Updated April 1, 2023

Introduction to PySpark Median
PySpark Median is an operation in PySpark that is used to calculate the median of the columns in the data frame. The median is an operation that averages the value and generates the result for that. The Median operation is a useful data analytics method that can be used over the columns in the data frame of PySpark, and the median can be calculated from the same. Its function is a way that calculates the median, and then post calculation of median can be used for data analysis process in PySpark. The median has the middle elements for a group of columns or lists in the columns that can be easily used as a border for further data analytics operation. Median is a costly operation in PySpark as it requires a full shuffle of data over the data frame, and grouping of data is important in it.
Syntax of PySpark Median
Given below is the syntax mentioned:
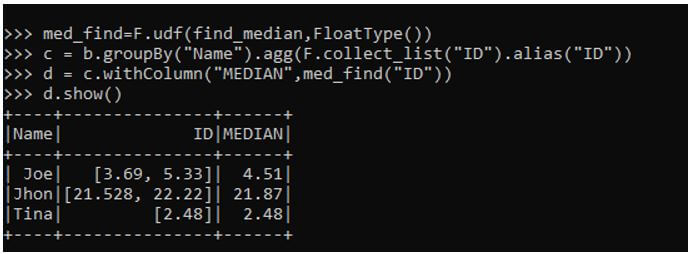
med_find=F.udf(find_median,FloatType())
c = b.groupBy("Name").agg(F.collect_list("ID").alias("ID"))
d = c.withColumn("MEDIAN",med_find("ID"))
d.show()- Med_find: The function to register the find_median function.
- C: The new data frame using the groupBy function and aggregating the data.
- D: The column whose Median Needs to be find out.
Output:
Working of Median PySpark
- The median operation is used to calculate the middle value of the values associated with the row. The median operation takes a set value from the column as input, and the output is further generated and returned as a result.
- We can define our own UDF in PySpark, and then we can use the python library np. The numpy has the method that calculates the median of a data frame. The data frame column is first grouped by based on a column value and post grouping the column whose median needs to be calculated in collected as a list of Array. This makes the iteration operation easier, and the value can be then passed on to the function that can be user made to calculate the median.
- It is a costly operation as it requires the grouping of data based on some columns and then posts; it requires the computation of the median of the given column. The data shuffling is more during the computation of the median for a given data frame. We can use the collect list method of function to collect the data in the list of a column whose median needs to be computed.
Example of PySpark Median
Given below are the example of PySpark Median:
Let’s start by creating simple data in PySpark.
Code:
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]A sample data is created with Name, ID and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Output:

Let us try to find the median of a column of this PySpark Data frame.
Code:
import pyspark.sql.functions as F
import numpy as np
from pyspark.sql.types import FloatTypeThese are the imports needed for defining the function.
Let us start by defining a function in Python Find_Median that is used to find the median for the list of values.
The np.median() is a method of numpy in Python that gives up the median of the value.
Code:
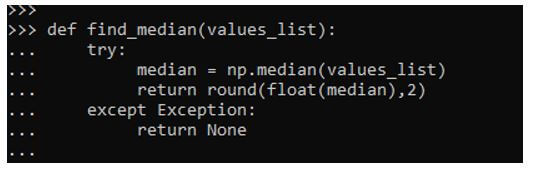
def find_median(values_list):
try:
median = np.median(values_list)
return round(float(median),2)
except Exception:
return NoneThis returns the median round up to 2 decimal places for the column, which we need to do that. We have handled the exception using the try-except block that handles the exception in case of any if it happens.
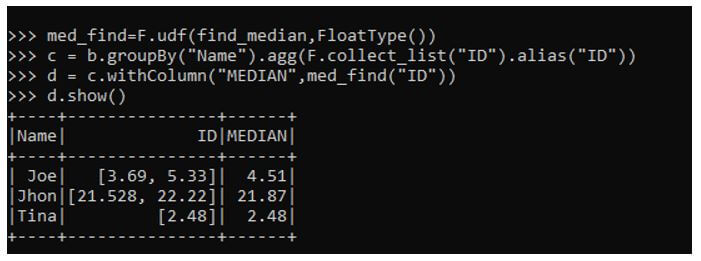
med_find=F.udf(find_median,FloatType())This registers the UDF and the data type needed for this. Here we are using the type as FloatType().
Let us try to groupBy over a column and aggregate the column whose median needs to be counted on.
c = b.groupBy("Name").agg(F.collect_list("ID").alias("ID"))This alias aggregates the column and creates an array of the columns.
d = c.withColumn("MEDIAN",med_find("ID"))
d.show()This introduces a new column with the column value median passed over there, calculating the median of the data frame.
Output:
Important Points to Remember
- It can be used to find the median of the column in the PySpark data frame.
- It is an operation that can be used for analytical purposes by calculating the median of the columns.
- It can be used with groups by grouping up the columns in the PySpark data frame.
- It is an expensive operation that shuffles up the data calculating the median.
- It can also be calculated by the approxQuantile method in PySpark.
Conclusion
From the above article, we saw the working of Median in PySpark. Then, from various examples and classification, we tried to understand how this Median operation happens in PySpark columns and what are its uses at the programming level. We also saw the internal working and the advantages of Median in PySpark Data Frame and its usage in various programming purposes. Also, the syntax and examples helped us to understand much precisely over the function.
Recommended Articles
This is a guide to PySpark Median. Here we discuss the introduction, working of median PySpark and the example, respectively. You may also have a look at the following articles to learn more –

