
Definition of spaCy NLP
spaCy NLP stands out among the variety of NLP libraries available today. We will know exactly what we talking about if we have used spaCy for NLP. SpaCy NLP is offering more features like it is easy to use and the library of NLP is up to date. SpaCy is a Python-based NLP library with several features. It is becoming more widely used in NLP for data processing and analysis.
What is spaCy NLP?
- Data is generated in vast quantities, and it is critical to process and extract insights from it. To do so, the data must be represented in computer-readable format. This is something that NLP can assist us with.
- NLP is a technique for extracting information from unstructured text. It has a variety of applications, including.
- Summarization on the fly
- Identification of a named thing
- Systems that respond to inquiries
- Analyzed sentiment
- SpaCy is a Python NLP library that is open-source and free. NLP is an artificial intelligence subfield that deals with computer-human language interactions. The process of analyzing is comprehending.
Creating spaCy NLP
- spaCy is intended for use in information extraction and natural language processing systems. It’s designed to be used in production and has a simple and easy-to-use API.
- Analyze text for semantic analysis and word structure. Integrate techniques borrowed from the domains of text databases, such as WordNet and treebanks.
- For creating spaCy NLP we need to follow the below steps as follows.
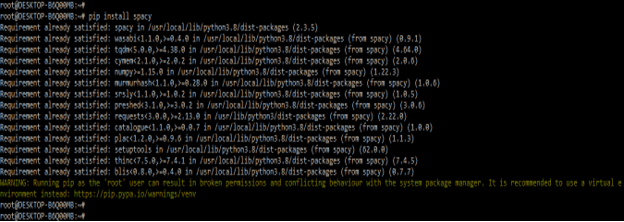
1. In this step, we are installing the spaCy package by using the pip command. In the below example, we have already installed the spaCy package in our system so, it will be showing that the requirement is already satisfied then we have no need to do anything.
Code:
pip install spacyOutput:
2. After installing all the modules, we are opening the python shell by using the python3 command.
Code:
python3Output:

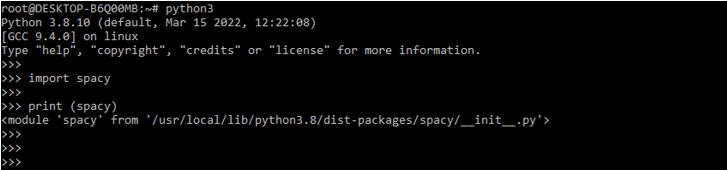
3. After login into the python shell in this step, we are checking bs4 and the requests package is installed in our system.
Code:
import spacy
print (spacy)Output:
4. After checking all the prerequisites in this step we are loading the spaCy modules in our code. We are loading the module by using spacy. load method.
Code:
import spacy
py_NLP = spacy.load('en_core_web_sm')Output:

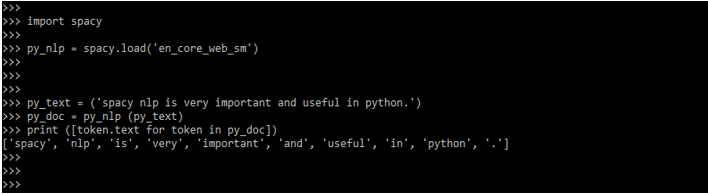
5. After loading the module in the below example we are checking how to read the string as follows.
Code:
import spacy
py_NLP = spacy.load ('en_core_web_sm')
py_text = ('spacy NLP is very important and useful in python.')
py_doc = py_NLP (py_text)
print ([token.text for token in py_doc])Output:
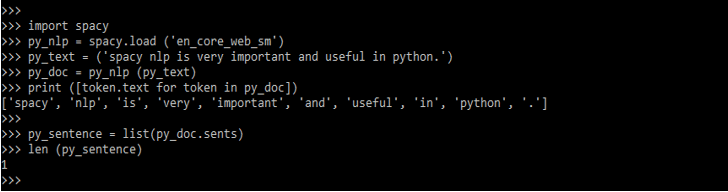
6. In the below example, we have detected the sentences by using spaCy NLP. It will detect how many sentences we have used in the input. It will show the total count of sentences which was we have used in the input.
Code:
import spacy
py_NLP = spacy.load ('en_core_web_sm')
py_text = ('spacy NLP is very important and useful in python.')
py_doc = py_NLP (py_text)
print ([token.text for token in py_doc])
py_sentence = list(py_doc.sents)
len (py_sentence)Output:
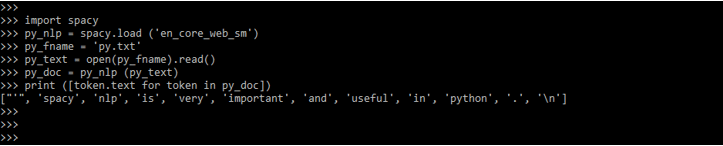
7. In the below example, we have read the content from a text file by using spaCy NLP. We first need to create a text file for the same. We have created a text file name py.txt.
Code:
import spacy
py_NLP = spacy.load ('en_core_web_sm')
py_fname = 'py.txt'
py_text = open (py_fname).read()
py_doc = py_NLP (py_text)
print ([token.text for token in py_doc])Output:
SpaCy NLP model
- The model runs a preparation pipeline as soon as it is invoked on a text. The model takes a sequence of steps (functions) to “understand” subsequent processing.
- Doc is the standard for storing preprocessed objects. These appear to be ordinary text strings, but they aren’t. The data discovered during preprocessing is stored in the doc object, which includes ‘tokens,’ sentences, entities, and parts of speech.
- The below parts are included in preprocessing pipeline of spaCy NLP model.
- Tagger
- Parser
- NER
- Tokenization comes first in the pipeline, followed by the other processes. The text is divided into tokens by this program. Words and punctuation are examples of tokens, which are the smallest elements of the string with semantic significance. The remainder of the pipeline is adaptable.
1. Tagger
- Every token is given a part of speech (POS) by the tagger. The POS tag describes how a token performs both grammatically and semantically within a sentence.
- Common parts of speech include nouns, pronouns, adjectives, verbs, adverbs, and so on. In the English language, there are 36 separate parts of speech that are universally accepted.
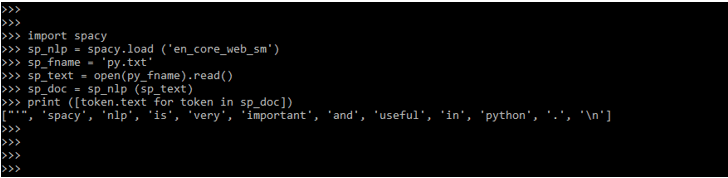
The below example shows how the tagger works in the spaCy NLP model.
Code:
import spacy
sp_NLP = spacy.load ('en_core_web_sm')
sp_fname = 'py.txt'
sp_text = open (py_fname).read()
sp_doc = sp_NLP (sp_text)
print ([token.text for token in sp_doc])Output:
2. Parser
- Sentence boundaries are marked by the parser. It also displays the tokens’ interdependencies. Dependency parsing is what it’s called.
- SpaCy, unlike humans, does not have the ability to “intuitively” know which words are dependent on others.
- It has, however, been trained to anticipate word dependencies using a large amount of data. The dependency parsing text output format is a challenge to grasp.
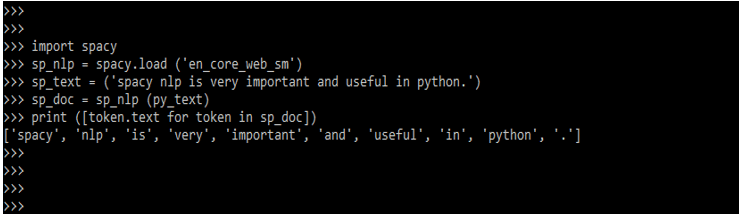
Code:
import spacy
sp_NLP = spacy.load ('en_core_web_sm')
sp_text = ('spacy NLP is very important and useful in python.')
sp_doc = sp_NLP (py_text)
print ([token.text for token in sp_doc])Output:
3. Named entity recognition
- Named entities are “real-world objects” to which a name has been given, such as a location, a country, a commodity, or a work of art.
- Almost a proper noun. However, as we will see, NER isn’t just concerned with the token’s POS.
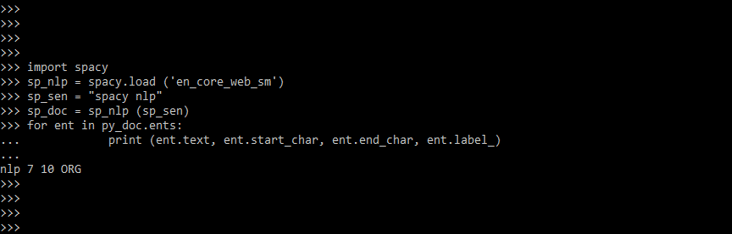
- The below example shows named entity recognition.
Code:
import spacy
sp_NLP = spacy.load ('en_core_web_sm')
sp_sen = "spacy NLP"
sp_doc = sp_NLP (sp_sen)
for ent in py_doc.ents:
print (ent.text, ent.start_char, ent.end_char, ent.label_)Output:
Conclusion
SpaCy is a Python NLP library that is open-source and free. NLP is an artificial intelligence subfield that deals with computer-human language interactions. SpaCy NLP stands out among the variety of NLP libraries available today. SpaCy is a Python NLP library that is open-source and free.
Recommended Articles
This is a guide to spaCy NLP. Here we discuss the Definition, Introduction, how to create, and examples with code implementation. You may also have a look at the following articles to learn more –

