Updated May 18, 2023

Definition of PostgreSQL Clustered Index
PostgreSQL provides clustered index functionality to the user in which every table of the database has a unique clustered index. Clustered index means it stores another value of a table on secondary storage. Clustered index is used to identify rows from a table uniquely. When we talk about clustered indexes containing groups of similar items or properties that are clustering, we can say properties. By default column name and primary key of the table have a clustered index. In PostgreSQL, clustered attributes store the metadata of the corresponding index rather than the relation. Clustering index has one to one relation in postgreSQL.
Syntax:
Clustered schema name using index name;Explanation:
In the above syntax, schema name means table name that we need to cluster, which means the content of the table physically reorders based on the indexing. Clustering is a one-time operation, meaning clustering changes are not allowed. Index name means index name. VERBOSE is used to print progress reports of database tables clustered.
How to Use a Clustered Index in PostgreSQL?
We must install PostgreSQL in your system. Required basic knowledge about PostgreSQL. We must require a database table to create clustering indexing. Basic understanding of clustered indexing, i.e., how it functions, is necessary. We can perform different operations on database tables with the help of psql and pgAdmin.
Let’s see a different example of a clustered index to understand better as follows.
Example #1
For the implementation of the clustered index, first, we need to create a table with primary, so let’s create a table by using the following statement.
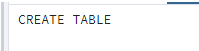
CREATE TABLE test(ID INT PRIMARY KEY NOT NULL, Name TEXT NOT NULL, Age INT NOT NULL, Address CHAR(50), Salary REAL);Explanation
In the above example, we created a test table with different attributes such as employee ID, Name, Age, Address, and Salary with different data types and sizes. Illustrate the end result of the above declaration by using the following snapshot.
Now insert a record into the table by using the following insert into a statement as follows.
INSERT INTO test (ID,Name,Age,Address,Salary)
VALUES (3, 'Sam', 21, 'California', 40000.00),
(1, 'Karan', 25, 'Londan', 25000.00),
(4, 'Jenny', 30, 'Dubai', 31000.00),
(2, 'Jon', 28, 'Mumbai', 28000.00);Explanation
In the above example, we inserted 4 rows into the table with a random order, as shown in the above statement. After that, when we execute the select statement, it is shown in ascending order which means every table has a by default indexing, and it physically reorders the data into the database table. Illustrate the end result of the above declaration by using the following snapshot.

Now let’s see how we can implement a clustered index as follows.
Example #2
CREATE UNIQUE INDEX "test_Age_Salary"
ON public.test USING btree
(age ASC NULLS LAST, salary ASC NULLS LAST)
WITH (FILLFACTOR=10)
TABLESPACE pg_default;Explanation
With the help of the above statement, first, we created an index for two columns such as Age and Salary, and we arrange them in ascending order as shown in the above statement. After that, we use the alter command as follows.
ALTER TABLE public.test
CLUSTER ON "test_Age_Salary";Explanation
In the above statement, we use the alter command to implement a cluster index in PostgreSQL. Here we use the public. test to access table names, and we created a clustered index on the Age and Salary column of the test database table. Illustrate the end result of the above declaration by using the following snapshot.
![]()
So we created a clustered index by using the above two statements, and we want to see clustered table details, so we use the following syntax as follows.
Syntax:
\d table_name;Explanation
In the above statement, we \d means describe table command with the table name, and it is used to show all detailed structure of the table like the primary key of the table, clustering of the table, and data type of column or we can say that size that means it shows all detail structure of the table.
Notes
- When you create a database table with a primary key or any other index, then you can execute cluster commands by specifying the index name to get the physical order of the database.
- PostgreSQL cluster is used to specify table names based on the index name, and the index must be already defined on the table.
- The clustering index shows the physical ordering of data as per the clustered index of the table.
- We can update the table as per our requirement, but changes are not allowed in clustered because clustering is a one-time operation. That means clustering is not storing any new or updated rows.
- As per our requirement, we can recluster the table by using the cluster command.
- For the execution of cluster commands, we required access to the
- When we execute a cluster command, it creates a temporary copy of the table, so we need free space for that.
Uses
- The main purpose of clustering is to rearrange the database table based on a specific index. It involves sorting the table according to that index to improve query performance.
- When creating a cluster, it creates a temporary file on another disk location. This temporary file preserves the original content of the table even after executing an update command on the table.
- We use a clustered index to reorder data within tables.
- In clustering, when we insert a new record into the table, then it automatically inserts at the end of the table.
- Clustering indexes make faster queries to access data from the tables.
- Cluster indexes are unique indexes, as per the table.
- We utilize clustering based on our requirements to enhance database performance. By leveraging the cluster index, we can increase the speed of the database.
Conclusion
We hope you understand the PostgreSQL Clustered Index from this article. From the above article, we have learned the basic syntax of the Clustered Index. We have also learned how we can implement them in PostgreSQL with the examples of the Clustered Index. Clustering physically reorders data within a database table. From this article, we have learned how we can handle the Clustered Index in PostgreSQL.
Recommended Articles
We hope that this EDUCBA information on the “PostgreSQL Clustered Index” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
