Updated March 4, 2023

Introduction to Teradata Architecture
Teradata’s architecture provides the capability of massively parallel processing, which certainly follows a divide and conquer approach by dividing a task evenly across the system and that too evenly.
As the name suggests, Teradata is the terabyte-scale relational DBMS utilized for data warehousing needs. It offers quite high speeds due to its architecture; wherein data is distributed over multiple amps. It’s architecture also provides multi-user access by taking advantage of its parallel processing capabilities. Due to similar reasons, it has been a leader in the market for so many years.
Components of Teradata Architecture
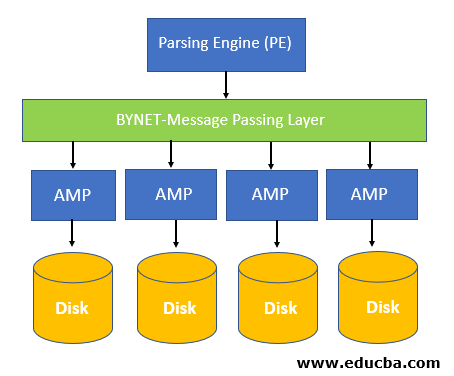
Let’s discuss each in detail to understand Teradata’s architecture:
Parsing Engine(PE)
The parsing engine primarily receives the SQL Query from the client. So, in short, whenever you connect to the Teradata’s engine, you are indeed connecting to the Parsing engine itself.
The parsing engine itself is creating the execution plan for executing the query.
The Parsing engine also checks for the syntax errors before creating the execution plan itself and notifies the user if in case any syntax errors are present.
It also verifies the User privileges. Making sure that if a user does not have access to a certain table or view. Then user access message is sent back to the user as per the records.
- It receives the SQL query,
- Checks for syntax errors, Checks users privileges,
- Passes on the execution plan along with the query to Bynet
- Receives the result from the amp and writes it back to the user
BYNET (Message Passing Layer)
This is a communication layer between the Nodes and the Amp’s and is called the BYNET. It receives the Query along with the execution plan from the parsing engine and sends it to the required amp based on the availability of the data required as per the filtering clauses mentioned in the query. The data is distributed across multiple amp’s, and choosing the appropriate amp is the job of BYNET. There are two BYNET available, BYNET 0 & BYNET 1, to maintain the high availability. If in case one BYNET fails, the other takes over.
Nodes:
A node is nothing but each individual server in the Teradata infrastructure. Each node consists of a standalone:
- Memory
- CPU
- A standalone copy of Teradata RDBMS Software and
- Disc space as well
Access Module Processor (AMP)
As mentioned, an AMP is called the access module processor. These are the vital processors which actually stores and retrieves the data. BYNET sends the query and the execution plan, which it got from the Parsing Engine (PE), to the AMP’s. An AMP is supposed to perform tasks such as aggregation, filtering, grouping, etc., on the respective datasets and then finally saved the results retrieved back to its associated discs. Data is evenly distributed based on the Primary Index column in multiple AMP’s, and only a required AMP is reached out based on that index’s values.
Let’s take an example to understand this in detail:
Suppose we have a list of employee ID’s and that is being used as an index to evenly distribute the data evenly over the AMP’s.
Suppose we have 10 Amp’s available, and the Employee ID ranges from 1 to 1000 in the table
Now, The first 100 Employee ID’s and the associated data will reside in the first Amp
The Employee ID from 101 to 200 and the associated data will reside in the first Amp
The Employee ID from 201 to 300 and the associated data will reside in the third Amp
so on,
and the Employee ID from 901 to 1000, and the associated data will reside in the tenth Amp
This is what we mean by data distribution in an even manner across the amps
Now, if we have a query as below to execute:
select * from table_name where Employee ID = 998How will this get executed?
Once we submit the query, The parsing engine will check for the syntax errors and create the execution plan. Then this query, along with the execution plan, will be passed on to the BYNET, which eventually will connect to the required AMP. The information on which employee ID is available in which AMP is available in the INDEXING table is created while creating the indexes for this table. By looking up this indexing table we know, which amp will be referred for fetching the employee ID = 998. Yes, only the 10th Amp.
How come this reduces the query execution time?
Consider a case where a query needs to scan all of the 1000 records to fetch the data for a single record having an employee ID as 998. This will eventually take some time. But over here in Teradata, due to its current architecture of evenly distributing the data over multiple AMP’s, We only need to check out for a subset of the entire data. In this case, it will be AMP 10 having 100 records only instead of the complete 1000 records. The scan time will be saved in this architecture. In a nutshell, the more the number of AMPs, the lesser will be the execution time required due to the reduced data to be scanned. This is how Teradata also takes advantage of multiple parallel processing as well. AMP’s plays an important role in the same, due to which Multiple AMP’s can be accessed in parallel due to the concept of even data distribution over the multiple AMP’s.
Conclusion
As the name says, Teradata has the capability to save huge data and not only to save but to manage the huge Relational database management systems efficiently as well. It has multiple components for its architecture, namely, Parsing Engine(PE), BYNET: Also known as the message-passing layer, AMP and Disc as well. Data is distributed evenly over the AMP’s, and due to the same, it supports parallel processing as well.
Recommended Articles
We hope that this EDUCBA information on “Teradata Architecture” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
