
Definition of Scrapy Python
Scrapy Python is a lightweight, open-source web crawling tool developed in Python that extracts data from online pages using XPath selectors. Nowadays, data is everything, and one approach to collect data from websites is to use an API or employ Web Scraping techniques. The act of extracting data from websites throughout the Internet is known as web scraping or web data extraction.
What is Scrapy Python?
- Web scrapers, also known as web crawlers, are programs that browse through web pages and retrieve the information needed. These data, which are typically vast amounts of text, can be analyzed to understand products better.
- Scrapy introduces a number of new capabilities, such as the ability to create a spider, run it, and subsequently scrap data. Python web scraping is involving two steps first is web scraping, and the second is crawling.
Scrapy Python Web Scraping
- The diversity and volume of data available on the internet nowadays are like a treasure mine of secrets and riddles. There are so many applications that the list goes on and on.
- However, there is no standard procedure for extracting this type of information, and most of it is unstructured and noisy. Web scraping becomes a vital tool in a data scientist’s toolset in these circumstances.
- It provides us with all of the tools we will need to quickly extract and process the data as needed from websites and save it in the structure and format of our choice.
- There is no “one size fits all” technique for extracting data from websites, given the diversity of the internet. Many times, improvised solutions are used, and if suppose we are writing the code for a single operation, we will wind up with our own scraping framework. That structure is scrapy.
- To run web scrapping code, first, we need to set up our system. Scrapy is supporting both versions of Python i.e. 2 and 3. In our system, we are using the Python 3 versions to set up scrapy.
- We can install the scrapy package by using conda or by using the pip command in the Windows system.
- In the below example, we have installed scrapy in our system by using the pip command. The Pip command is used to install a package of Python in a Windows environment.
Code:
Pip install scrapyOutput:
After installing the scrapy by using the pip command, the next step is to login into the shell by using scrapy. To login into the scrapy shell, we need to use the below command as follows.
Code:
scrapy shellOutput;
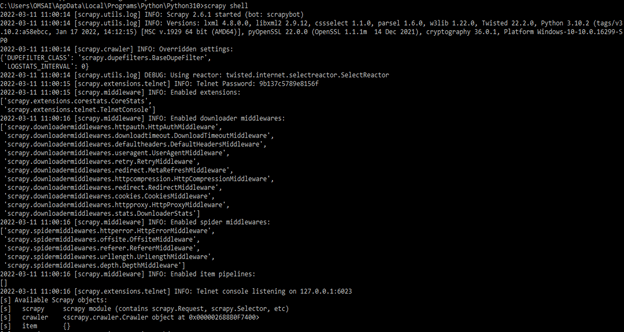
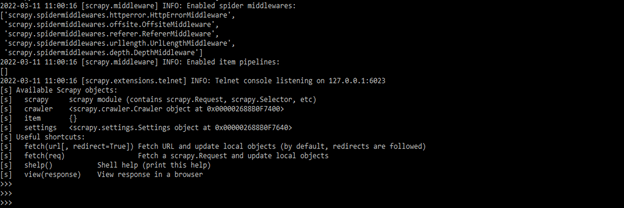
- In the above example, we can see that it will open the scrapy shell window. Scrapy is writing a bunch of stuff. In the below example, we are getting the information from Google.
- In the below example, we can see that executing a fetch command on the Google website will give the response through this website.

- When we scrawl something by using scrapy, it will return the response object, which contains the information of download. We can check what information was downloaded by the crawler by using the following command.
Code:
view (response)Output:


- We can see the above image it will look like the exact website of Google; the crawler downloaded the entire Google webpage. We can check the raw content of the downloaded web page by using the following commands. The raw data of the downloaded webpage was stored in response.text file. The below example shows to check the raw data of the downloaded web page as follows.
Code:
print (response.text)Output:
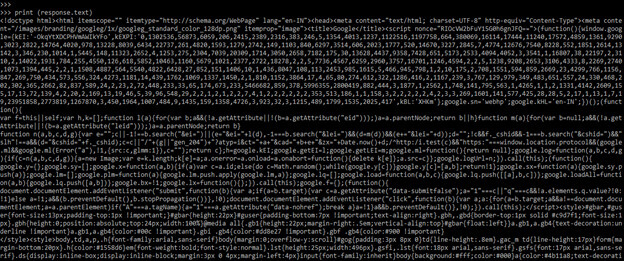
- In the below example, we are extracting the Google search option as search only. We are using inspect option to change this value. To use inspect, we need to right-click on the tab which we need to inspect. After right-clicking on the tab, it will show multiple options, in the multiple options, we need to click on inspect options. After clicking on the inspecting option, the web page will look like the one below.
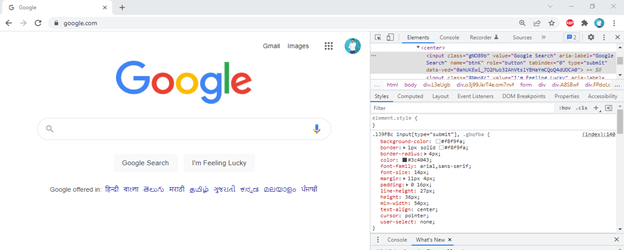
- After opening a tab in inspect mode, we can change the name of the title, and also we can change another parameter like font size or color. In the below example, we have to change the title of the Google search tab search. We have changed the same by editing the HTML file as follows.
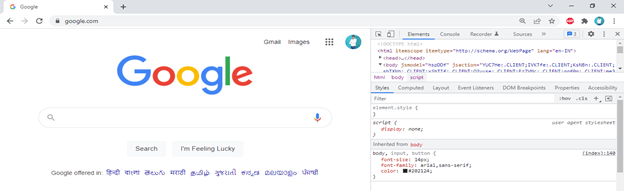
- In the above example, we can see that the title of the tab is changed from Google search to search, which we have changed in the elements section.
- The below example shows to create a new scrapy project name as test_scrapy. We are creating a new project of scrapy by using the scrapy startproject command.
Code:
scrapy startproject test_scrapyOutput:

- After creating the scrapy project, we can start the same by using the following command. The below example shows the start of the scrapy project as follows.
Code:
cd test_scrapy
scrapy genspider example example.comOutput:

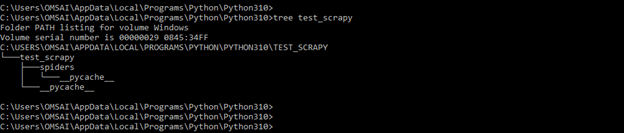
- We can check the structure of the scrapy project by using the tree command. In the below example, we can see that it will show the project structure in tree format.
Code:
tree test_scrapyOutput:
- To construct a parse method that fetches all URLs will yield the results. This will happen again and again when we fetch further links from that page. In other words, we’re retrieving all of the URLs on that page.
- By default, Scrapy filters out URLs that have already been visited. As a result, it won’t crawl twice. However, it’s feasible that two or more comparable links exist on two different pages. For example, the header link will be visible on each page.
- Always build one class with a unique name and establish requirements when constructing a spider.
- The spider must first be given a name by using the name variable, and then the spider will begin crawling. Define several strategies for crawling far deeper into the webpage.
Conclusion
Scrapy introduces a number of new capabilities, such as the ability to create a spider, run it, and subsequently scrap data. Scrapy Python is a lightweight, open-source web crawling tool developed in Python that extracts data from online pages using XPath selectors. Scrapy is more important in Python.
Recommended Articles
We hope that this EDUCBA information on “Scrapy Python” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
