Updated April 12, 2023

Introduction to PySpark Window Functions
PySpark window is a spark function that is used to calculate windows function with the data. The normal windows function includes the function such as rank, row number that are used to operate over the input rows and generate result. It is also known as windowing or windowed function that generally performs calculation over a set a row, this row can be called as frame. Post aggregation or applying the function a new value is returned for each row that will correspond to it value given . We can also take the use of SQL related queries over the PySpark data frame and apply for the same. The window operation wor ks on group of rows and returns a single value for every input row by applying the aggregate function. There are several kinds of window operation that can be applied to the data to compute the result.
PySpark Window Functions with Example
Given below are the PySpark Window Functions with example:
1. Ranking Function
These are the window function in PySpark that are used to work over the ranking of data. There are several ranking functions that are used to work with the data and compute result.
Lets check some ranking function in detail.
a. ROW_NUMBER(): This gives the row number of the row. It starts with 1 and the row number keeps on increasing based on the partition element.
Lets start by making a simple data frame on which we will try to implement the window function. A data frame of students with the concerned Dept. and over all semester marks is taken for consideration and data frame is made upon that.
Code:
data1 = (("Bob", "IT", 4500), \
("Maria", "IT", 4600), \
("James", "IT", 3850), \
("Maria", "HR", 4500), \
("James", "IT", 4500), \
("Sam", "HR", 3300), \
("Jen", "HR", 3900), \
("Jeff", "Marketing", 4500), \
("Anand", "Marketing", 2000),\
("Shaid", "IT", 3850) \
)
col= ["Name", "MBA_Stream", "SEM_MARKS"]
b = spark.createDataFrame(data1,col)The create data to create the Data Frame from the column and Data.
b.printSchema()
from pyspark.sql.window import WindowThe window function to be used for Window operation.
from pyspark.sql.functions import row_numberThe Row_number window function to calculate the row number based on partition.
w = Window.partitionBy("MBA_Stream").orderBy("Name")The column over which is to used and the order by operation to be used for.
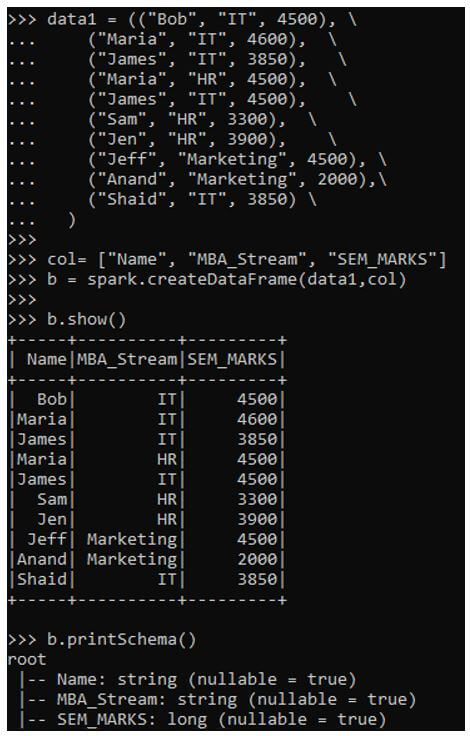
b.withColumn("Windowfunc_row",row_number().over(w)).show()This will create a Data Frame an use the row_number window function to calculate the row_number for the given Data Frame.
Output:
b. RANK Function: This function is used to provide with the Rank of the given data frame. This is a window operation that is used to create the Rank from the Data Frame.
We will try to import the Ranking function from the SQL Rank Function.
Code:
from pyspark.sql.functions import rankThis will import the rank function in which we can calculate the Rank .
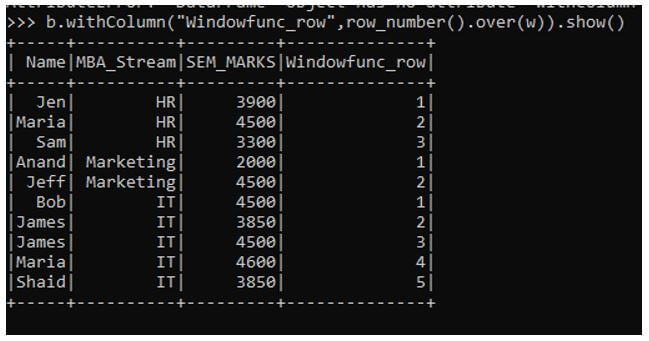
b.withColumn("Window_Rank",rank().over(w)).show()This will rank the element over the given condition as suggested.
Output:
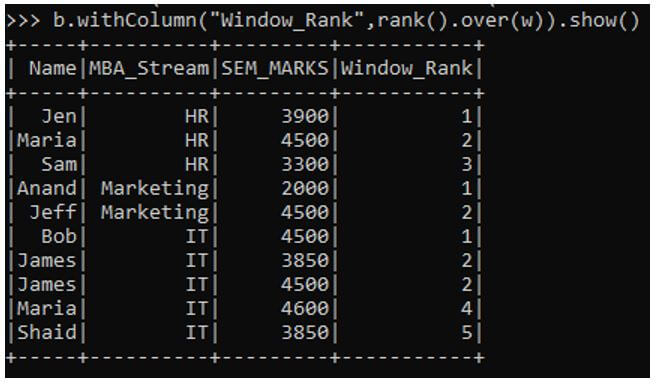
c. DENSE-RANK Function: Similar to Rank Function this is also used to rank elements but the difference being the ranking is without any gaps.
We will import the Dense Rank Function.
Code:
from pyspark.sql.functions import dense_rank
b.withColumn("Window_DeneRank",dense_rank().over(w)).show()Output:
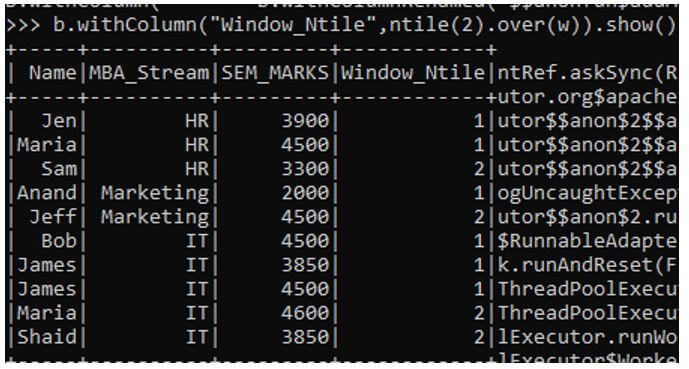
d. NTILE Function: It returns the relative rank of the result, it has an argument value from where the ranking element will lie on.
Example:
Code:
from pyspark.sql.functions import ntile
b.withColumn("Window_Ntile",ntile(2).over(w)).show()Here we have given the argument as 2 that will rank the function based on that value only.
Output:
2. Analytics Function
These are the window function used for analytics for Data stream.
Let us look over some Analytics function:
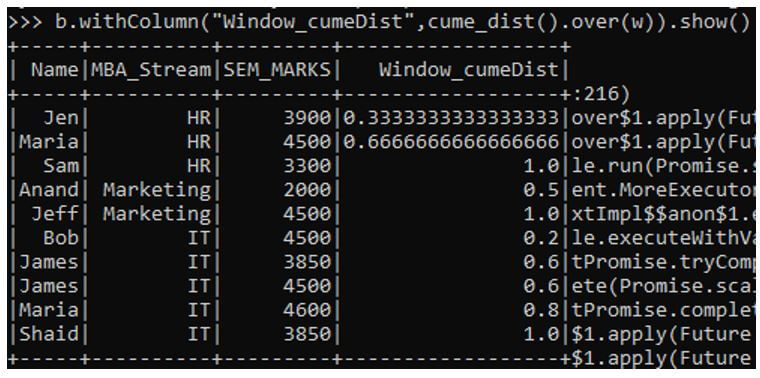
a. Cume_dist() function: It gives the cumulative distribution for the value over the partition.
Code:
b.withColumn("Window_cumeDist",cume_dist().over(w)).show()Output:
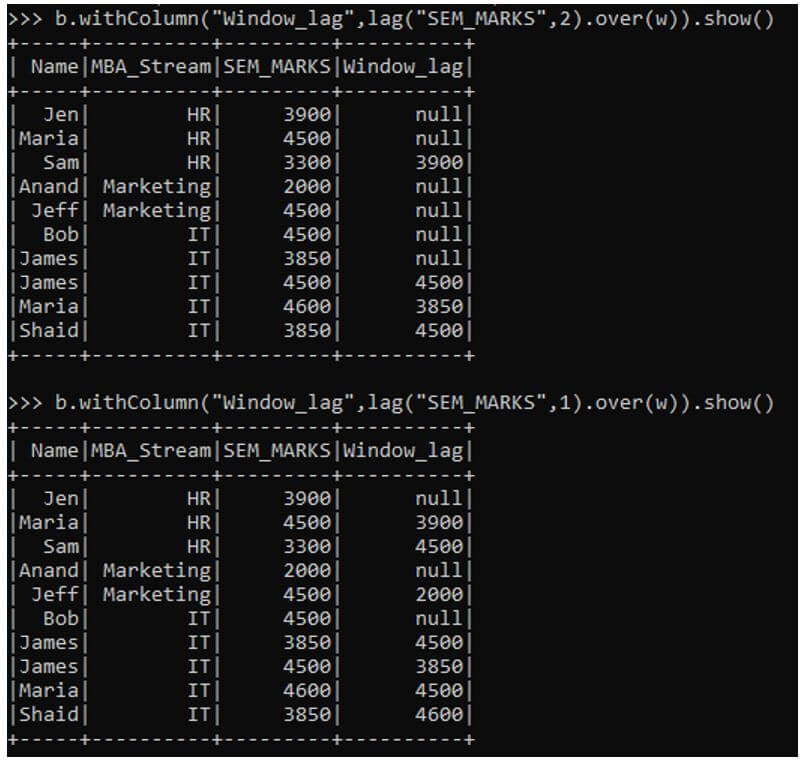
b. LAG Function: This is a window function used to access the previous data from the defined offset value.
Example:
Code:
b.withColumn("Window_lag",lag("SEM_MARKS",1).over(w)).show()This gives the previous value of the columns used.
The same offset can be adjusted and we can take the value needed.
b.withColumn("Window_lag",lag("SEM_MARKS",2).over(w)).show()Output:
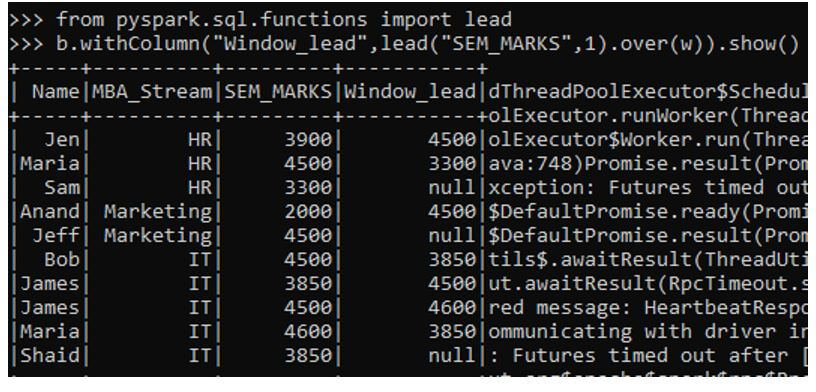
c. LEAD Function: This is a window function used to access the next data from the defined offset value.
Code:
from pyspark.sql.functions import lead
b.withColumn("Window_lead",lead("SEM_MARKS",1).over(w)).show()Output:
From here we see the use of different Window Function in PySpark.
Conclusion
From the above article we saw the use of Window Function in PySpark. From various example and classification we tried to understand how the window method works in PySpark and what are is use in the programming level. The working model made us understood properly the insights of the function and helped us gaining more knowledge about the same. The syntax helped out to check the exacts parameters used and the functional knowledge of the function. We also saw the internal working and the advantages of having Window Function in PySpark in Spark Data Frame and its usage in various programming purpose. Also the syntax and examples helped us to understand much precisely over the function.
Recommended Articles
We hope that this EDUCBA information on “PySpark Window Functions” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

