Updated April 24, 2023

Introduction to Teradata Coalesce
Teradata Coalesce is a Non-Null evaluation function. Basically, in all SQL environments, these Coalesce and Is Null functions help in the process of Non-Null evaluation. In SQL processing, when a SQL evaluation takes, there could be a possibility of replacing all the Null values with user-defined values. After making this replacement, evaluating the columns for any other Null values in them could be needed. To accomplish this process, the Coalesce can be used effectively. So, coalesce helps by identifying the first Non-NULL item in the given set of arguments. When a set of arguments are passed to the Coalesce function, then the first Non-NULL value in the given argument list is picked. If all the arguments in the string expression are NULL, then a NULL value is returned.
Syntax:
COALESCE (Scalar expression)| Syntax Element | Description |
| Scalar expression | A scalar expression is a set of arguments list; the coalesce function will evaluate these lists of arguments for NULL values. Whenever a NULL value is determined in the argument list, then those will be returned.
At least two arguments requests to be stated in the scalar expression list.
Here scalar expression means an expression that will result in a scalar value; these scalar values are singleton numeric values. A scalar is an informal unattached numeric value (as in 1, 2/3, 3.14, etc.), generally integer, constant point, or float (unmarried or double), in residence of an array, structure, object, complex vector (actual plus imaginary or significance plus perspective components), better dimensional vector or matrix (etc.) |
Teradata SUBSTRING Rules, Types, and Compliance
- The COALESCE is compliant with ANSI SQL:2011 standard.
- The scalar expression will be evaluated twice; for the first time, the search condition will be evaluated, and then for the next time, for the evaluated search condition, a return value will be evaluated.
- There are always restrictions on what kind of data types can be used for the Null verification process of coalescing; some datatypes can be easily used, whereas several other datatypes need a process of casting applied on top to achieve this. The next section briefly describes what processing or casting is required for every type of datatypes. More importantly, data types will return an error if the associated processing is not applied to the data. Moreover, these processing’s are expected for complex data types in the data structure environment. Usual datatypes don’t need it; coalesce can process these simple data types in a single go without applying any predominant processing.
- Below is the list of restrictions that apply to the use of data types like BLOB, CLOB, and UDT in coalescing. When the above-mentioned casting processes are not applied on these datatypes, then it can be used as needed; when cast to BYTE or VARBYTE, then a BLOB datatype variable can be used. BLOB data types cannot be directly used in the argument list without applying this casting process. When cast to CHAR or VARCHAR, then a BLOB datatype variable can be used. BLOB data types cannot be directly used in the argument list without applying this casting process.
- Using a nondeterministic function, which comprises RANDOM, in a scalar_expression_n can likewise additionally partake abrupt results, owing to the element if the principal calculation of scalar_expression_n isn’t NULL, the second one calculation of that scalar_expression_n, which is probably returned as the output from the COALESCE expression, is probably NULL.
- More than column names as arguments in the scalar expression, even scalar subqueries can be applied to the function. More specifically, only scalar subqueries can be used other scalar subqueries if a non-scalar subquery is used, then the error will be returned. These no-scalar functions are functions that involve more than one row.
Teradata COALESCE Example
The Below section mentions examples that involve practical execution of the Teradata COALESCE function; the corresponding snaps for these executions are also shared.
The Snap of the table EDUCBA.COALESC is shared below; This snap holds only FIRSTNAME and LASTNAME Columns in the database; this snap can be used as a reference for the Presence of Null values in the data.
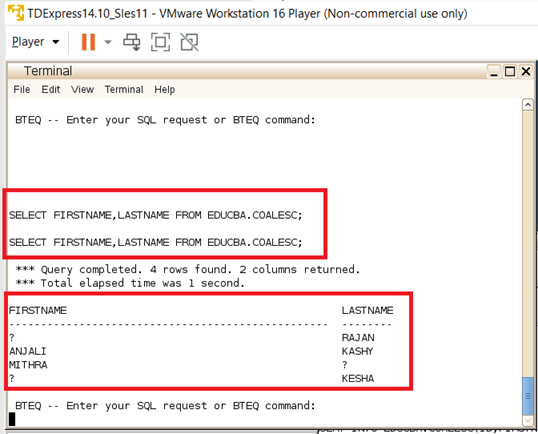
Table Creation and Insertion Queries:
CREATE SET TABLE EDUCBA.COALESCE(ID INTEGER, FIRSTNAME VARCHAR(100),LASTNAME(100));
INSERT INTO EDUCBA.COALESCE(ID, FIRSTNAME, LASTNAME) VALUES(103,NULL,'KESHAV');
INSERT INTO EDUCBA.COALESCE(ID, FIRSTNAME, LASTNAME) VALUES(104,NULL,'RAJAN');
INSERT INTO EDUCBA.COALESCE(ID, FIRSTNAME, LASTNAME) VALUES(105,'MITHRA,NULL);
INSERT INTO EDUCBA.COALESCE(ID, FIRSTNAME, LASTNAME) VALUES(106,'ANJALI','KASHYUP SINGH');
INSERT INTO EDUCBA.COALESCE(ID, FIRSTNAME, LASTNAME) VALUES(107,'ÁGAYANI','MITHAL');Example:
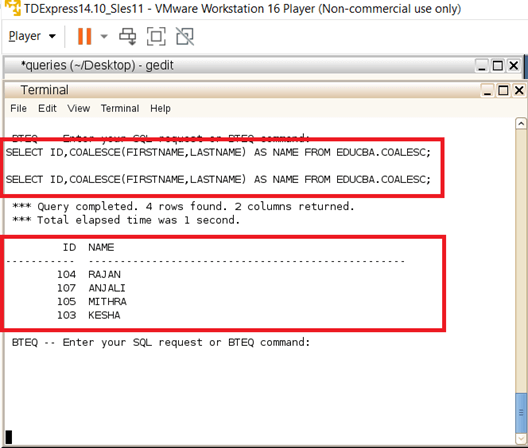
Here the Example Involves tables with three columns in them; the first column is an Integer datatype ID column, whereas the second column is a varchar column of type FIRSTNAME; on the other hand, the third column is of type varchar and is filled with LASTNAME values. Apart from the ID column, NULL values are widely filled in FIRSTNAME and LASTNAME. So, when the COALESCE function is placed upon the FIRSTNAME and LASTNAME columns, it checks and returns the column values, which are not null alone. In case if both the columns are NULL, then a NULL value will be returned. The output of the below Example shows how the rows were valid values; other nulls are alone returned from the query when applied on a COALESCE function.
Query:
SELECT ID, COALESCE (FIRSTNAME, LASTNAME) AS NAME FROM EDUCBA.COALESCE;Snapshot:
Conclusion
Identifying Non-Null or determining the rows involving Non-Nulls is a key data validation process. This process helps to identify the nature of the data being used and the demographical representation of the data. This demographical representation will be a major element for analysts who predominantly work on the data. Here functions like Coalesce are among the most critical predefined functions in relational database-oriented environments, which help to achieve these Null-based evaluations. From a Teradata perception, this enterprise database has multiple techniques to carry out this Null verification or evaluation process, and coalesce is one among them, which can be strongly suggested.
Recommended Articles
We hope that this EDUCBA information on “Teradata coalesces” benefited you. You can view EDUCBA’s recommended articles for more information.
