Updated April 11, 2023

Introduction to PySpark Read JSON
PySpark Read JSON is a method in PySpark data frame model that is used to read a JSON file from a location. This method reads up a JSON file and creates a Data frame out of it. A Json file format and an easy and reliable method for storing and movement of data. This JavaScript Object Notation handles the data in a format and the PySpark model can converts this data into a data frame by reading it with PySpark read json method. The JSON data while conversion makes it easier for a data scientist to analyze the data and perform optimized operations over the same.
In this article, we will try to analyze the various ways of using the PYSPARK READ JSON operation PySpark.
Syntax:
The syntax for PYSPARK Read JSON function is:
A = spark.read.json("path\\sample.json")- a: The new Data Frame made out by reading the JSON file out of it.
- Read.json():- The Method used to Read the JSON File (Sample JSON, whose path is provided in the path)
Screenshot:
![]()
Working of read JSON functions PySpark
- A JSON file JavaScript Object Notation is a text format method for storing and representing data. It is a self-describing model that is easy to understand and can be used for data movement over the network.
- In Spark this JSON data can be directly used to store the data into a data frame and the data-related operation becomes easier. The PySpark Model automatically infers the schema of JSON files and loads the data out of it.
- The method spark.read.json() or the method spark.read.format().load() takes up the parameter of the JSON file and loads data out of it into a JSON file.
- The first method directly takes up the path of a JSON file while the other first defines the format and then load the file from that path in JSON.
- Spark takes the first value as the column value in JSON and the data elements there with a value are stored out of it. One Row column is read out and the data element is put into a row in Data Frame.
- This can be read multiple lines at a time by using the option Multiline as True.
- Multiple files or all files in a directory can be read out and data can be stored into Data frame model on an PySpark while reading the JSON file.
Let’s check the creation and working of PYSPARK Read JSON with some coding examples.
Examples
Let’s start by making a sample JSON file that we will use for reading purposes in using the Spark.read.json method.
Sample JSON is stored in a directory location:
{"ID":1,"Name":"Arpit","City":"BAN","State":"KA","Country":"IND","Stream":"Engg.","Profession":"S Engg","Age":25,"Sex":"M","Martial_Status":"Single"},
{"ID":2,"Name":"Simmi","City":"HARDIWAR","State":"UK","Country":"IND","Stream":"MBBS","Profession":"Doctor","Age":28,"Sex":"F","Martial_Status":"Married"},
{"ID":2,"Name":"Awanti","City":"Varansi","State":"UP","Country":"IND","Stream":"Commerece","Profession":"CA","Age":24,"Sex":"F","Martial_Status":"Single"}This JSON file is used to store and load the data in Spark Application.
spark.read.json("path\\sample.json")
DataFrame[Age: bigint, City: string, Country: string, ID: bigint, Martial_Status: string, Name: string, Profession: string, Sex: string, State: string, Stream: string]
a =spark.read.json("path\\sample.json")
a.show()This will read all the JSON files in a format and a data frame is made out of the JSON format which can be further used for analysis purposes.
Screenshot:
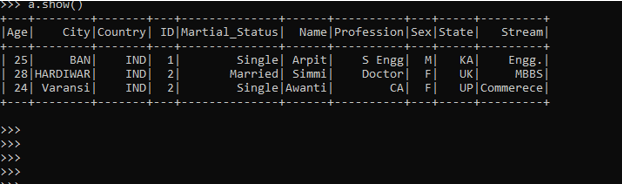
The option spark.read.json(path/*.json) will read all the JSON elements files from a directory and the data frame is made out of it. If the same elements are there the data can be clubbed together and a new column will be added if the column values are changed.
Changing the ID to IDA new column addition.
a.show()Screenshot:
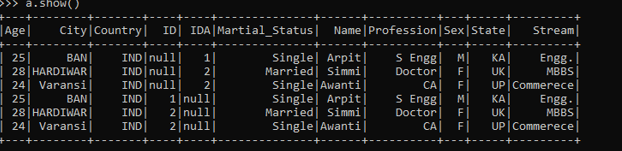
Same column value multiple JSON Files.
Screenshot:
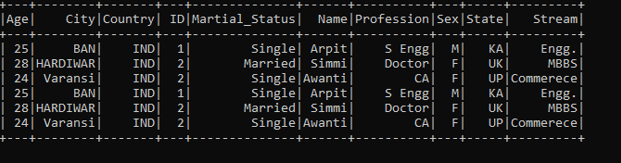
These are some of the Examples of PYSPARK Read JSON function in PySpark.
Note:
1. It is used to read JSON file format into Spark environment.
2. It is automatically infers the schema of JSON.
3. It can read multiple JSON lines of Files.
4. It can read files from a directory also and converts these files into a data frame.
Conclusion
From the above article, we saw the working of READ JSON in PySpark. From various examples and classification, we tried to understand how this READ JSON FUNCTION is used in PySpark and what are is used at the programming level. The various methods used showed how it eases the pattern for data analysis and a cost-efficient model for the same. We also saw the internal working and the advantages of READ JSON in PySpark Data Frame and its usage for various programming purposes. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
We hope that this EDUCBA information on “PySpark Read JSON” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

