” → [0.91, -0.11, 0.44, …]
These vectors allow the model to compute similarity, relationships, and predictions.
Use Cases of Tokenization and Embeddings
Here are some common use cases of tokenization and embeddings:
Use Cases of Tokenization:
- Text Preprocessing: Tokenization breaks text into smaller units, making it easier for machines to process accurately.
- Language Translation: Tokenization separates sentences and words, enabling translation models to understand linguistic structures correctly.
- Sentiment Analysis: Tokenization converts text into tokens, enabling sentiment models to analyze opinions and emotions more effectively.
- Chatbots: Tokenization enables chatbots to parse user input into tokens for generating relevant responses.
Use Cases of Embeddings:
- Semantic Search: Embeddings represent text as numeric vectors, enabling search engines to efficiently retrieve contextually similar results.
- Question Answering Systems: Embeddings enable models to understand meaning and retrieve precise answers based on semantic similarity.
- Recommendation Engines: Embeddings represent user and item preferences as numeric vectors, significantly improving personalized recommendations.
- Document Clustering: Embeddings convert documents into vectors, enabling the grouping of similar documents for better organization.
Advantages and Disadvantages of Tokenization and Embeddings
Here are the key advantages and limitations of tokenization and embeddings explained clearly:
Advantages of Tokenization:
- Simple and Fast: Tokenization quickly breaks text into smaller units, making preprocessing efficient for various natural language processing tasks.
- Reduces Text Complexity: By splitting text into tokens, tokenization simplifies input, making it easier for models to process language.
- Standardizes Input: Tokenization converts raw text into consistent tokens, ensuring uniformity across datasets and improving model training quality.
Disadvantages of Tokenization:
- No Understanding of Meaning: Tokenization treats words as discrete units and cannot capture semantic meaning or relationships between tokens.
- Language-dependent: Tokenization methods vary across languages, making it challenging to apply a single approach universally for all texts.
- Cannot Capture Context: Tokenization ignores surrounding words and sentence structure, limiting context understanding in natural language tasks.
Advantages of Embeddings:
- Capture Semantics and Relationships: Embeddings represent words as vectors in a vector space, encoding meaning and the semantic relationships between similar terms.
- Enable Similarity Calculations: Embeddings allow computation of similarity scores between words or sentences, which is useful for search, clustering, and recommendations.
- Improve Model Accuracy: Using embeddings provides richer text representations, enhancing the performance and predictive capabilities of NLP models.
Disadvantages of Embeddings:
- Computationally Expensive: Generating embeddings, especially for large datasets, requires substantial processing power and memory.
- Require Training or Pre-trained Models: Embeddings typically require extensive training on large corpora or rely on pre-trained models to produce meaningful vectors.
- Less Interpretable for Humans: Embedding vectors are abstract numeric representations, making them difficult for humans to interpret intuitively.
Which One Do You Need?
Here is a quick guide to understand their roles clearly:
- If you are preprocessing text → Tokenization is required
- If you want machines to understand meaning, → Embeddings are required
- For NLP models → Both are mandatory
They address distinct problems and complement one another.
Final Thoughts
Understanding tokenization vs embeddings is fundamental to mastering NLP and AI systems. Tokenization breaks text into manageable units, while embeddings transform those units into meaningful numerical representations that machines can interpret. Rather than choosing one over the other, successful NLP systems depend on both working together. Tokenization handles structure; embeddings handle meaning. Together, they form the backbone of modern language intelligence.
Frequently Asked Questions (FAQs)
Q1. Is tokenization the same as embeddings?
Answer: No. Tokenization splits text into units, while embeddings convert those units into meaningful numerical vectors.
Q2. Can embeddings work without tokenization?
Answer: No. Embeddings require tokens as input.
Q3. Are embeddings language-specific?
Answer: Some embeddings are language-specific, while others are multilingual.
Q4. Do large language models use both?
Answer: Yes. Models like GPT and BERT rely heavily on both tokenization and embeddings.
Recommended Articles
We hope that this EDUCBA information on “Tokenization vs Embeddings” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

