Updated May 3, 2023

Overview of PostgreSQL DISTINCT
We can remove the duplicate rows from a statement’s result set using a PostgreSQL DISTINCT clause in the SELECT statement. The PostgreSQL DISTINCT clause keeps only one row for all groups of duplicate rows. PostgreSQL DISTINCT removes all duplicate rows and maintains only one row for a group of duplicate rows. We can use the PostgreSQL DISTINCT clause on multiple columns of a table.
How to Use DISTINCT in PostgreSQL?
Let’s understand the DISTINCT clause syntax as follows:
Syntax #1
SELECT
DISTINCT column_name1
FROM
table_name;Explanation: We use the values from the column_name1 column to evaluate the duplicate rows.
Syntax #2
The PostgreSQL DISTINCT clause evaluates the combination of all defined columns’ different values to evaluate the duplicate rows if we have specified the DISTINCT clause with multiple column names.
SELECT
DISTINCT column_name1, column_name2
FROM
table_name;Explanation: In the above statement, the values of column_name1 and column_name2 are combined to evaluate the duplicate rows.
Syntax #3
We can use the PostgreSQL DISTINCT ON clause or expression to maintain the “first” row for a group of duplicates from the result set using the following syntax:
SELECT
DISTINCT ON (column_name1) column_name_alias,
column_name2
FROM
table_name
ORDER BY
column_name1,
column_name2;Explanation: The SELECT statement returns the randomly ordered rows; hence the firstmost row of every resulting group is also random. We can use the DISTINCT ON clause and the ORDER BY clause to make the resulting set obvious.
Examples of PostgreSQL DISTINCT
We will create a table of the name ColorProperties. Also, add some data into the ColorProperties table to understand the DISTINCT clause.
Use the following statement to create the ColorProperties table, which consists of three columns:
- color_id,
- back_color and
- fore_color.
Code:
CREATE TABLE ColorProperties (
color_id serial NOT NULL PRIMARY KEY,
back_color VARCHAR,
fore_color VARCHAR
);- We will insert some rows into the ColorProperties table with the help of the INSERT statement as follows:
Code:
INSERT INTO ColorProperties (back_color, fore_color)
VALUES
('blue', 'red'),
('green', 'blue'),
('red', 'red'),
('blue', 'green'),
('green', 'red'),
('blue', 'blue'),
('green', 'green'),
('red', 'red'),
('red', NULL),
(NULL, 'red'),
('red', 'green'),
('red', 'blue');- Now retrieve the data from the ColorProperties table with the help of the SELECT statement as follows:
Code:
SELECT
color_id,
back_color,
fore_color
FROM
ColorProperties;<c/doe>Output: After executing the above statement, we will follow the result.
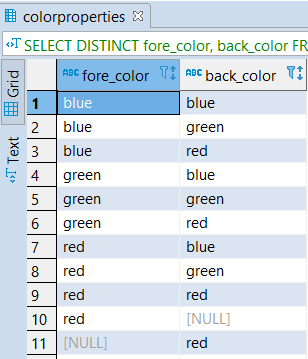
1. Single One Column
We will use the following statement to fetch the unique values of the column named fore_color. Also, to sort output results alphabetically, we will use the ORDER BY clause for the values in the fore_color column.
Code:
SELECT
DISTINCT fore_color
FROM
ColorProperties
ORDER BY
fore_color;Output:
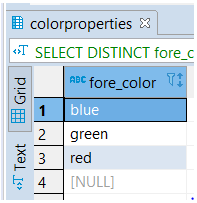
2. Multiple Columns
Let’s understand how to use the DISTINCT clause on multiple columns using the following statement:
Code:
SELECT
DISTINCT fore_color,
back_color
FROM
ColorProperties
ORDER BY
fore_color,
Back_color;Output:
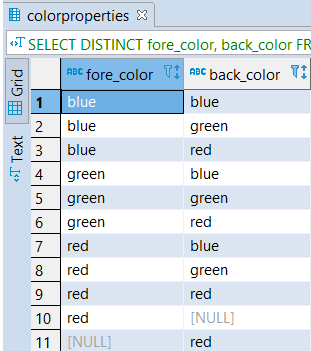
- As the SELECT DISTINCT clause contains back_color and fore_color, for removing the result’s duplicate rows, set the PostgreSQL combines values of both columns back_color and fore_color, etc.
- The PostgreSQL statement will give us the unique values for both columns, back_color, and fore_color, from the ColorProperties table. RED COLOR is present in both columns, back_color, and fore_color, in the ColorProperties table as we added back_color and fore_color with the DISTINCT clause, only one-row entry was kept for duplicate rows.
3. PostgreSQL with DISTINCT ON
We should define the statement to get the sorted result set: remove all duplicate rows and keep a one-row entry for all.
Code:
SELECT
DISTINCT ON
(back_color) backgroundcolor,
fore_color
FROM
ColorProperties
ORDER BY
back_color,
fore_color;Output:
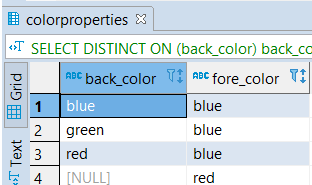
4. Multiple Tables
Let’s consider we have two tables named: students and departments.
CREATE TABLE students (
name text not null,
department_id text not null,
CONSTRAINT students_pk PRIMARY KEY (name)
);
INSERT INTO students (name, department_id) VALUES
('Jacob', '101'),
('David', '102'),
('John', '103');
CREATE TABLE departments (
department_id text not null,
department_name text not null
);
INSERT INTO departments (department_id, department_name) VALUES
('101', 'Computer'),
('102', 'Electrical'),
('103', 'Mechanical');Let’s look at the following statement, which joins student and department tables.
Code:
SELECT DISTINCT ON (s.department_id) s.department_id, s.name, d.department_name
FROM students s
JOIN departments d ON d.department_id = s.department_id
ORDER BY s.department_id DESC- We have defined an expression (s.department_id) for a DISTINCT ON clause to ORDER the result set in the above statement.
Output:

Conclusion
We hope from the above article, you have understood how to use PostgreSQL SELECT DISTINCT statement to return unique rows by removing duplicate rows from the result set.
Recommended Articles
We hope that this EDUCBA information on “PostgreSQL DISTINCT” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
