Updated March 6, 2023

Introduction to Teradata Qualify
In any SQL language filtering the data is a key aspect. The data will be expected to filter in the most possible way. Here the need for filtration is expected to happen on the existing computed output of a function. So, there will also be a need to apply the filter process over an analytical-based output. So, these qualify clauses will come to place when a user-specified search condition
is considered and accordingly on top of it an analytical function can be covered, with correspondence to this analytical function if filtration is expected to happen then QUALIFY clause can be used. Moreover, the QUALIFY clause is very closely related to the HAVING clause with the only major difference is that for qualify the analytical function will be expected by default. Whereas in the case of HAVING clause the qualify will not be expected. Functionalities like these bring a large extent of flexibility in data level segregation and sophisticated data reporting using high-capability systems like Teradata. So as mentioned before whenever there will also need to apply the filter process over an analytical-based output then the qualifying clause is the best element for use.
Syntax of Teradata Qualify
QUALIFY Search_condition
|
Syntax |
Specifies |
| QUALIFY | The statement of Qualify process is achieved by means of this QUALIFY statement. As notified before this statement is very closely related to the HAVING clause. For the case of an HAVING clause the HAVING clause will be placed without the analytical function being covered up but In this case of the QUALIFY clause the QUALIFY clause is used along with the analytical function output.
|
| search_condition | This belongs to the search condition which is expected to be set by the search rows.
|
Key Points on Qualify
- This is compliant with ANSI standard
- The search conditions which involve the Qualify clause cannot imply a Large object column. So, the process of Qualify cannot be applied on columns that involve these LOB. This applies to any type of LOB’s like CLOB or BLOB or even other LOB’s.
- As explained in the conditions above mentioning the QUALIFY clause must by default involve an analytical or a statistical function associated with it. The analytical or the statistical function must be associated with any of the positions in the latter part of the query.
- When any security constraints are mentioned in the query which involves a QUALIFY clause then it is very important to ensure encoding in place. This means whenever a row-level constraint is in place then accordingly it needs to be ensured and maintained strictly within an encoded format.
- It is mandatory to have a column-level specification active so this can be specified without a default argument. So, mentioning the built-in function allows the arguments handled at the level of the column to operate with a predicate to be involved.
- Sampling is another important process for selecting some specific records from the bucket of available values. This is achieved by means of the SAMPLE clause. By unfortunately the usage of the DEFAULT clause does not allow the sophisticated use of the QUALIFY clause along with it. It is obligatory to have a column-level condition dynamic so this can be quantified without an avoidance argument. So, citing the built-in function consents the arguments handled in the level of the column to operate with a predicate to be involved.
Examples of Teradata Qualify
Following are the examples are given below:
Example #1
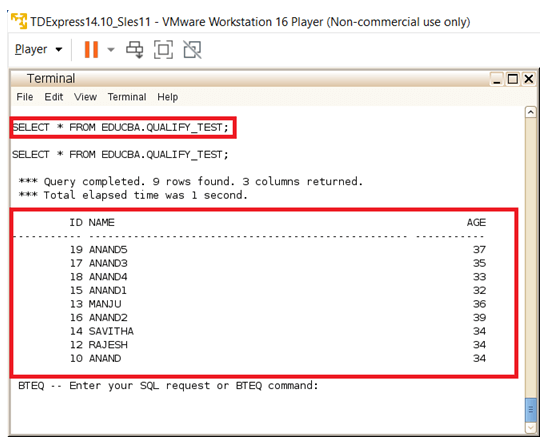
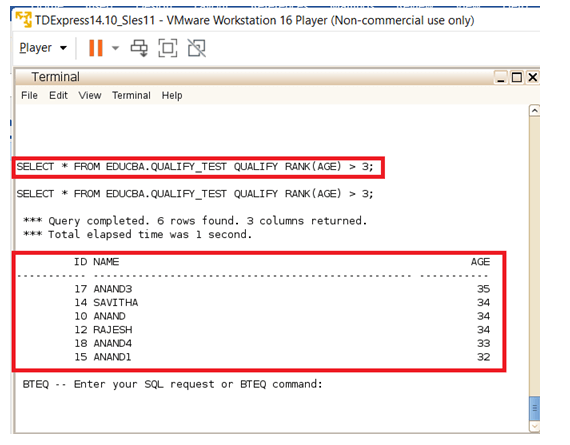
Here in the below given example a test table called Qualify_test is created. The created table is inserted with a large set of records, around 10 records are been inserted. The inserted records are a combination of ID, Name, and AGE. Then these records printed onto the console using the Select statement. From there on the created records are then printed based on the QUALIFY statement. In the Qualify-based print, the records are initially ranked using the RANK function. Then the RANK function is also additionally listed with the condition that to list all the records with AGE values that are greater than the 3rd RANK. So the least age records form the 1st RANK, the Next set forms the 2nd RANK, and the next set forms the 3rd RANK, and the next and goes on. The Query used here takes the records which are equal and greater than RANK 3 and displays them on the console.
Query:
SELECT * FROM EDUCBA.QUALIFY_TEST;SELECT * FROM EDUCBA.QUALIFY_TEST QUALIFY RANK(AGE) > 3;Output:
Example #2
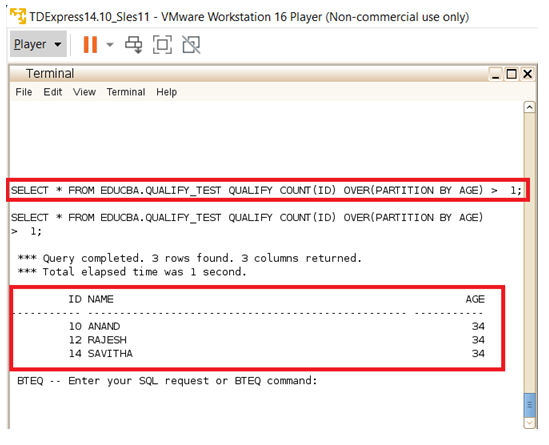
Here in the case of the second example, the analytic function COUNT is used instead of RANK and the usage of QUALIFY clause is represented. The COUNT clause is used along with the OVER clause to make the partition happen. The partition mentions the column on which the QUALIFY clause has to be covered upon. So in this case all the Records with the AGE value occurring more than once is been planned and displayed on the console. We can see the three records displayed has an AGE of 34 and these records are displayed because the count of the AGE is three for the AGE value of 34 since it happens three times.
Query:
SELECT * FROM EDUCBA.QUALIFY_TEST QUALIFY COUNT(ID) OVER (PARTITION BY AGE) > 1;Output:
Conclusion
Filtering records provides the flexibility to pick the needed records alone from the databases. So, options like these provide the flexibility to pick the needed records alone from the huge set of data available. Moreover, the QUALIFY clause performs upon the analytic function such as RANK, COUNT, SUM, or even any further kind of analytic function that can be flexibly applied on top of this. Functionalities like these bring a large extent of flexibility in data level using high capability systems like Teradata. So as mentioned before whenever there will also be a need to apply the filter process over an analytical based output then the qualifying clause is the best element for use.
Recommended Articles
We hope that this EDUCBA information on “Teradata Qualify” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
