Updated March 28, 2023

Introduction To Normal Forms in DBMS
Database is a storage for the structured collection of data. These data can be accessed and manipulated across various locations within the database. The wide range of storage leads to the problem of data redundancy wherein a piece of the same data information is stored or replicated in multiple locations within the database. Database with redundancy is at a disadvantage w.r.t to its storage, consistency and data manipulation. One of the techniques used to eliminate the issues of data redundancy within a given database is Normalization.
Normalization in DBMS is the process of effectively organizing data into multiple relational tables to minimize data redundancy.
What are Normal Forms in DBMS?
Before understanding the normal forms it is necessary to understand Functional dependency.
A functional dependency defines the relationship between two attributes, typically between a prime attribute (primary key) and non-prime attributes. If for a table X containing attributes A and B, among which the attribute A is a primary key then the functional dependency is defined as:

Example for Functional Dependency:

Explanation: Emp_Name, Contact, and Address depends on Emp_ID, i.e. given an Emp_ID we can get the information on the employee details corresponding to the emp_id.
Example to Implement Normal Forms in DBMS
Now that the definition of Functional Dependency is covered, Let’s look into the draw backs of data redundancy and more concerning issues or rather anomalies w.r.t Insertion, Deletion, and Updating data.
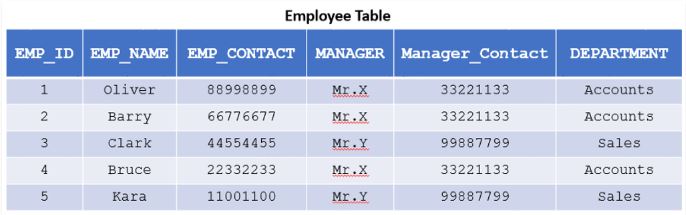
1. Insertion Anomaly
Caused by updating the same set of repeated information again and again. This becomes a problem as the entries for a table increases with time.
Example: for the table in Img1, if a new employee must be added to the table, then the corresponding information of the manager and manager’s information must be repeated leading to the insertion anomaly which will increase with the increase in the entries to the Employee table.
2. Deletion Anomaly
It causes loss of data within the database due to its removal in some other related data set.
Example: for the table in Img1, if the information of Manager, Mr.X is deleted, then this leads to the deletion of the information corresponding to the employees associated with Mr.X leading to loss of employee information for the deleted employee details.
3. Updating Anomaly
In case of an update, it’s very crucial to make sure that the given update happens for all the rows associated with the change. Even if a single row gets missed out it will lead to inconsistency of data.
Example: for the table in Img1, if the manager Mr.X’s name has to be updated, the update operation must be applied to all the rows that Mr.X is associated with. Missing out even a single row causes inconsistency of data within the database
The above-mentioned anomalies occur because inadvertently we are storing two or more pieces of information in every row of a table. To avoid this, Data Normalization comes to the rescue. Data Normalization ensures data dependency makes sense.

For the normalization process to happen it is important to make sure that the data type of each data throughout an attribute is the same and there is no mix up within the data types. For example, an attribute ‘Date-of-Birth’ must contain data only with ‘date’ data type. Let’s dive into the most trivial types of Normal Forms.
Types of Normal Forms
Below are the types to explain the Normal Forms:
1st Normal Form (1NF)
It is Step 1 in the Normalization procedure and is considered as the most basic prerequisite to get started with the data tables in the database. If a table in a database is not capable of forming a 1NF, then the database design is considered to be poor. 1NF proposes a scalable table design that can be extended easily in order to make the data retrieval process much simpler.
For a table in its 1NF,
- Data Atomicity is maintained. The data present in each attribute of a table cannot contain more than one value.
- For each set of related data, a table is created and data set value in each is identified by a primary key applicable to the data set.
Example:
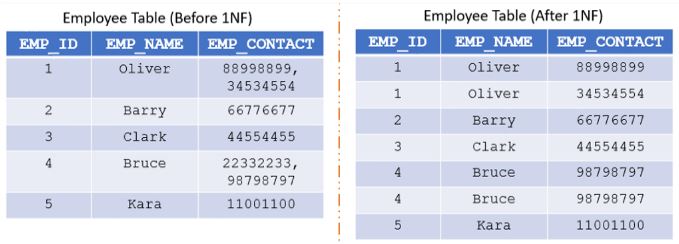
The multiple values from EMP_CONTACt made atomic based on the EMP_ID to satisfy the 1NF rules.
2nd Normal Form (2NF)
The basic prerequisite for 2NF is:
- The table should be in its 1NF,
- The table should not have any partial dependencies
Partial Dependency: It is a type of functional dependency that occurs when non-prime attributes are partially dependent on part of Candidate keys.
Example:
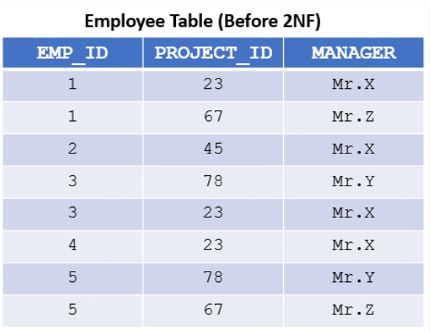
- In the employee table(Img3), if manager details are to be fetched for an employee, multiple results are returned when searched with EMP_ID, in order to fetch one result, EMP_ID and PROJECT_ID together are considered as the Candidate Keys.
- Here the manager depends on PROJECT_ID and not on EMP_ID, this creates a partial dependency.
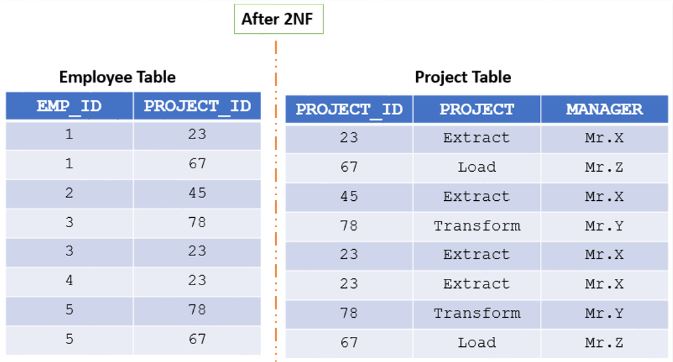
- There are multiple ways to eliminate this partial dependency and reduce the table to its 2nd normal form, one such method is adding the Manager information to the project table as shown in Img5:
3rd Normal Form (3NF)
3NF ensures referential integrity, reduce the duplication of data, reduces data anomaly and makes the data model more informative. The basic prerequisite for 3NF is,
- The table should be in its 2NF, and
- The table should not have any transitive dependencies
Transitive dependency: It occurs due to an indirect relationship within the attributes when a non-prime attribute has a functional dependency on a prime attribute.
Example:
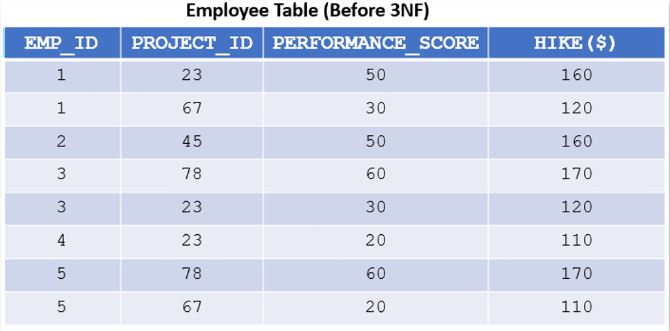
- For the table in Img5, the PERFORMANCE_SCORE depends on both employee and project that he is associated, but the last column HIKE depends on PERFORMANCE_SCORE.
- The hike changes with performance and here the attribute performance score is not a primary key. This forms a transitive dependency
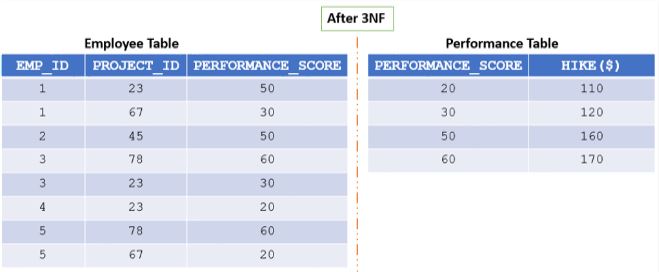
- To eliminate the transitive dependency created, and to satisfy the 3NF, the table is broken as illustrated in Img6
Boyce-Codd Normal Form BCNF or 3.5 NF
BCNF deals with the anomalies that 3 NF fails to address. For a table to be in BCNF, it should satisfy two conditions:
- The table should be in its 3 NF form
- For any dependency, A à B, A should be a super key i.e. A cannot be a non-prime attribute when B is a prime attribute.
Example:
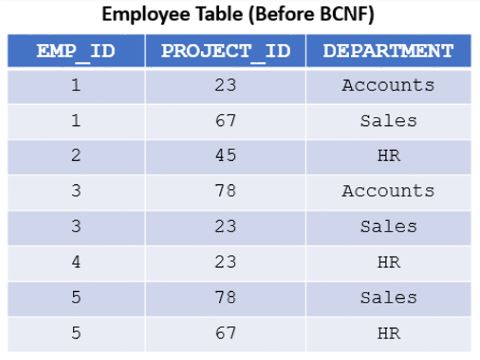
In the table in Img7, the EMP_ID and PROJECT_ID together can fetch the Department details associated with the employee. i.e.
- EMP_ID + PROJECT_ID → DEPARTMENT
- (Candidate keys)
- DEPARTMENT which is not a super key is dependent only on PROJECT_ID but not dependent on EMP_ID
- Department → Project_ID
- (Non-prime attribute) (prime attribute)
To make this table satisfy BCNF, we need to break the table as shown in Img8
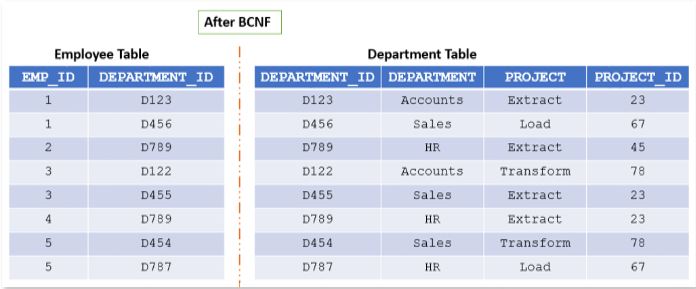
Here the department table is created such that each department id is unique to the department and project associated with it.
Conclusion
It is very crucial to ensure that the data stored in the database is meaningful and the chances of anomalies are minimal to zero. Normalization helps in reducing the data redundancy and help make the data more meaningful. Normalization follows the principle of ‘Divide and Rule’ wherein the tables are divided until a point where the data present in it makes actual sense. It is also important to note that normalization does not fully eliminate the data redundancy but rather its goal is to minimize the data redundancy and the problems associated with it.
Recommended Articles
This is a guide to Normal Forms in DBMS. Here we discuss an introduction, what is Normal Forms in DBMS, with an example to implement and types of in detail explanation. You can also go through our other related articles to learn more –
