Updated April 4, 2023

Introduction to Scrapy LinkExtractor
Scrapy LinkExtractor is an object which extracts the links from answers and is referred to as a link extractor. LxmlLinkExtractor’s init method accepts parameters that control which links can be extracted. A matching Link object is returned by LxmlLinkExtractor.extract links from a Response object. Regular spiders can also benefit from link extractors. For example, make LinkExtractor a class variable in our spider and use it from spider callbacks.
What is Scrapy LinkExtractor?
- Crawl spiders employ a series of Rule objects to extract links. Link extractors are objects with the sole aim of extracting links that will be followed afterward.
- We can use Scrapy’s LinkExtractor to construct our custom Link Extractors, but we can also use a simple interface to create our own.
- Objects that are linked. To extract links, link extractors should be instantiated. Link extractors are utilized in a class of CrawlSpider via a set of rules, but we can use them in our spiders even if we don’t subclass from CrawlSpider because their function is simple to extract the links.
How to build Scrapy LinkExtractor?
- Extract links, which takes a Response object and produces a list of scrapy. Links are the sole public method that every link extractor uses.
- As their name suggests, Link Extractors are scrapy things that links extract from web pages. For example, HTTP. A web server returns response objects in response to a request.
- Scrapy includes extractor’s built-in, such as scrapy. LinkExtractor is imported. Implementing a basic interface allows us to create our link extractor to meet our needs.
- Scrapy link extractor contains a public method called extract links, which takes a Response object as an argument and returns a list of scrapy.link.
- Objects that are linked. We can only use the link extractors once, but we can run the extract links method multiple times to get links with varying responses.
- The CrawlSpiderclass employs link extractors, which are rules with the sole aim of extracting links.
- Follow indicates if each response’s links should be followed. We will obtain any nested URLs because we set it to True.
Below step shows how to build a scrapy LinkExtractor as follows:
1. In this step, we install the scrapy using the pip command. In the below example, we have already installed a scrapy package in our system, so it will show that the requirement is already satisfied, so we do not need to do anything.
Code:
pip install scrapyOutput:
2. After installing the scrapy in this step, we log into the python shell using the python command.
Code:
pythonOutput:

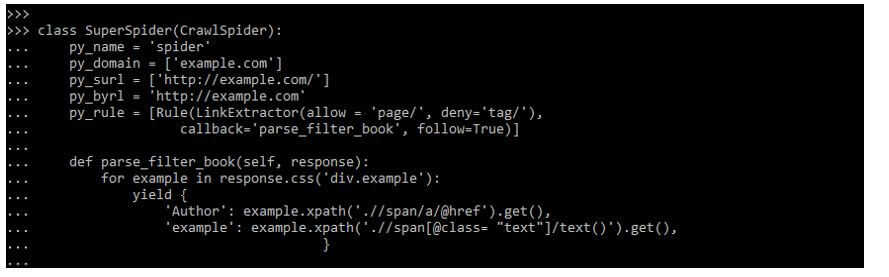
3. The below example shows how to build the scrapy link extractor.
Code:
class SuperSpider (CrawlSpider):
py_name = 'spider'
py_domain = ['example.com']
py_surl = ['http://example.com/']
py_byrl = 'http://example.com'
py_rule = [Rule(LinkExtractor(allow = 'page/', deny='tag/'),
callback = 'parse_filter_book', follow=True)]
def parse_filter_book(self, response):
for example in response.css ('div.example'):
yield {
'Author': example.xpath ('.//span/a/@href').get(),
'example': example.xpath('.//span[@class= "text"]/text()').get(),
}Output:
Scrapy LinkExtractor Parameter
Below is the parameter which we are using while building a link extractor as follows:
- Allow: It allows us to use the expression or a set of expressions to match the URL we want to extract.
- Deny: It excludes or blocks a single or extracted set of expressions. It will not delete the unwanted links if it is not indicated or left empty.
- Allow_domain: It accepts a single string or a list corresponding to the domains from which the connections are to be pulled.
- Deny_domain: It blocks a single string or a list corresponding to the domains from which the connections are to be pulled.
- Deny_extensions: It blocks an extension corresponding to the domains from which the connections are to be pulled.
- Restrict_xpath: It’s an XPath where the response’s links will be extracted. The links will only be pulled from XPath’s text if this option is selected.
- Restrict_css: It works the same way as the restrict xpaths argument, which extracts links from CSS-selected sections within the response.
- Tags: When extracting links, a tag or set should be considered. It will be (‘a’,’area’) by default.
- Attrs: A single attribute or a set of attr is taken when extracting links.
- Canonicalize: Scrapy.utils.url.canonicalize url is used to convert the retrieved url to a standard format.
- Unique: This parameter is extracted when the links are repeated.
- Process_value: It’s a function that gets a value from tags and attributes that have been scanned. The received value may be changed and returned.
Scrapy LinkExtractor Rules
- The CrawlSpider contains the attribute rules and the same properties as a standard Spider.
- The term Rules refers to a collection of one or more Rule objects, each describing a different type of crawling behavior.
- Additionally, LinkExtractor will be used: This object specifies how each crawled page’s links will be extracted.
- Rules define how the webpage will crawl, and LinkExtractor will extract links. Finally, we import the assets and construct a single rule; we will define how links are taken, where they come from, and what we will do with them in this rule.
- Allow=’catalogue/’ is the first option. We will no longer process URLs that do not contain the string’ catalog/.’ Isn’t this a lot better than the previous IFs?
- A callback is also available. After completing a process, we do a callback in programming. For example, it indicates, Calls the parse filter book method while getting a URL.
- The Internet is vast, with several components, divisions, and subsections. As a result, there are numerous advantages to using Scrapy’s Rules class. It enables us to extend the capabilities of our spider, improve existing features, and develop new possibilities.
Below example shows scrapy LinkExtractor rules as follows:
Code:
class SuperSpider(CrawlSpider):
py_name = 'python_books'
py_surl = ['http://example.com/']
py_rule = [Rule(LinkExtractor(allow = "Topic"), callback='parse_func', follow = True)]Output:

Conclusion
We can use Scrapy’s LinkExtractor to construct our custom Link Extractors, but we also use a simple interface to create our own. Scrapy LinkExtractor is an object which extracts links from answers and is referred to as a link extractor. LxmlLinkExtractor’s init method accepts parameters that control which links can be extracted.
Recommended Articles
We hope that this EDUCBA information on “Scrapy LinkExtractor” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
