Updated April 10, 2023
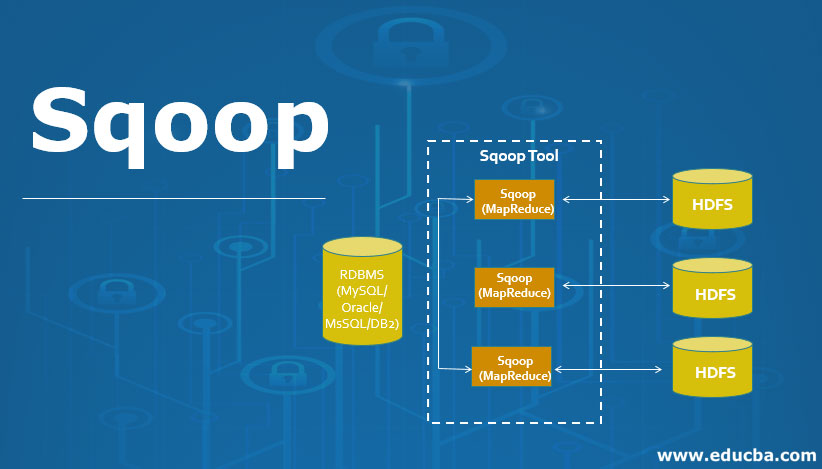
What is Sqoop?
These are the basic points of sqoop, which are given below:
- It is used to transfer the bulk of data between HDFS and Relational Database Servers.
- It is used to import the data from RDBMS to Hadoop and export the data from Hadoop to RDBMS.
- It uses Map Reduce for its import and export operation.
- It also uses a command-line argument for its import and export procedure.
- It also supports the Linux Operating System.
- It is not a cluster service.
- The name “SQOOP” came from ‘SQL’ and ‘Hadoop’, means that the first two letters of Sqoop, i.e. “SQ”, came from SQL, and the last three letters, i.e. “OOP”, came from Hadoop.
- Sqoop always requires “JDBC” and “Connectors”. Here JDBC, i.e. MySQL, Oracle, etc. and Connectors such as Oraoop or Cloudera.
- For the installation of Sqoop, you need a “Binary Tarball.
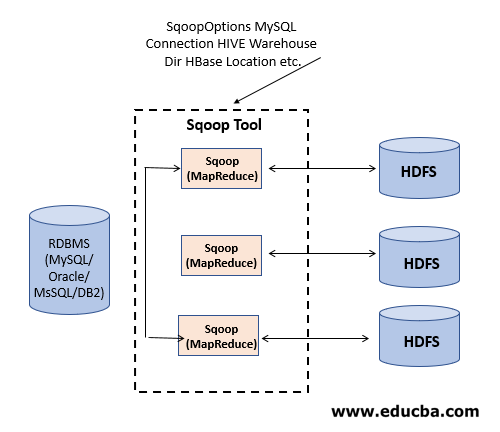
Steps to Complete the Sqoop Action
Here are the steps to follow the sqoop action, which are given below:
- Step 1: It sends the request to RDBMS to send the return of the metadata information about the table (Metadata here is the data about the data).
- Step 2: From the received information, it will generate the java classes (Uses JDBC and Connectors).
- Step 3: Now, Sqoop, post compiling, creates jar file(Java packaging standard), which will be helpful to use the data for our own verification.
Why do we Need Sqoop?
Here are some needs of the scoop, which are given below:
- Apache Sqoop can handle the full load by just a single command which we can call it a Sqoop with full load power.
- It also has incremental load power; you can just load the path of the table where it is updated.
- It uses the Yarn framework to import and export the data, which provides fault tolerance on top of parallelism.
- You can compress your data by specifying the compression code argument; in short, Sqoop is used as a compression also.
- It has a high Kerberos Security Integration.
- You can directly load the data to HIVE using Sqoop.
- It is the best intermediate between the RDBMS and Hadoop.
- It is simple to understand and has easy to go structure.
How Sqoop Works?
This is the working of the scoop, which is given below:
- Sqoop import command imports a table from an RDBMS to HDFS; each record from an RDBMS table is considered as a separate record in HDFS. Records can be stored as text files, and the same results we will get from HDFS, and we can get the outcome in RDBMS format, and the process is called it as export a table.
- It sends the request to Relational DB to send the return of the metadata information about the table (Metadata here is the data about the table in relational DB).
- Sqoop job creates and saves the import and export commands for its processing to get a better outcome, providing us with accurate results.
- It specifies parameters to identify and recall the saved job, which helps to create the point to point relevant results.
- Re-calling or Re-executing is used in the incremental import, which can import the updated rows from the RDBMS table to HDFS and vice versa means that HDFS to RDBMS table and that method is called as export the updated rows.
Sqoop Import and Export
There are two types of scoop, which are given below:
1. Sqoop Import
- You have a database table with an INTEGER primary key.
- You are only appending new rows, and you need to periodically sync the table’s state to Hadoop for further processing.
- Activate Sqoop’s incremental feature by specifying the –incremental parameter.
- The parameter’s value will be the type of incremental import. When your table is only getting new rows, and the existing ones are not changed, use the append mode.
- Sqoop import command imports a table from an RDBMS to HDFS. Each record from a table is considered as a separate record in HDFS. Records can be stored as text files or in binary representation as Avro or SequenceFiles.
Sqoop import --connect --table --username --password --target-dirSyntax:
sqoop import \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table visits \
--incremental append \
--check-column id \
--last-value 1- For importing selected data from a table.
sqoop import --connect --table --username --password --columns –where- For importing data from Query.
sqoop import --connect --table --username -- password –query2. Sqoop Export
This is the query that we are using in sqoop export given below:
sqoop-export--connect --username –password --export-dirAdvantages and Disadvantages of Sqoop
Given below are the advantage and disadvantages of sqoop:
- You need to restrict access to the password file. The Sqoop job will be executed with the permissions of the user running the –exec operation rather than the user who created the saved job. You might need to share the file between the two users.
- It uses the metadata structure, i.e. metadata is nothing but the data about the data that can be unencrypted. In the future, it can be less secure, and anyone can easily retrieve your saved password. So this method might be feasible if you have a dedicated machine with very restricted user access.
How does this Technology help in Career Growth?
These are some points that are included in career growth using this technology:
- It is nothing but one of the intermediates between the two entities with the help of it we can transfer our data from one place to another place with the high-security trust, and for any task, everyone wants to trust and easy to go language which anyone can handle and understand and can apply the concept of it to get the better outcome.
- As it uses the Yarn concept for its processing, so it is very clear to implement the test on any kind of data.
- It helps in career growth by giving us the proper results without any loss of data and can be mixed with any of the environments such as Linux, Yarn, Connectors, Commands, JDBC, Java.
- The most important thing as Java is a well-known language, and it uses the JDBC and Connectors of it to process the output so that we will get the appropriate results at the end of any import and export field structure.
- Overall, it’s a highly demanding technology nowadays to process a large amount of data by using only a single line of import and export statements.
Uses of Sqoop
Given below are some of the uses of Sqoop:
- It is a basic and very understandable language that is very useful to transfer the bulk of data from one place to another without any loss of data, which is basically called importing and exporting data via. Sqoop.
- It is mainly based on SQL and Hadoop and took the suffix and prefix of it, and with that, we got a name as SQOOP.
- It has some specialized connectors which can be used to access the data from the local file system.
- A significant strength of Sqoop is its ability to work with all major and minor database systems and enterprise data warehouses.
- It is a command-line tool that can be called from any shell implementation, such as bash.
- It also supports the Linux Operating System, which is very easy to deal with any of the operations.
- It will automatically serialize the last imported value back into the Metastore after each successful incremental job.
Conclusion
From all this content, we will conclude that Sqoop is nothing but an “OLA” app that RDBMS uses to travel their own set of data to a particular local, i.e. Hadoop and which uses the very secure and trustworthy methods to process its outcome.
Recommended Articles
We hope that this EDUCBA information on “Sqoop” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
