Updated February 18, 2023
Introduction to Redis Persistence
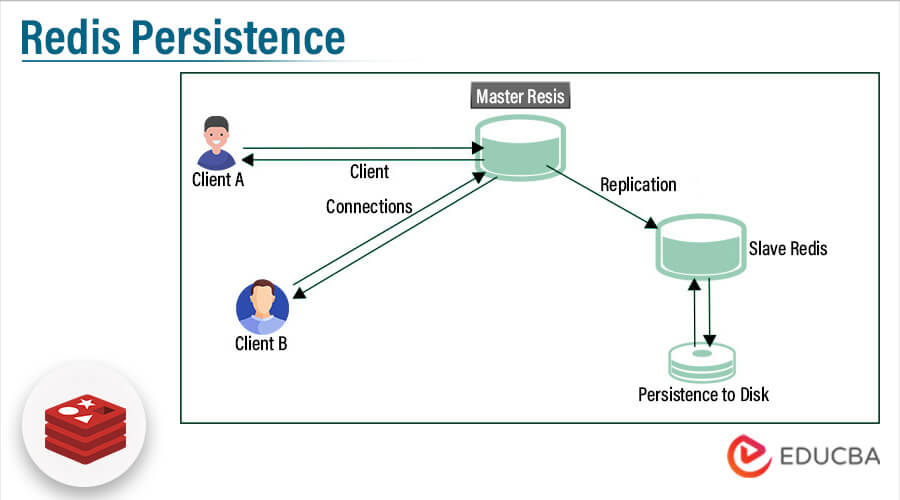
All types of data are saved and managed in RAM or flash memory and the chances of data loss are more. So Redis enterprise software is not only a cache or message broker but put on full efforts to make the data safe and persist in the disk as critical. Persistence in data can be configured at the time of database creation or the user can also edit the database configuration. So in Redis, data persistence is made on a database by multiple methods.
Key Takeaways
- Redis commands are created using the same format as Redis protocol, which follows append-only action.
- Redis can rewrite the data log in the background when it is maximum.
- Redis enterprise enhances the storage engine of Redis to maximize the throughput in Redis core by enabling data persistence.
What is Redis Persistence?
In simple, persistence is the writing of data into a durable storage device like a solid-state disk and Redis persistence throws multiple options for data durability and can be configured and edited when required. So depending on the database size, the user can choose his persistent model. The different persistent models are Redis database called RDB, and AOF i.e append-only file, no persistence, and a combination of RDB and AOF.
The Redis database (RDB) persistence performs the in-time point snapshot of the dataset at regular intervals.
Append only file (AOF) captures every write action managed by the server, which is executed again at server initializing time, then it rebuilds the actual dataset.
If the user set no persistence, the user can disable the persistent option completely, and here the data exists till the server is running. AOF + RDB: At the same instance, the user can imply both RDB and AOF. Here the Redis is restarted when the AOF file is reconstructed in the actual dataset and marked as most complete.
Redis Persistence Keys
Using Redis persistent connection, the PHP-FPM model pool creates varied PHP processes and with that, the user can create more connections with the Redis server, which helps to manage and triggers the highest number of client hit errors. The storage layer of Redis enterprise enables multiple Redis instances to compile the same persistent storage without blocking action, that is the user can constantly write to disk by AOF rewrite method and it doesn’t block other actions from implying durable operations.
Syntax of persistence keys:
PERSIST keyIt is available from version 2.0 and here the complexity of time is 0(1).
How to Setup Data Redis Persistence?
In the database option, choose to add or (+) to build a new database. Choose the database that needs to be configured at the bottom and click page edit.
Move to the persistence option.
Choose the required database persistence option.
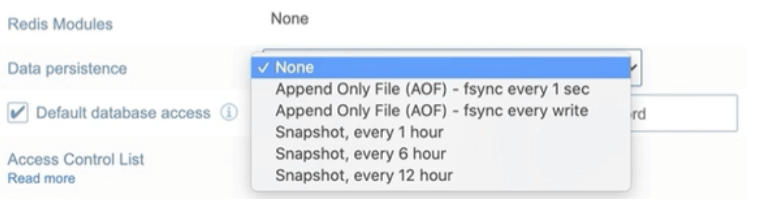
Save or update done.
There are six persistence options available in Redis enterprise:
- None – Here the information is not persisted to the SSD.
- AOF, Append only file on every write – Data is completely synced to SSD at every write.
- AOF, Append only file on every second – Data is synced to SSD at every second.
- Every 1-hour snapshot – Database snapshot is created for every hour.
- Every 6 hours snapshot – Database snapshot is created every six hours.
- Every 12-hour snapshot – Database snapshot is created every 12 hours.

Redis Persistence Durable Storage
Redis Enterprise is a complete end-to-end durable database. If any AOF method is applied for the persistence of the database, then the size of the file increases with each write execution, and the rewrite process of AOF is then executed to manage the size of that file and decreases the recovery time from the disk. As a default option, the Redis executes a rewrite action when the AOF size is doubled the before rewrite execution.
In the write cases, the rewrite action can stop the important loop of Redis and other instances which are executed in the similar cluster node and then enables all the ongoing actions to the disk. Redis enterprise works on a greedy algorithm that postpones the AOF write operation, without invading the recovery time’s SLA. It also prevents the rewrite operation from achieving the disk limits. The optimum use of the rewrite option and throughput value is higher than expected.
Redis Persistent Commands
Redis persist command is implied to delete the existing timeout option on a key and execute that key from the volatile state to persistent. That is the key from the expiration set to the key where it will not expire when no timeout option is given.
Syntax:
PERSIST KEY _ NAME
PERSIST (command)Categories of ACL are @write, @fast, and @keyspace.
Redis Persistence of AOF and RDB Differences
Given below are the differences:
| Terms | AOF |
RDB |
| Definition | It is expanded as Append only file and here every piece of the Redis database appends to the new line to the already persisting file. | It is also called a snapshot and is configurable, here the dataset is compiled to persistent storage across all fragments of the database. |
| Secure | The process is fast, but security is minimum. | Here the process is slow, but it is highly secured. |
| Durability | Better durability. | Minimum durability. |
| Recovery time | The recovery process is slow. | Prompt and rapid recovery time. |
| Disk space | Maximum disk space is required. | Require only minimum resource. |
| Intensity | Maximum resource intensive. | Minimum resource intensive. |
FAQ
Given below are the FAQs mentioned:
Q1. How to store data permanently in Redis?
Answer: By using RDB, SAVE command, and AOF the user can save the data. The Redis copies all the data to memory and saves them as secondary storage that happens at particular intervals.
Q2. Can Redis work better on big data?
Answer: Redis is a top-performance key database that is a vital element in applications of big data. As it is a NoSQL database, Redis supports the enterprise by scalability which is cost-effective and convenient.
Q3. What happens if Redis runs out of space?
Answer: If the limit is achieved, the Redis will throw an error to compile commands but continues to receive read-only commands or the user can configure to evict the keys, if it reaches the maximum limit, then it can follow caching.
Conclusion
Redis utilize the cluster resources better by enabling multiple Redis instances to execute on a similar cluster node unless affecting the performance. Hence the user can choose his required persistent model to save his data.
Recommended Articles
This is a guide to Redis Persistence. Here we discuss the introduction, how to set up data redis persistence. durable storage and differences. You may also have a look at the following articles to learn more –
