Updated July 6, 2023

Introduction
The Sequential file organization is a popular file organization in the database management system (DBMS). It is a simple technique for file organization structure. This technique stores the data element in the sequence manner that is organized one after another in binary format. The File organization in DBMS supports various data operations such as insert, update, delete, and retrieve the data. The file store the unique data attributes for identification and that helps to place the data element in the sequence. It is logical sequencing in computer memory that stores the data element for the database management systems.
Sequential File Organization Methods
The sequential file organization is one of the categories among various file organizations types. There are two commonly used methods available for organizing the data element in the file storage. The methods are useful to manage and process the data store for sequential file organization
The sequential file organization methods are as follows:
1. Pile file method
It is a standard method for sequential file organization in which the data elements are inserted one after another in the order those are inserted. And in case of a new record being inserted, it is placed at the end position of the file that is after the last inserted data element or record.
In the scenario of data modification or data deletion operation, the particular data element is searched through the sequence in the memory blocks, and after it is found, the update or deletion operation applied to that data element. Also, for the delete operation, the identified data element is marked for deletion and the new block of the record is inserted.
We will discuss the insert operation to demonstrate the pile file method in the sequential file organization using an example scenario.
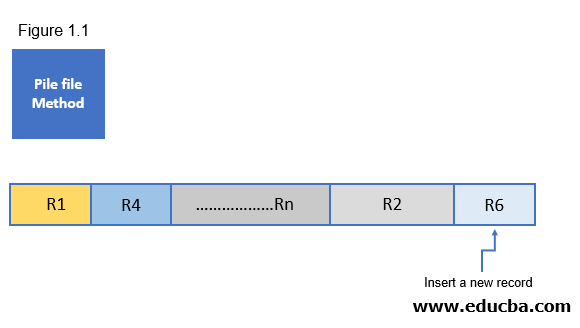
The pile file method is represented with the insert of a new record scenario in figure 1.1. We have represented each data element as one memory block such as R1 for the 1st data element, R4 is the second data element, and the R2 is the last data element of the file. Once a new data element named R6 is inserted into the file structure, It will be placed and stored after the R2 and it is the end of the file position.
Figure 1.1 shows the pile file method working process in the sequential file organization in the database management system.
2. Sorted file method
The Sorted file method is another popular method for it in the database management system. This method provisions the data element to be arranged and stored in the shorted order. The data elements are stored as ascending or descending order based upon the primary key or any other key reference.
In the case of the shorted file method scenario, the new data element or the new record is inserted at the end position of the file. After the inserting step, It then gets shorted in the ascending or the descending order based upon the key.
For the update or data modification scenario, the data element is searched, and updated based upon the condition. And, after the update operation completes the shorting process happens to rearrange the data elements, and the updated data element is placed at the right position of the sequential file structure.
Similarly, for deletion operation, the data item is searched through the shorted sequence, and mark as delete once it gets identified. After the delete operation completes the other data elements are get shorted and rearranged again with the original ascending or descending order.
We will discuss the insert operation to demonstrate the shorted file method in the sequential file organization using an example scenario.
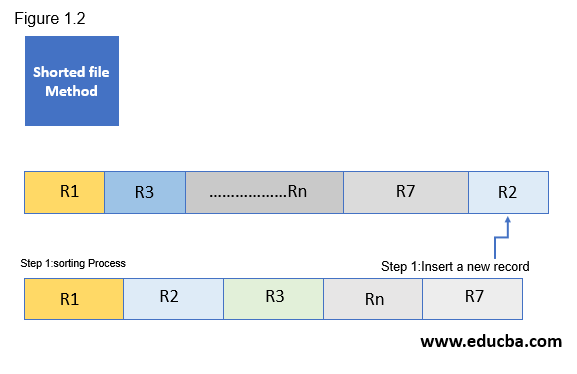
Let us assume, there is a sequential file contains R1, R3, Rn, R7 data elements and are present in ascending order based on the primary key reference. A new record R2 is inserted after R7 that is the end of the file position and all the records are shorted and R2 is placed one the second position after the record R1.
Figure 1.2 represents the two-step process for the shorted file method for sequential file organization.
Step 1- Insert a new record R2 at the end of the file position
Step 2- After the R2 insert completes, it gets shorted in the ascending order.
Advantages and Disadvantages
IN this section, we will discuss some of the advantages and the disadvantages of the sequential file organization from the uses, efficiency, and resource dependency aspects.
Advantages
- The sequential file organization is efficient and process faster for the large volume of data.
- It is a simple file organization compared to other available file organization methods.
- This method can be implemented using cheaper storage devices such as magnetic tapes.
- It requires fewer efforts to store and maintain data elements.
- The sequential file organization technique is useful for report generation and statistical computation process.
- This file organization is a preferred method for calculating aggregates that involve most of the data elements that have to be accessed while performing the computation process. Some of the popular use cases are calculating grades for the students, generating payslips for the employees, and generating the invoices in the business.
Disadvantages
- The shorting operation is a time-consuming process and more memory space for the shorted file method in the sequential file organization.
- The shorting operations iterate for every writes operation such as insert, update, or delete
- The traversing time is high in the sequential file organization as for each writes operation, the system or the program control cannot find a particular data item directly at one go, it has to traverse through the sequence of data items.
Conclusion
The sequential file organization is the basic form of data storage techniques that are useful for large volumes of data storage and processing systems. The sequential file organization that holds the named collection of information on the secondary storage like the magnetic disk, optical disks, and magnetic tables in the sequential order.
Recommended Articles
This is a guide to discuss the introduction of Sequential File Organization, methods, advantages, and disadvantages. You can also go through our other related articles to learn more –
